Rust 从零到生产 简体中文版
本书为 《Zero to Production in Rust》的非官方翻译
欢迎贡献: cubewhy/zero2prod-zhcn
边学边翻译的, 可能有点慢/不准确...
只是自用翻译, 很多地方有个人成分... 如果有出错的地方请开issue告诉我哦
有的注解是我自己写的, 原作的话那些部分是不存在的
使用谷歌翻译+人工校对翻译
翻译版本的代码使用 Rust 2024, 过时代码已迁移到可用写法
序言
前言
当你读到这些文字时,Rust 已经实现了它最大的目标:向程序员们提供机会,让他们用另一种语言编写他们的生产系统。读完本书后,你仍然可以选择是否采用这种方式,但你已经具备了考虑这个机会所需的一切。我参与了两种截然不同的语言:Ruby 和 Rust 的成长历程——不仅参与编程,还举办活动、参与项目管理,并围绕它们开展业务。通过这些,我有幸与许多语言的创造者保持联系,并将其中一些人视为朋友。Rust 是我一生中唯一一次见证并帮助一门语言从实验阶段发展到被业界广泛接受的机会。
我要告诉你一个我一路走来学到的秘密:编程语言的采用并非因为功能清单。这是一个复杂的相互作用,它需要优秀的技术、谈论它的能力,以及找到足够多愿意长期投资的人。当我写下这些文字时,已有超过 5000 人利用业余时间为 Rust 项目做出了贡献,而且通常是免费的——因为他们相信这份赌注。
但你不必为编译器做出贡献,也不必被记录在 git log 中才能为 Rust 做出贡献。
Luca 的书就是这样一份贡献:它为新人提供了一个了解 Rust 的视角,并推广了众多优秀人士的优秀工作。
Rust 从未打算成为一个研究平台——它始终是一门编程语言,
用于解决大型代码库中实际存在的、切实可行的问题。毫不奇怪,它出自一个维护着庞大而复杂代码库的组织——Mozilla,Firefox 的创建者。我加入 Rust 时, 只是怀揣着雄心壮志——但这个雄心壮志是将研究成果产业化,让未来的软件变得更好。凭借其丰富的理论概念、线性类型、基于区域的内存管理,这门编程语言始终面向所有人。
这反映在其术语中:Rust 使用像“所有权”和“借用”这样通俗易懂的名称来指代我刚才提到的概念。Rust 是一门彻头彻尾的工业语言。
这也反映在其支持者身上:我认识 Luca 多年,他是 Rust 社区的成员,对 Rust 了如指掌。但他更深层次的兴趣在于通过满足人们的需求,让他们相信 Rust 值得一试。本书的标题和结构体现了 Rust 的核心价值之一: 在编写可靠且有效的生产软件中发现它的价值。
Rust 的优势在于,它倾注了人们的精力和知识,从而高效地编写出稳定的软件。这种体验最好通过指南来获得,而 Luca 就是你能找到的关于 Rust 的最佳指南之一。
Rust 并不能解决你所有的问题,但它努力消除各种错误。有一种观点认为,语言中的安全特性是因为程序员的无能。我不认同这种观点。 Emily Dunham 在 2017 年 RustConf 主题演讲中完美诠释了这一点:“安全代码让你能够更好地承担风险”。Rust 社区的魅力很大程度上在于其对用户的积极看法:无论你是新手还是经验丰富的开发者,我们都信任你的经验和决策。在这本书中,Luca 提供了许多即使在 Rust 之外也能应用的新知识,并在日常软件实践中进行了详尽的解释。祝你阅读、学习和思考愉快。
Florian Gilcher,
Ferrous Systems 管理总监兼
Rust 基金会联合创始人
本书讲述了什么
后端开发领域广阔无垠。
你所处的环境对解决当前问题的最佳工具和实践有着巨大的影响。
例如,基于主干的开发方式非常适合编写在云环境中持续部署的软件。 同样的方法可能不太适合销售由客户托管和运行的软件的团队的业务模式和面临的挑战——他们更有可能从 Gitflow 方法中受益。 如果你是独自工作,可以直接推送到主干。 在软件开发领域,很少有绝对的事物,我认为在评估任何技术或方法的优缺点时,阐明你的观点是有益的。
“从零到生产”将重点关注由四到五名经验和熟练程度各异的工程师组成的团队编写云原生应用程序所面临的挑战。
云原生应用程序
定义 云原生应用 本身就足以写一本新书了[1]。与其规定云原生应用应该是什么样子,不如明确规定它们应该做什么。 借用 Cornelia Davis 的话来说,我们期望云原生应用:
- 在易发生故障的环境中运行时实现高可用性
- 在发布新版本的时候实现零停机
- 处理动态工作负载(workload)
这些要求对我们软件架构的可行解决方案空间有着深远的影响。
高可用性意味着,即使我们的一台或多台机器突然出现故障(云环境中的常见情况[2]),我们的应用程序也应该能够在不停机的情况下处理请求。
这迫使我们的应用程序必须分布式运行——应该在多台机器上运行多个实例。
如果我们想要处理动态工作负载,情况也是如此——我们应该能够衡量系统是否负载过重,并通过启动新的应用程序实例来投入更多计算资源来解决问题。这还要求我们的基础设施具有弹性,以避免过度配置及其相关成本。
运行复制应用程序会影响我们的数据持久化方法——我们将避免使用本地文件系统作为主存储解决方案,而是依靠数据库来满足我们的持久化需求。
因此, 《从零到生产》将广泛涵盖那些看似与纯后端应用程序开发无关的主题。但云原生软件的核心在于彩虹 (Rainbow [3]) 和 DevOps,我们将花费大量时间讨论传统上与操作系统技术相关的主题。
我们将介绍如何对 Rust 应用程序进行检测,以收集日志、跟踪和指标,以便能够观察我们的系统。
我们将介绍如何通过迁移设置和改进数据库架构。
我们将涵盖使用 Rust 解决云原生 API 第一天和第二天问题所需的所有材料。
- [1]: 就像 Cornelia Davis 的优秀云原生模式一样!
- [2]: 例如,许多公司在 AWS Spot 实例上运行软件,以降低基础设施成本。Spot 实例的价格是通过持续竞价确定的,可能比按需实例的全价便宜得多(最高可便宜 90%!)。但有一个问题:AWS 可以随时停用您的 Spot 实例。您的软件必须具备容错能力才能利用这一机会。
- [3]: 源书并没有这个注解, 关于什么是彩虹部署可以参考这个
和团队一起工作
这三个需求的影响超越了我们系统的技术特性:它影响着我们构建软件的方式。
为了能够快速向用户发布应用程序的新版本,我们需要确保我们的应用程序能够正常运行。
如果您正在独立开发一个项目,您可以依赖您对整个系统的透彻理解:您亲子编写了它,它可能很小,但是你随时可以回想起它的细节。[3] 如果您在团队中开发一个商业项目,您经常会遇到一些代码,这些代码既不是您编写的,也不是您审核的。原作者可能已经不在了。
如果您依赖于对代码功能的全面理解来防止代码崩溃,那么每次要引入更改时,您最终都会被恐惧所麻痹。(译者注: 俗称不敢动代码)
您需要写自动化测试。
在每次提交时自动运行。在每个分支上运行。保持 main 分支健康。
您需要利用类型系统使不良状态难以或无法表示。
您希望使用您掌握的所有工具,赋能团队中的每一位成员,让他们能够开发该软件。
即使他们可能不如您经验丰富,或者对代码库或您正在使用的技术不那么熟悉,他们也能全力投入开发过程。
因此,“从零到生产”项目从一开始就将重点放在测试驱动开发和持续集成上——我们甚至在启动和运行 Web 服务器之前就会设置 CI 流水线!
我们将介绍 API 的黑盒(black-box)测试和 HTTP mocking 等技术——这些技术在 Rust 社区中并不流行,文档也并不完善,但却非常强大。
我们还将借鉴领域驱动设计领域 (Domain Driven Design)的术语和技术,并将它们与类型驱动设计 (type-driven design)相结合,以确保系统的正确性。
我们的主要关注点是企业软件:写足以对领域进行建模的代码,并且支持长期演化。 (注: 就是说为未来考虑, 追求可维护性)
因此,我们会偏向于那些枯燥无味且正确的解决方案,即使它们会带来性能开销,而这些开销可以通过更谨慎、更精妙的方法进行优化。 先让它运行起来,然后再进行优化(如果需要)。
本书适合谁阅读
Rust 生态系统一直致力于通过面向初学者和新手的精彩资料打破采用障碍,从文档到编译器诊断的持续完善,我们付出了不懈的努力。 服务尽可能多的受众是有价值的。
同时,试图总是面向所有人讲解可能会产生有害的副作用:一些资料 可能与中级和高级用户相关,但对于初学者来说却太过繁琐和仓促, 最终会被忽视。
当我开始尝试使用 async/await 时,我亲身经历了这个问题。
我所需的高效知识与我通过阅读《Rust 之书》或在 Rust 数值生态系统中工作所积累的知识之间存在巨大差距。我想得到一个直截了当的问题的答案:
- Rust 能成为一种高效的 API 开发语言吗?
答案是肯定的。
但弄清楚如何操作可能需要一些时间。 这就是我写这本书的原因。 我写这本书是为了那些读过《The Rust Book》并正在尝试移植一些简单系统的经验丰富的后端开发人员。
我写这本书是为了我团队的新工程师,帮助他们理解未来几周和几个月将要贡献的代码库。
我写这本书是为了一个利基市场,我认为目前 Rust 生态系统中的文章和资源无法满足他们的需求。
一年前,我为自己写了这本书。
分享在学习过程中获得的知识:如果你在 2022 年使用 Rust 进行后端开发,你的工具箱是什么样的?有哪些设计模式?有哪些陷阱?
如果你不符合这个描述,但正在努力实现它,我会尽力帮助你:虽然我们不会直接涵盖很多内容(例如大多数 Rust 语言特性),但我会尽量在需要的地方提供参考资料和链接,帮助你在学习过程中掌握/理解这些概念。
让我们开始吧
入门
安装Rust工具链
在您的系统上安装 Rust 的方法有很多种,但我们将重点介绍推荐的途径:通过 rustup。
有关如何安装 rustup 的说明,请访问 rustup.rs
rustup 不仅仅是一个 Rust 安装程序——它的是一个工具链管理工具
工具链是编译目标和发布渠道的组合。
编译目标
Rust 编译器的主要目的是将 Rust 代码转换为机器码——一组 CPU 和操作系统能够理解和执行的指令。
因此,您需要为每个编译目标(即您想要生成可运行可执行文件的每个平台(例如 64 位 Linux 或 64 位 OSX))配备不同的 Rust 编译器后端。
Rust 项目致力于支持各种编译目标,并提供不同级别的保证。目标分为不同等级,从“保证可用”的 Tier 1 到“尽力而为”的 Tier 3。
您可以在此处找到详尽的最新列表。
发布频道
Rust 编译器本身是一个动态的软件:它随着数百名志愿者的日常贡献而不断发展和改进。
Rust 项目追求稳定,而非停滞不前。以下是 Rust 文档 中的一段话:
您无需担心升级到新版 Rust 的稳定版本。每次升级都应轻松无痛,同时还能带来新功能、更少的 Bug 和更快的编译时间。
因此,对于应用程序开发,您通常应该依赖编译器的最新发布版本来运行、构建和测试您的软件——即所谓的稳定版本。
编译器每六周就会在稳定版本上发布一个新版本 ──本文撰写时的最新版本是 v1.43.1。
另外两个发布频道是
- beta - 下一版本的候选版本
- nightly - 每个晚上自动从 rust-lang/rust 自动构建, 这也是nightly名字的由来
使用 Beta 编译器测试软件是支持 Rust 项目的众多方法之一 —— 它有助于在发布日期之前发现错误。
Nightly 编译器则有不同的用途:它让早期采用者在未完成的功能7发布之前(甚至在稳定之前!)能够使用它们。
如果您计划在 Nightly 编译器上运行生产软件,我建议您三思:它被称为不稳定是有原因的。
我们需要什么工具链
安装 rustup 将为您提供最新的稳定编译器,并以您的主机平台作为目标平台。stable 是本书中用于构建、测试和运行代码的发布渠道。
您可以使用 rustup update 更新您的工具链,而 rustup toolchain list 则会为您提供系统上已安装内容的概览。
我们不需要(或执行)任何交叉编译——我们的生产工作负载将在容器中运行,因此我们不需要从开发机器交叉编译到生产环境中使用的目标平台
初始化我们的项目
通过 rustup 安装的工具链会将各种组件捆绑在一起。 其中之一就是 Rust 编译器 rustc。您可以使用以下命令进行检查:
rustc --version
您无需花费大量时间直接使用 Rustc——您构建和测试 Rust 应用程序的主要界面将是 Rust 的构建工具 Cargo。
您可以使用以下命令再次检查一切是否正常运行
cargo --version
我们接下来用 cargo 创建项目的骨架, 在整本书里, 我们都要在这个项目上工作
cargo new zero2prod
项目文件夹 zero2prod 的结构看起来应该是这样的
zero2prod/
Cargo.toml
.gitignore
.git
src/
main.rs
该项目本身就是一个 Git 仓库,开箱即用。 (cargo 会自动创建git仓库) 如果您计划将项目托管在 GitHub 上,只需创建一个新的空仓库并运行
cd zero2prod
git add .
git commit -am "Project skeleton"
git remote add origin git@github.com:YourGitHubNickName/zero2prod.git
git push -u origin main
鉴于 GitHub 的受欢迎程度以及其最近发布的用于 CI 流水线的 GitHub Actions 功能,我们将以GitHub 为参考,但您可以自由选择任何其他 git 托管解决方案 (或根本不选择任何解决方案)
选择一个集成开发环境 (IDE)
项目框架已准备就绪,现在是时候启动你最喜欢的编辑器,开始摆弄它了。
每个人的偏好各不相同,但我认为,你至少应该拥有一个支持语法高亮、代码导航和代码补全的设置,尤其是在你刚开始学习一门新的编程语言时。
语法高亮可以立即反馈明显的语法错误,而代码导航和代码补全则支持“探索性”编程:你可以快速跳转至依赖项的源代码,快速访问从 crate 导入的结构体或枚举的可用方法,而无需在编辑器和 docs.rs 之间不断切换。
IDE 设置主要有两个选项:rust-analyzer 和 IntelliJ Rust (现在叫做RustRover)
译者注: 当然我本人喜欢用Neovim + rust-analyzer, VS Code看起来也很不错的说
Rust-analyzer
rust-analyzer 是 Rust LSP (Language Server Protocol) 的一个实现。
LSP 使得在各种编辑器中轻松使用 rust-analyzer 变得容易
这意味着你可以在 VS Code、Emacs、Vim/NeoVim 和 Sublime Text 3获得相同的Rust开发体验
特定编辑器的设置说明可在此处找到
IntelliJ Rust/RustRover
IntelliJ Rust 为 JetBrains 开发的编辑器套件提供 Rust 支持。
如果您没有 JetBrains 许可证,可以免费使用支持 In从telliJ Rust 的 IntelliJ IDEA 社区版本
如果您拥有 JetBrains 许可证,那么 CLion 是您首选的 Rust 编辑器。 (译者注: 现在用RustRover的话会更合适的)
我该用哪个IDE
译者注: 本段疑似过时, 现在 rust-analyzer 看起来很稳定, 如果你介意专有软件的话, 建议使用 rust-analyzer + 任何一个支持LSP的编辑器
截至 2022 年 3 月,IntelliJ Rust 应为首选。
尽管 rust-analyzer 前景光明,并且在过去一年中取得了令人难以置信的进步,但它距离提供与 IntelliJ Rust 目前提供的 IDE 体验相当的体验还相去甚远。
另一方面,IntelliJ Rust 会强制您使用 JetBrains 的 IDE,而您可能愿意,也可能不愿意。如果您想继续使用您选择的编辑器,请寻找其 rust-analyzer 集成/插件。
值得一提的是,rust-analyzer 是 Rust 编译器内部正在进行的更大规模库化工作的一部分:rust-analyzer 和 rustc 之间存在重叠,存在大量重复工作。
将编译器的代码库演化为一组可重用的模块,将使 rust-analyzer 能够利用编译器代码库中越来越大的子集,从而释放提供一流 IDE 体验所需的按需分析功能。
这是一个值得未来关注的有趣空间
内部开发循环
在项目开发过程中,我们会反复执行相同的步骤:
- 进行修改
- 编译应用程序
- 运行测试
- 运行应用程序
这也称为内部开发循环。
内部开发循环的速度是单位时间内可以完成的迭代次数的上限。
如果编译和运行应用程序需要 5 分钟,那么每小时最多可以完成 12 次迭代。如果将其缩短到 2 分钟,那么每小时就可以完成 30 次迭代!
Rust 在这方面帮不上忙——编译速度可能会成为大型项目的痛点。在继续下一步之前,让我们看看可以采取哪些措施来缓解这个问题。
让链接 (Linking) 更快点
在考察内部开发循环时,我们主要关注增量编译的性能——在对源代码进行微小更改后,Cargo 需要多长时间来构建二进制文件。
链接阶段 会花费相当多的时间——根据早期编译阶段的输出来组装实际的二进制文件。
默认链接器的性能不错,但根据您使用的操作系统,还有其他更快的替代方案:
- Windows 和Linux上的 lld, LLVM 项目开发的链接器
- MacOS上的 zld
为了加快链接阶段,您必须在计算机上安装备用链接器,并将此配置文件添加到项目中:(别忘了安装链接器!)
# .cargo/config.toml
# On Windows
# ```
# cargo install -f cargo-binutils
# rustup component add llvm-tools-preview
# ```
[target.x86_64-pc-windows-msvc]
rustflags = ["-C", "link-arg=-fuse-ld=lld"]
[target.x86_64-pc-windows-gnu]
rustflags = ["-C", "link-arg=-fuse-ld=lld"]
# On Linux:
# - Ubuntu, `sudo apt-get install lld clang`
# - Arch, `sudo pacman -S lld clang`
[target.x86_64-unknown-linux-gnu]
rustflags = ["-C", "linker=clang", "-C", "link-arg=-fuse-ld=lld"]
# On MacOS, `brew install michaeleisel/zld/zld`
[target.x86_64-apple-darwin]
rustflags = ["-C", "link-arg=-fuse-ld=/usr/local/bin/zld"]
[target.aarch64-apple-darwin]
rustflags = ["-C", "link-arg=-fuse-ld=/usr/local/bin/zld"]
Rust 编译器目前正在努力尽可能使用 lld 作为默认链接器——很快,这种自定义配置将不再是实现更高编译性能的必需品!
cargo-watch
我们还可以通过减少感知编译时间(即您花在终端上等待 cargo check 或 cargo run 完成的时间)来减轻对生产力的影响。
有工具可以帮我们! 我们可以用这个命令来安装 cargo-watch
cargo install cargo-watch
cargo-watch 会监控你的源代码,并在文件每次更改时自动执行命令。例如:
cargo watch -x check
这个命令将在每次源代码发生变化的时候自动运行 cargo check
这会减少你的编译时间
- 您仍在 IDE 中,重新阅读刚刚所做的代码更改
- 与此同时,cargo-watch 已经启动了编译过程
- 切换到终端后,编译器已经运行了一半
cargo-watch 也支持命令链:
cargo watch -x check -x test -x run
- 它会先运行
cargo check - 如果成功,它会启动
cargo test - 如果测试通过,它会使用
cargo run启动应用程序。
我们的内部开发循环,就在这里!
持续集成
工具链已安装。 项目框架已完成。 IDE 已准备就绪。
在我们深入了解构建细节之前,最后要考虑的是我们的 持续集成 (CI) 流水线
在基于主干的开发中,我们应该能够在任何时间点部署主分支。
团队的每个成员都可以从主分支分支开发一个小功能或修复一个错误,然后合并回主分支并发布给用户。
持续集成使团队的每个成员能够每天多次将他们的更改集成到主分支中。
这会产生强大的连锁反应。
有些是显而易见且易于察觉的:它减少了由于长期分支而不得不处理混乱的合并冲突的机会。没有人喜欢合并冲突。
有些则更为微妙:持续集成可以缩短反馈循环。 你不太可能独自开发几天或几周,却发现你选择的方法并未得到团队其他成员的认可,或者无法与项目的其他部分很好地集成。
它迫使你尽早与同事沟通,并在必要时在仍然容易进行(并且不会冒犯任何人)的情况下进行纠正。
我们怎么让这些事情变得可能呢?
我们的 CI 流水线会在每次提交时运行一系列自动化检查。
如果其中一项检查失败,您将无法合并到主代码库 - 就这么简单。
CI 流水线通常不仅仅是确保代码健康:它们还是执行一系列其他重要检查的理想场所 - 例如,扫描依赖关系树以查找已知漏洞、进行 linting、格式化等等。
我们将逐一介绍您可能希望在 Rust 项目的 CI 流水线中运行的各种检查,并逐步介绍相关工具。 然后,我们将为一些主要的 CI 提供商提供一套现成的 CI 流水线。
CI 步骤
测试
如果您的 CI 流水线只有一个步骤,那么它应该是测试。
测试是 Rust 生态系统中的一流概念,您可以利用 cargo 来运行单元测试和集成测试:
cargo test
cargo test 还会在运行测试之前构建项目,因此您无需
事先运行 cargo build (尽管大多数流水线会在运行测试之前调用 cargo build 来缓存依赖项)。
代码覆盖率
关于测量代码覆盖率的利弊,已经有很多文章进行了探讨。
虽然使用代码覆盖率作为质量检查有一些缺点,但我确实认为它是一种快速收集信息并发现代码库中某些部分是否长期被忽视以及 测试是否不足的方法。 测量 Rust 项目代码覆盖率最简单的方法是使用 cargo tarpaulin,这是 xd009642 开发的 cargo 子命令。您可以使用以下命令安装 tarpaulin
# At the time of writing tarpaulin only supports
# x86_64 CPU architectures running Linux.
cargo install cargo-tarpaulin
当运行如下命令的时候, 将计算应用程序代码的代码覆盖率,忽略测试函数。 tarpaulin 可用于将代码覆盖率指标上传到 Codecov 或 Coveralls 等热门服务。
请参阅 tarpaulin 的 README 文件,了解如何上传代码覆盖率指标。
cargo tarpaulin --ignore-tests
代码检查 (Linting)
用任何编程语言编写符合风格的代码都需要时间和练习。
在学习初期,很容易遇到一些可以用更简单方法解决的问题,最终却得到相当复杂的解决方案。
静态分析可以提供帮助:就像编译器单步执行代码以确保其符合语言规则和约束一样,linter 会尝试识别不符合风格的代码、过于复杂的结构以及常见的错误/低效之处。
Rust 团队维护着 Clippy, 官方的 Rust Linter
如果您使用默认配置文件,clippy 会包含在 rustup 安装的组件集中。
CI 环境通常使用 rustup 的最小配置文件,其中不包含 clippy。
但是您可以使用以下命令来安装它
rustup component add clippy
如果你已经安装过 clippy 了, 执行这个命令什么也不会发生
你可以执行如下的命令来为你的项目运行 clippy
cargo clippy
在我们的 CI 管道中,如果 clippy 发出任何警告,我们希望 Linter 检查失败。
我们可以通过以下方式实现:
cargo clippy -- -D warnings
静态分析并非万无一失:有时 clippy 可能会建议一些你认为不正确或不理想的更改。
你可以在受影响的代码块上使用 #[allow(clippy::lint_name)] 属性来关闭特定的警告,
或者在 clippy.toml 中使用一行配置语句,为整个项目禁用干扰性的 lint 检查。
或使用项目级 #![allow(clippy::lint_name)] 宏。
有关可用的 lint 以及如何根据您的特定目的进行调整的详细信息,请参阅 clippy 的 README 文件。
代码格式化
大多数组织对主分支都有不止一道防线:
- 一道是 持续集成 (CI) 流水线检查
- 另一道通常是*拉取请求 (PR) 审查**
关于有价值的 PR 审查流程与枯燥乏味 PR 审查流程的区别,有很多说法——无需在此重新展开争论。
我确信好的 PR 审查不应该关注以下几点:格式上的小瑕疵——例如,"你能在这里加个换行符吗?"、"我觉得那里尾部有个空格!" 等等。
让机器处理格式,而审查人员则专注于架构、测试的完整性、可靠性和可观察性。自动格式化可以消除 PR 审查流程中复杂的干扰。你可能不喜欢这样或那样的格式选择,但彻底消除格式上的繁琐, 值得承受些许不适。
rustfmt 是 Rust 官方的格式化程序。
与 clippy 一样,rustfmt 也包含在 rustup 安装的默认组件中
您可以使用以下命令安装它
rustup component add rustfmt
你可以使用如下命令来为你的整个项目格式化代码
cargo fmt
在我们的 CI 流中,我们将添加格式化步骤
cargo fmt -- --check
如果提交包含未格式化的代码,它将失败,并将差异打印到控制台。
您可以使用配置文件 rustfmt.toml 针对项目调整 rustfmt。详细信息请参阅 rustfmt 的 README 文件。
安全漏洞
cargo 使得利用生态系统中现有的 crate 来解决当前问题变得非常容易。
另一方面,每个 crate 都可能隐藏可利用的漏洞,从而危及软件的安全状况。
Rust 安全代码工作组 (Rust Secure Code working group) 维护着一个 数据库,其中包含 crates.io 上发布的 crate 的最新漏洞报告。
他们还提供了 cargo-audit,这是一个便捷的 cargo 子命令,用于检查项目依赖关系树中是否有任何 crate 存在漏洞。
您可以使用以下命令安装它
cargo install cargo-audit
当你安装之后, 你可以执行如下命令来扫描你的依赖树
cargo audit
我们将在每次提交时运行 cargo-audit,作为 CI 流水线的一部分。
我们还将每天运行它,以随时掌握那些我们目前可能没有积极开发但仍在生产环境中运行的项目依赖项的新漏洞!
开箱即用的 CI 流
授人以鱼,不如授人以渔
希望我教给你的知识足以让你为你的 Rust 项目构建一个可靠的 CI 流水线。
我们也应该坦诚地承认,学习如何使用 CI 提供商所使用的特定配置语言可能需要花费数小时的反复尝试,而且调试过程通常非常痛苦,反馈周期也很长。
因此,我决定编写一套适用于最常用现成配置文件, —— 就是我们刚才描述的那些步骤,可以直接放到你的项目仓库中:
调整现有设置以满足您的特定需求通常比从头开始编写新设置要容易得多
写一个电子邮件新闻程序
我们的驱动示例
前言指出
“从零到生产”将重点关注由四到五名经验和熟练程度各异的工程师组成的团队编写云原生应用程序所面临的挑战。
怎么做? 嗯,那就亲手建造一个吧!
基于问题的学习
选择一个你想解决的问题。
让问题驱动新概念和新技术的引入。
它颠覆了你习惯的层级结构:你正在学习的材料并非因为有人声称它相关,而是因为有助于更接近解决方案。
你学习新技术,并知道何时应该学习它们。
细节决定成败:基于问题的学习路径可能令人愉悦,但人们很容易误判旅程中每一步的挑战程度。
我们驱动的示例需要:
- 足够小,以便我们能够在不偷工减料的情况下在一本书中解决;
- 足够复杂,以便涵盖大型系统中出现的大多数关键主题;
- 足够有趣,以便读者在学习过程中保持兴趣。
我们将采用电子邮件简报的形式——下一节将详细介绍我们计划涵盖的功能
纠正教程
基于问题的学习在互动环境中效果最佳:教师充当引导者,
根据参与者的行为线索和反应提供或多或少的支持。
在网站上出版的书籍无法给我同样的机会。
我非常感谢您对材料的反馈——请联系 contact@lpalmieri.com 或在推特上给我发送私信。
在现阶段,提供反馈是为“从零到生产”做出贡献的切实可行的方式。
我们的Newsletter应该做什么
有数十家公司提供的服务包含或主要围绕管理电子邮件地址列表这一理念。
虽然它们都拥有一些核心功能(例如发送电子邮件),但它们的服务都是针对特定用例量身定制的:面向管理数十万个地址且具有严格安全和合规要求的大公司的产品,与面向运营自有博客或小型在线商店的独立内容创作者的 SaaS 产品,在用户界面、营销策略和定价方面会有很大差异。
现在,我们并没有打造下一个 MailChimp 或 ConvertKit 的野心——它们的范围肯定太广,我们无法在一本书中全部涵盖。此外,一些功能需要反复应用相同的概念和技术——读久了会变得乏味。
如果您愿意在您的博客中添加一个电子邮件订阅页面——我们将尝试构建一个电子邮件通讯服务,以支持您起步所需的一切——不多不少,恰到好处。
捕捉需求: 用户故事
上面的产品简介留有一些解释空间——为了更好地界定我们的服务应该支持哪些内容,我们将利用用户故事。
格式相当简单:
- 作为一名...
- 我想...
- 这样...
用户故事可以帮助我们了解我们为谁构建(作为用户)、他们想要执行的操作(想要执行的操作)以及他们的动机(以便执行操作)。 我们将实现三个用户故事:
- 作为博客访问者, 我想订阅新闻简报, 以便在博客发布新内容时收到电子邮件更新
- 作为博客作者, 我想向所有订阅者发送电子邮件, 以便在发布新内容时通知他们
- 作为订阅者, 我想取消订阅新闻简报, 以便不再接收博客的电子邮件更新。
我们不会添加以下功能
- 管理多份新闻通讯
- 将订阅者细分为多个受众群体
- 跟踪打开率和点击率
如上所述,它相当简陋——尽管如此,足以满足大多数博客作者的需求。
它肯定也能满足我“从零到生产”的需求。
迭代工作
让我们看其中一个用户故事:
作为博客作者, 我想向所有订阅者发送一封电子邮件, 以便在新内容发布时通知他们。
这在实践中意味着什么? 我们需要构建什么?
一旦你开始仔细研究这个问题, 就会出现大量问题——例如, 我们如何确保调用者确实是博客作者? 我们是否需要引入身份验证机制?
我们应该在电子邮件中支持 HTML 格式还是只支持纯文本? 那关于表情符号呢?
我们很容易花费数月时间来实现一个极其完善的电子邮件传递系统, 而甚至连基本的订阅/取消订阅功能都没有。
我们可能成为发送电子邮件领域的佼佼者, 但没有人会使用我们的电子邮件简报服务,因为它无法覆盖整个流程。
我们不会深入研究某个故事, 而是尝试在第一个版本中构建足够多的功能, 以在一定程度上满足所有故事的需求。
然后, 我们会回过头来改进: 为电子邮件发送添加容错和重试功能, 为新订阅者添加确认电子邮件等。
我们将以迭代的方式工作: 每次迭代都需要固定的时间, 并为我们带来略微更好的产品版本, 从而提升用户的体验。
值得强调的是, 我们迭代的是产品功能, 而不是工程质量:每次迭代生成的代码都会经过测试并妥善记录, 即使它只提供了一个微小但功能齐全的功能。
接下来
策略清晰, 我们终于可以开始了:下一章将重点介绍订阅功能。
起步阶段需要完成一些繁重的工作: 选择 Web 框架, 搭建用于管理数据库迁移的基础设施, 搭建应用程序脚手架, 以及设置集成测试。
预计以后会花更多时间与编译器进行结对编程!
注册新用户
- 我们的策略
- 选择一个Web框架
- 我们的第一个Endpoint - 简单的可用性检测
- 我们的第一个集成测试
- 实现我们的第一个集成测试
- 回顾
- 使用HTML表单
- 存储数据: 数据库
- 持久化新订阅者
- 更新我们的测试
- 小结
我们的策略
我们将从头开始一个新项目——我们需要处理大量前期繁重的工作:
- 选择一个 Web 框架并熟悉它;
- 定义我们的测试策略;
- 选择一个 crate 与我们的数据库交互(我们需要将这些电子邮件保存在某个地方!);
- 定义我们希望如何管理数据库模式随时间的变化(也就是迁移);
- 实际编写一些查询。
这项工作非常繁重,如果一头扎进去可能会让人不知所措。
我们将添加一个垫脚石,使整个过程更容易理解:在处理 /subscriptions 之前,我们将实现一个 /health_check 端点。虽然没有业务逻辑,但这是一个很好的机会,让我们熟悉我们的 Web 框架,并了解其所有不同的组成部分。
我们将依靠我们的持续集成流水线来在整个过程中保持控制——如果您尚未设置它,请快速浏览 第一章(或获取一个现成的模板)。
选择一个Web框架
我们应该使用哪个 Web 框架来编写 Rust API?
这部分原本应该讨论当前可用的 Rust Web 框架的优缺点。
但最终篇幅过长,实在没必要在这里写,所以我把它作为一篇衍生文章发布:请参阅 《选择 Rust Web 框架,2020 版》 (英语),深入了解 actix-web、rocket、tide 和 warp
简而言之:截至 2022 年 3 月,actix-web 应该是您在生产环境中使用 Rust API 时的首选 Web 框架——它在过去几年中得到了广泛的使用,拥有庞大而健康的社区,并且运行在 tokio 上,因此最大限度地减少了处理不同异步运行时之间不兼容/互操作的可能性。
因此,它将成为我们从零到生产环境的首选。
尽管如此,tide、rocket和wrap都拥有巨大的潜力,我们最终可能会在2022年晚些时候做出不同的决定——如果你正在使用不同的框架进行“从零到生产”的实践,我很乐意看看你的代码!请给原作者发邮件至 contact@lpalmieri.com
在本章及以后的内容中,我建议您打开几个额外的浏览器标签页:actix-web 的网站、actix-web 的文档和 actix-web 的示例集。
我们的第一个Endpoint - 简单的可用性检测
让我们尝试通过实现一个健康检查端点来开始:当我们收到对 /health_check 的 GET 请求时,我们希望返回一个不带正文的 200 OK 响应。
我们可以使用 /health_check 来验证应用程序是否已启动并准备好接受传入请求。
将它与 pingdom.com 这样的 SaaS 服务结合使用,您可以在 API 出现故障时收到警报——这对于您正在运行的电子邮件简报来说是一个很好的基准。
如果您使用容器编排器 (例如 Kubernetes 或 Nomad)来协调您的应用程序,那么健康检查端点也会非常方便:编排器可以调用 /health_check 来检测 API 是否无响应并触发重启。
编写 Actix-Web
我们的起点是 actix-web 主页上的 Hello World!示例:
use actix_web::{App, HttpRequest, HttpServer, Responder, web};
async fn greet(req: HttpRequest) -> impl Responder {
let name = req.match_info().get("name").unwrap_or("World");
format!("Hello {}!", &name)
}
#[tokio::main]
async fn main() -> std::io::Result<()> {
HttpServer::new(|| {
App::new()
.route("/", web::get().to(greet))
.route("/{name}", web::get().to(greet))
})
.bind("127.0.0.1:8000")?
.run()
.await
}
让我们把示例代码粘贴到 main.rs中
让我们运行 cargo check
error[E0432]: unresolved import `actix_web`
--> src/main.rs:1:5
|
1 | use actix_web::{App, HttpRequest, HttpServer, Responder, web};
| ^^^^^^^^^ use of unresolved module or unlinked crate `actix_web`
|
= help: if you wanted to use a crate named `actix_web`, use `cargo add actix_web` to add it to your `Cargo.toml`
error[E0433]: failed to resolve: use of unresolved module or unlinked crate `tokio`
--> src/main.rs:8:3
|
8 | #[tokio::main]
| ^^^^^ use of unresolved module or unlinked crate `tokio`
Some errors have detailed explanations: E0432, E0433.
For more information about an error, try `rustc --explain E0432`.
等..等等...为什么会这样
我们尚未将 actix-web 和 tokio 添加到依赖项列表中,因此编译器无法解析我们导入的内容。
我们可以手动修复此问题,方法是在 Cargo.toml 中添加
#! Cargo.toml
# [...]
[dependencies]
actix-web = "4"
tokio = { version = "1", features = ["macros", "rt-multi-thread"] }
或许我们可以执行 cargo add actix-web 来快速添加 actix-web 依赖
让我们再次运行 cargo check! 现在应该一切正常了!
让我们尝试运行一下应用程序!
cargo run
在你喜欢的终端尝试一下API吧
curl http://127.0.0.1:8000
太好了! 这可以用!
现在, 你可以按下 Ctrl+C来停止web应用程序
actix-web 应用程序的剖析
现在让我们回过头仔细看看我们刚刚在 main.rs 文件中复制粘贴的内容。
//! src/main.rs
// [...]
#[tokio::main]
async fn main() -> std::io::Result<()> {
HttpServer::new(|| {
App::new()
.route("/", web::get().to(greet))
.route("/{name}", web::get().to(greet))
})
.bind("127.0.0.1:8000")?
.run()
.await
}
服务器 - HttpServer
HttpServer 是支撑我们应用程序的骨干。它负责处理以下事项:
- 应用程序应该在哪里监听传入的请求?TCP socket (例如 127.0.0.1:8000)? Unix 域套接字?
- 我们应该允许的最大并发连接数是多少?单位时间内可以创建多少个新连接?
- 我们应该启用传输层安全性 (TLS) 吗?
- 等等
换句话说,HttpServer 处理所有传输层的问题。
之后会发生什么?当 HttpServer 与我们的 API 客户端建立了新的连接,而我们需要开始处理他们的请求时,它会做什么?
这时,App 就派上用场了!
应用程序 - App
App 是所有应用逻辑的存放地:路由、中间件、请求处理程序等。
App 组件的作用是接收传入的请求并返回响应。
让我们仔细地看一下如下代码片段:
App::new()
.route("/", web::get().to(greet))
.route("/{name}", web::get().to(greet))
App 是builder模式的一个实际示例: new() 为我们提供了一个干净的平台,我们可以使用流畅的 API(即链式调用)一点一点地添加新的行为。
我们将在整本书中根据需要了解 App 的大部分 API 接口: 读完本书后,您应该至少接触过一次它的大多数方法。
端点 - Route
如何向我们的应用添加新的端点?route 方法可能是最简单的方法 ——毕竟,我们已经在 Hello World! 示例中使用过了!
route 方法接受两个参数:
path- 一个字符串,可能为模板(例如/{name}), 用于容纳动态路径route- Route 结构体的实例
Route 将处理程序与一组守卫组合在一起。
守卫指定请求必须满足的条件才能“匹配”并传递给处理程序。从实现的角度来看,守卫是 Guard 特性的实现者:
Guard::check 是奇迹发生的地方。
在我们的代码片段中
.route("/", web::get().to(greet))
"/" 将匹配所有在基本路径后不带任何段的请求,例如 http://localhost:8000/。
web::get() 是 Route::new().guard(guard::Get()) 的快捷方式,也就是说,当且仅当请求的 HTTP 方法是 GET 时,该请求才会传递给处理程序。
您可以想象一下,当一个新请求到来时会发生什么:应用会遍历所有已注册的端点,直到找到一个匹配的端点(路径模板和保护条件都满足),然后将请求对象传递给处理程序。
这并非 100% 准确,但目前来说,这是一个足够好的思维模型。
处理程序应该是什么样的?它的函数签名是什么?
目前我们只有一个示例,greet:
async fn greet(req: HttpRequest) -> impl Responder {
// [...]
}
运行时 - Tokio
我们从整个 HttpServer 深入到 Route。让我们再看一下整个 main 函数:
#[tokio::main]
async fn main() -> std::io::Result<()> {
// [...]
}
#[tokio::main] 有什么用? 当然, 让我们删掉它看看会发生什么!
很不幸的, cargo check 给出了如下的报错
error[E0752]: `main` function is not allowed to be `async`
--> src/main.rs:9:1
|
9 | async fn main() -> std::io::Result<()> {
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ `main` function is not allowed to be `async`
For more information about this error, try `rustc --explain E0752`.
error: could not compile `zero2prod` (bin "zero2prod") due to 1 previous error
我们需要 main 函数是异步的,因为 HttpServer::run 是一个异步方法,但 main 函数(我们二进制文件的入口点)不能是异步函数。为什么呢?
Rust 中的异步编程建立在 Future trait 之上: Future 代表一个可能尚未到达的值。所有 Future 都公开一个 poll 方法,必须调用该方法才能使 Future 继续执行并最终解析出最终值。你可以将 Rust 的 Future 视为惰性的:除非进行轮询,否则无法保证它们会执行完成。与其他语言采用的推送模型相比,这通常被描述为一种拉模型。
Rust 的标准库在设计上不包含异步运行时:你应该将其作为依赖项引入你的项目,在 Cargo.toml 文件的 [dependencies] 下添加一个 crate。这种方法非常灵活:您可以自由地实现自己的运行时,并根据用例的特定需求进行优化(参见 Fuchsia 项目或 bastion 的 Actor 框架)。
这就解释了为什么 main 不能是异步函数:谁负责调用它的 poll 方法?
没有特殊的配置语法来告诉 Rust 编译器你的依赖项之一是异步运行时(例如,我们对分配器所做的配置),而且,公平地说,甚至没有一个关于运行时的标准化定义(例如,Executor trait)。 因此,你应该在 main 函数的顶部启动异步运行时,
然后用它来驱动你的 Future 完成。
你现在可能已经猜到 #[tokio::main] 的用途了,但仅仅猜测是不够的:
我们想看到它。
但是怎么做呢?
tokio::main 是一个过程宏,这是一个引入 cargo expand 的绝佳机会,它对于 Rust 开发来说是一个很棒的补充:
cargo install cargo-expand
Rust 宏在 token 级别运行:它们接收一个符号流(例如,在我们的例子中是整个 main 函数),并输出一个新符号流,然后将其传递给编译器。换句话说,Rust 宏的主要用途是代码生成。
我们如何调试或检查特定宏的运行情况?您可以检查它输出的 token!
这正是 cargo expand 的亮点所在:它会扩展代码中的所有宏,而无需将输出传递给编译器,让您可以单步执行并了解正在发生的事情。
让我们使用 cargo expand 来揭开 #[tokio::main] 的神秘面纱:
cargo expand
fn main() -> std::io::Result<()> {
let body = async { run().await };
#[allow(
clippy::expect_used,
clippy::diverging_sub_expression,
clippy::needless_return
)]
{
return tokio::runtime::Builder::new_multi_thread()
.enable_all()
.build()
.expect("Failed building the Runtime")
.block_on(body);
}
}
我们终于可以看看宏扩展后的代码了!
#[tokio::main] 扩展后传递给 Rust 编译器的 main 函数
确实是同步 (Sync) 的, 这也解释了为什么它编译时没有任何问题。
关键的一行是:tokio::runtime::Builder::new_multi_thread().enable_all().build().expect("[...]").block_on(/*[...]*/)
我们正在启动 tokio 的异步运行时,并使用它来驱动 HttpServer::run 返回的 Future 完成。
换句话说,#[tokio::main] 的作用是让我们产生能够定义异步主函数的错觉,而实际上,它只是获取我们的主要异步代码,并编写必要的样板代码,使其在 tokio 的运行时之上运行。
实现 Health Check Handler
我们已经回顾了 actix_web 的 Hello World! 示例中所有需要移动的部分:HttpServer、App、route 和 actix_web::main。
我们当然已经了解了足够多的内容,可以修改示例,使健康检查能够按预期工作:
在 /health_check 收到 GET 请求时,返回一个不带正文的 200 OK 响应。
让我们重新回顾一下我们的起点:
use actix_web::{App, HttpRequest, HttpServer, Responder, web};
async fn greet(req: HttpRequest) -> impl Responder {
let name = req.match_info().get("name").unwrap_or("World");
format!("Hello {}!", &name)
}
#[tokio::main]
async fn main() -> std::io::Result<()> {
HttpServer::new(|| {
App::new()
.route("/", web::get().to(greet))
.route("/{name}", web::get().to(greet))
})
.bind("127.0.0.1:8000")?
.run()
.await
}
首先,我们需要一个请求处理程序。模仿 greet 函数,我们可以从以下签名开始:
async fn health_check(req: HttpRequest) -> impl Responder {
todo!()
}
我们说过,Responder 只不过是一个转换为 HttpResponse 的 trait。那么直接返回一个 HttpResponse 实例应该就行了!
查看它的文档,我们可以使用 HttpResponse::Ok 来获取一个已准备好 200 状态码的 HttpResponseBuilder。HttpResponseBuilder 提供了一个丰富的流畅 API,可以逐步构建 HttpResponse 响应,但我们在这里不需要它: 我们可以通过在构建器上调用 finish 来获取一个带有空主体的 HttpResponse。
将所有内容结合在一起:
use actix_web::{HttpRequest, HttpResponse, Responder};
// [...]
async fn health_check(req: HttpRequest) -> impl Responder {
HttpResponse::Ok().finish()
}
快速运行一下 cargo check,确认我们的处理程序没有做任何奇怪的事情。
仔细查看一下 HttpResponseBuilder 的定义, 会发现它也实现了 Responder 接口——因此,我们可以省略对 finish 的调用,并将处理程序简化为:
// [...]
async fn health_check(req: HttpRequest) -> impl Responder {
HttpResponse::Ok()
}
下一步是处理程序注册 - 我们需要通过 route 将其添加到我们的 App 中: (别忘了删除示例中的greet方法和相关route注册的代码)
//! src/main.rs
// [...]
#[tokio::main]
async fn main() -> std::io::Result<()> {
// [...]
App::new()
// [...]
.route("/health_check", web::get().to(health_check))
// [...]
}
现在我们的代码看起来是这样
use actix_web::{web, App, HttpRequest, HttpResponse, HttpServer, Responder};
async fn health_check(req: HttpRequest) -> impl Responder {
HttpResponse::Ok()
}
#[tokio::main]
async fn main() -> std::io::Result<()> {
HttpServer::new(|| {
App::new()
.route("/health_check", web::get().to(health_check))
})
.bind("127.0.0.1:8000")?
.run()
.await
}
你可能看到 cargo check 在抱怨变量 req没有用到
我们的健康检查响应确实是静态的,并且不使用任何与传入 HTTP 请求捆绑的数据(路由除外)。我们可以遵循编译器的建议,在 req 前添加下划线...... 或者,我们可以从 health_check 中完全删除该输入参数:
async fn health_check() -> impl Responder {
HttpResponse::Ok()
}
惊喜啊,它编译通过了!actix-web 在后台运行着一些相当高级的类型处理程序, 并且它接受各种各样的签名作为请求处理程序——稍后会详细介绍。
接下来做什么?
好吧,来个小测试!
curl -v http://127.0.0.1:8000/health_check
$ curl -v http://127.0.0.1:8000/health_check
* Trying 127.0.0.1:8000...
* Connected to 127.0.0.1 (127.0.0.1) port 8000
* using HTTP/1.x
> GET /health_check HTTP/1.1
> Host: 127.0.0.1:8000
> User-Agent: curl/8.15.0
> Accept: */*
>
* Request completely sent off
< HTTP/1.1 200 OK
< content-length: 0
< date: Wed, 20 Aug 2025 06:36:57 GMT
<
* Connection #0 to host 127.0.0.1 left intact
你现在应该可以在响应中看到类似HTTP/1.1 200 OK的字样
这太棒了! 我们的Health Check正在工作!
恭喜你实现了第一个 actix-web 端点!
我们的第一个集成测试
/health_check 是我们的第一个端点,我们通过启动应用程序并通过 curl 手动测试来验证一切是否按预期运行。
然而,手动测试非常耗时: 随着应用程序规模的扩大,每次执行更改时,手动检查我们对其行为的所有假设是否仍然有效,成本会越来越高。
我们希望尽可能地实现自动化: 这些检查应该在每次提交更改时都在我们的持续集成 (CI) 流水线中运行,以防止出现回归问题。
虽然健康检查的行为在整个过程中可能不会有太大变化,但它是正确设置测试框架的良好起点。
我应该怎么测试一个API Endpoint
API 是达到目的的手段:一种暴露给外界执行某种任务的工具(例如,存储文档、发布电子邮件等)。
我们在 API 中暴露的端点定义了我们与客户端之间的契约:关于系统输入和输出(即接口)的共同协议。
契约可能会随着时间的推移而演变,我们可以粗略地设想两种情况:
- 向后兼容的变更(例如,添加新的端点)
- 重大变更(例如,移除端点或从其输出的架构中删除字段)。
在第一种情况下,现有的 API 客户端将保持原样运行。在第二种情况下,如果现有的集成依赖于契约中被违反的部分,则可能会中断。
虽然我们可能会故意部署对 API 契约的重大变更,但至关重要的是,我们不要意外地破坏它。
什么是最可靠的方法来检查我们没有引入用户可见的回归?
通过与用户完全一样的方式与 API 交互来测试 API:向 API 执行 HTTP 请求,并验证我们对收到的响应的假设。
这通常被称为黑盒测试:我们通过检查系统的输出来验证系统的行为,而不需要了解其内部实现的细节。
遵循这一原则,我们不会满足于直接调用处理函数的测试——例如:
#[cfg(test)]
mod tests {
use crate::health_check;
#[tokio::test]
async fn health_check_succeeds() {
let response = health_check().await;
// This requires changing the return type of `health_check`
// from `impl Responder` to `HttpResponse` to compile
// You also need to import it with `use actix_web::HttpResponse`!
assert!(response.status().is_success())
}
}
这样做并不是最佳实践
- 我们没有检查处理程序是否在 GET 请求时调用
- 我们也没有检查处理程序是否以 /health_check 作为路径调用。
更改这两个属性中的任何一个都会破坏我们的 API 契约,但我们的测试仍然会通过—— 这还不够好。
actix-web 提供了一些便利,可以在不跳过路由逻辑的情况下与应用进行交互, 但这种方法存在严重的缺陷:
- 迁移到另一个 Web 框架将迫使我们重写整个集成测试套件。 我们希望集成测试尽可能与 API 实现的底层技术高度分离(例如,在进行大规模重写或重构时,进行与框架无关的集成测试可以起到至关重要的作用!)
- 由于 actix-web 的一些限制,我们无法在生产代码和测试代码之间共享应用启动逻辑,因此,由于存在随着时间的推移出现分歧的风险,我们对测试套件提供的保证的信任度会降低。
我们将选择一个完全黑盒解决方案:我们将在每次测试开始时启动我们的应用程序,并使用现成的 HTTP 客户端 (例如 reqwest) 与其交互。
我应该把测试放在哪里
Rust 在编写测试时提供了三种选择:
- 在嵌入式测试模块中的代码旁边 (使用
mod tests)
// Some code I want to test
#[cfg(test)]
mod tests {
// Import the code I want to test
use super::*;
// My tests
}
- 在外部的
tests/文件夹
$ ls
src/
tests/
Cargo.toml
Cargo.lock
- 公共文档的一部分 (doc tests)
/// Check if a number is even.
/// ```rust
/// use zero2prod::is_even;
///
/// assert!(is_even(2));
/// assert!(!is_even(1));
/// ```
pub fn is_even(x: u64) -> bool {
x % 2 == 0
}
有什么区别?
嵌入式测试模块是项目的一部分,只是隐藏在配置条件检查 #[cfg(test)] 后面。而 tests 文件夹下的所有内容以及文档测试则被编译成各自独立的二进制文件。
这会影响可见性规则。
嵌入式测试模块对其相邻的代码拥有特权访问权:它可以与未标记为公共的结构体、方法、字段和函数进行交互,而这些内容通常无法被我们代码的用户访问,即使他们将其作为自己项目的依赖项导入也是如此。
嵌入式测试模块对于我所说的“冰山项目”非常有用,即暴露的接口非常有限(例如几个公共函数),但底层机制却非常庞大且相当复杂(例如数十个例程)。通过公开的函数来测试所有可能的边缘情况可能并非易事——您可以利用嵌入式测试模块为私有子组件编写单元测试,从而增强对整个项目正确性的整体信心。
而外部测试文件夹和文档测试对代码的访问级别,与将 crate 添加为另一个项目依赖项时获得的访问级别完全相同。因此,它们主要用于集成测试,即通过与用户完全相同的方式调用代码来测试。
我们的电子邮件简报并非库,因此两者之间的界限有点模糊——我们不会将其作为 Rust crate 公开给世界,而是将其作为可通过网络访问的 API 公开。
尽管如此,我们将使用 tests 文件夹进行 API 集成测试——它更加清晰地划分,并且将测试助手作为外部测试二进制文件的子模块进行管理也更加容易。
改变我们的项目结构以便于测试
在真正开始在 /tests 下编写第一个测试之前,我们还有一些准备工作要做。
正如我们所说,任何测试代码最终都会被编译成它自己的二进制文件——我们所有测试代码
都以 crate 的形式导入。但目前我们的项目是一个二进制文件:它旨在执行,而不是
共享。因此,我们无法像现在这样在测试中导入 main 函数。
如果您不相信我的话,我们可以做一个快速实验:
# Create the tests folder
mkdir -p tests
创建 tests/health_check.rs 然后写入如下代码
//! tests/health_check.rs
use zero2prod::main;
#[test]
fn dummy_test() {
main()
}
现在执行 cargo test, 欸? 好像报错了
error[E0432]: unresolved import `zero2prod`
--> tests/health_check.rs:1:5
|
1 | use zero2prod::main;
| ^^^^^^^^^ use of unresolved module or unlinked crate `zero2prod`
|
= help: if you wanted to use a crate named `zero2prod`, use `cargo add zero2prod` to add it to your `Cargo.toml`
For more information about this error, try `rustc --explain E0432`.
error: could not compile `zero2prod` (test "health_check") due to 1 previous error
译者注: 原作此处为修改 Cargo.toml来配置lib.rs, 但在最新的Rust中, lib.rs会自动识别为一个crate, 所以不必那么做了, 这里就没翻译
接下来我们创建文件 src/lib.rs
然后我们可以把 main.rs 中的逻辑搬过去了
//! main.rs
use zero2prod::run;
#[tokio::main]
async fn main() -> std::io::Result<()> {
run().await
}
//! lib.rs
use actix_web::{App, HttpResponse, HttpServer, Responder, web};
async fn health_check() -> impl Responder {
HttpResponse::Ok()
}
pub async fn run() -> std::io::Result<()> {
HttpServer::new(|| App::new().route("/health_check", web::get().to(health_check)))
.bind("127.0.0.1:8000")?
.run()
.await
}
好了,我们准备编写一些有趣的集成测试!
实现我们的第一个集成测试
我们对健康检查端点的规范是:当我们收到 /health_check 的 GET 请求时,我们会返回没有正文的 200 OK 响应。
这分为这几个部分
- GET 请求
- /health_check 端点
- 响应码 200
- 没有正文的响应
让我们将其转化为测试,并尽可能多地描述特征:
//! tests/health_check.rs
// `tokio::test` is the testing equivalent of `tokio::main`.
// It also spares you from having to specify the `#[test]` attribute.
//
// You can inspect what code gets generated using
// `cargo expand --test health_check` (<- name of the test file)
#[tokio::test]
async fn health_check_works() {
// Arrange
spawn_app().await.expect("Failed to spawn our app.");
// We need to bring in `reqwest`
// to perform HTTP requests against our application.
let client = reqwest::Client::new();
// Act
let response = client
.get("http://127.0.0.1:8000/health_check")
.send()
.await
.expect("Failed to execute request.");
// Assert
assert!(response.status().is_success());
assert_eq!(Some(0), response.content_length());
}
async fn spawn_app() -> std::io::Result<()> {
todo!()
}
当然别忘了添加 reqwest 依赖
cargo add reqwest --dev
请花点时间仔细看看这个测试用例。
spawn_app 是唯一一个合理地依赖于我们应用程序代码的部分。
其他所有内容都与底层实现细节完全解耦——如果明天我们决定放弃 Rust,用 Ruby on Rails 重写应用程序,我们仍然可以使用相同的测试套件来检查新堆栈中的回归问题,只要将 spawn_app 替换为合适的触发器(例如,使用 bash 命令启动 Rails 应用程序)。
该测试还涵盖了我们感兴趣的所有属性:
- 健康检查暴露在 /health_check;
- 健康检查使用 GET 方法;
- 健康检查始终返回 200;
- 健康检查的响应没有正文。
如果这个测试通过了,这就完成了。
测试还没来得及做任何有用的事情就崩溃了:我们缺少了 spawn_app,这是集成测试的最后一块拼图。
为什么我们不直接在那里调用 run 呢? 也就是说
async fn spawn_app() -> std::io::Result<()> {
zero2prod::run().await
}
让我们试试看!
cargo test
无论等待多久,测试执行都不会终止。这是怎么回事?
在 zero2prod::run 中,我们调用(并等待)HttpServer::run。HttpServer::run 返回一个 Server 实例 - 当我们调用 .await 时,它会无限期地监听我们指定的地址:它会处理传入的请求,但永远不会自行关闭或“完成”。
这意味着 spawn_app 永远不会返回,我们的测试逻辑也永远不会执行。
我们需要将应用程序作为后台任务运行。
tokio::spawn 在这里非常方便:tokio::spawn 接受一个 Future 并将其交给运行时进行轮询,
而无需等待其完成;因此,它与下游 Future 和任务(例如我们的测试逻辑)并发运行。
让我们重构 zero2prod::run,使其返回一个 Server 实例而不等待它:
//! src/lib.rs
// [...]
// Notice the different signature!
// We return `Server` on the happy path and we dropped the `async` keyword
// We have no .await call, so it is not needed anymore.
pub fn run() -> Result<Server, std::io::Error> {
let server = HttpServer::new(|| App::new().route("/health_check", web::get().to(health_check)))
.bind("127.0.0.1:8000")?
.run();
// No .await here!
Ok(server)
}
我们需要相应地修改我们的 main.rs:
//! src/main.rs
use zero2prod::run;
#[tokio::main]
async fn main() -> std::io::Result<()> {
run()?.await
}
运行一下 cargo check 应该能让我们确信一切正常。
现在我们可以实现 spawn_app 方法
// No .await call, therefore no need for `spawn_app` to be async now.
// We are also running tests, so it is not worth it to propagate errors:
// if we fail to perform the required setup we can just panic and crash
// all the things.
fn spawn_app() {
let server = zero2prod::run().expect("Failed to bind address");
// Launch the server as a background task
// tokio::spawn returns a handle to the spawned future,
// but we have no use for it here, hence the non-binding let
let _ = tokio::spawn(server);
}
快速调整我们的测试以适应 spawn_app 方法签名的变化:
#[tokio::test]
async fn health_check_works() {
// [...]
spawn_app();
// [...]
现在是时候运行 cargo test 了!
running 1 test
test health_check_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.03s
耶!我们的第一次集成测试通过了!
替我给自己鼓个掌,在一个章节内完成了第二个重要的里程碑。
Polishing
我们已经让它运行起来了,现在我们需要重新审视并改进它,如果需要或可能的话
清理
测试运行结束后,后台运行的应用会发生什么?
它会关闭吗? 它会像僵尸程序一样徘徊在某个地方吗?
嗯,连续多次运行 cargo test 总是会成功——这强烈暗示我们的 8000 端口会在每次运行结束时被释放,因此意味着应用已正确关闭。
再次查看 tokio::spawn 的文档,这支持了我们的假设:当一个 tokio 运行时关闭时,所有在其上生成的任务都会被丢弃。tokio::test 会在每个测试用例开始时启动一个新的运行时,并在每个测试用例结束时关闭。
换句话说,好消息是——无需实现任何清理逻辑来避免测试运行期间的资源泄漏。
选择随机端口
spawn_app 总是会尝试在 8000 端口上运行我们的应用——这并不理想:
- 如果 8000 端口正在被我们机器上的其他程序(例如我们自己的应用!)占用,测试就会失败;
- 如果我们尝试并行运行两个或多个测试,那么只有一个测试能够绑定端口,其他所有测试都会失败。
我们可以做得更好: 测试应该在随机可用的端口上运行它们的后台应用。
首先,我们需要修改 run 函数——它应该将应用地址作为参数,而不是依赖于硬编码的值:
让我们修改 lib.rs
//! src/lib.rs
// [...]
pub fn run(address: &str) -> Result<Server, std::io::Error> {
let server = HttpServer::new(|| App::new().route("/health_check", web::get().to(health_check)))
.bind(address)?
.run();
// No .await here!
Ok(server)
}
然后,所有 zero2prod::run() 调用都必须更改为 zero2prod::run("127.0.0.1:8000") 才能保留相同的行为并使项目再次编译。
我们如何为测试找到一个随机可用的端口?
操作系统可以帮上忙:我们将使用端口 0。
端口 0 在操作系统层面是特殊情况:尝试绑定端口 0 将触发操作系统扫描可用端口,
然后该端口将被绑定到应用程序。
因此,只需将 spawn_app 更改为
//! tests/health_check.rs
fn spawn_app() {
let server = zero2prod::run("127.0.0.1:0").expect("Failed to bind address");
let _ = tokio::spawn(server);
}
注: 原作这里忘了提到要修改 main.rs 了, 请暂时将 main.rs 中的代码修改为
run("127.0.0.1:8000")?.await
这样就好了~ 现在,每次启动 Cargo 测试时,后台应用都会在随机端口上运行! 只有一个小问题...... 我们的测试失败了
running 1 test
test health_check_works ... FAILED
failures:
---- health_check_works stdout ----
thread 'health_check_works' panicked at tests/health_check.rs:19:10:
Failed to execute request.: reqwest::Error { kind: Request, url: "http://127.0.0.1:8000/health_check", source: hyper_util::client::legacy::Error(Connect, ConnectError("tcp connect error", 127.0.0.1:80
00, Os { code: 111, kind: ConnectionRefused, message: "Connection refused" })) }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
health_check_works
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.02s
我们的 HTTP 客户端仍在调用 127.0.0.1:8000,我们现在真的不知道该在那里放什么: 应用程序端口是在运行时确定的,我们无法在那里进行硬编码。
我们需要以某种方式找出操作系统分配给我们应用程序的端口,并将其从 spawn_app 返回。
有几种方法可以实现这一点——我们将使用 std::net::TcpListener。
我们的 HttpServer 目前承担着双重任务:给定一个地址,它会绑定它,然后启动应用程序。我们可以接手第一步:我们自己用 TcpListener 绑定端口,然后使用 listen 将其交给 HttpServer。
这样做有什么好处呢?
TcpListener::local_addr 返回一个 SocketAddr 对象,它暴露了我们通过 .port() 绑定的实际端口。
让我们从 run 函数开始:
//! src/lib.rs
// [...]
pub fn run(listener: TcpListener) -> Result<Server, std::io::Error> {
let server = HttpServer::new(|| App::new().route("/health_check", web::get().to(health_check)))
.listen(listener)?
.run();
Ok(server)
}
这项更改破坏了我们的 main 函数和 spawn_app 函数。main 函数就留给你处理吧,我们来重点处理 spawn_app 函数:
//! tests/health_check.rs
// [...]
fn spawn_app() -> String {
let listener = TcpListener::bind("127.0.0.1:0").expect("Failed to bind random port");
// We retrieve the port assigned to us by the OS
let port = listener.local_addr().unwrap().port();
let server = zero2prod::run(listener).expect("Failed to bind address");
let _ = tokio::spawn(server);
// We return the application address to the caller!
format!("http://127.0.0.1:{}", port)
}
现在我们可以在 reqwest::Client 中引用这个地址:
//! tests/health_check.rs
// [...]
#[tokio::test]
async fn health_check_works() {
// Arrange
let address = spawn_app();
let client = reqwest::Client::new();
// Act
let response = client
// Use the returned application address
.get(format!("{address}/health_check"))
.send()
.await
.expect("Failed to execute request.");
// Assert
assert!(response.status().is_success());
assert_eq!(Some(0), response.content_length());
}
// [...]
回顾
让我们稍事休息一下,回顾一下,我们已经完成了相当多的内容!
我们着手实现一个 /health_check 端点,这让我们有机会进一步了解我们的 Web 框架 actix-web 的基础知识,以及 Rust API 的(集成)测试基础知识。
现在是时候利用我们学到的知识,最终完成我们电子邮件通讯项目的第一个用户故事了:
作为博客访问者, 我想订阅新闻简报, 以便在博客发布新内容时收到电子邮件更新
我们希望博客访问者在网页嵌入的表单中输入他们的电子邮件地址。
该表单将触发对我们后端 API 的 POST /subscriptions 调用,后端 API 将实际处理信息、存储信息并返回响应。
我们将深入研究:
- 如何在 actix-web 中读取 HTML 表单中收集的数据(例如,如何解析 POST 请求体?);
- 哪些库可以在 Rust 中使用 PostgreSQL 数据库(diesel、sqlx 和 tokio-postgres);
- 如何设置和管理数据库迁移;
- 如何在 API 请求处理程序中获取数据库连接;
- 如何在集成测试中测试副作用(即存储数据);
- 如何避免在使用数据库时测试之间出现奇怪的交互。
让我们开始吧!
使用HTML表单
完善我们的要求
为了将访客注册为我们的电子邮件简报,我们应该收集哪些信息?
嗯,我们当然需要他们的电子邮件地址(毕竟这是一封电子邮件简报)。 还有什么?
在典型的业务环境中,这通常会引发团队工程师和产品经理之间的对话。在这种情况下,我们既是技术主管,又是产品负责人,因此我们可以发号施令!
从个人经验来看,人们在订阅新闻通讯时通常会使用一次性或屏蔽电子邮件(或者,至少你们大多数人在订阅“从零到生产”时都是这样做的!)。
因此,收集一个名字会很不错,我们可以用它来作为电子邮件问候语(比如臭名昭著的 "Hey,{{subscriber.name}}!" ),也可以在订阅者列表中识别我们认识的人或共同订阅者。
我们不是警察,我们对姓名字段的真实性不感兴趣——我们会让人们在我们的新闻通讯系统中输入他们喜欢的任何身份信息: DenverCoder9, 我们欢迎你。
那么,事情就解决了:我们需要为所有新订阅者提供电子邮件地址和姓名。
鉴于数据是通过 HTML 表单收集的,它将通过 POST 请求的正文传递给我们的后端 API。正文将如何编码?
使用 HTML 表单时,有几种可用的编码方式: application/x-www-form-urlencoded
这最适合我们的用例。
引用 MDN Web 文档,使用 application/x-www-form-urlencoded
在我们的表单中,键和值被编码为键值元组,并以“&”分隔,键和值之间用“=”分隔。键和值中的非字母数字字符均采用百分号编码。
例如:如果名字是 Le Guin, 邮箱是 ursula_le_guin@gmail.com,则 POST 请求体应为 name=le%20guin&email=ursula_le_guin%40gmail.com(空格替换为 %20,而 @ 替换为 %40 - 可在此处找到参考转换表)。
总结:
- 如果使用
application/x-www-form-urlencoded格式提供了有效的姓名和邮箱地址组合,后端应返回 200 OK - 如果姓名或邮箱地址缺失,后端应返回 400 BAD REQUEST。
将我们的需求作为测试
现在我们更好地理解了需要做什么,让我们将我们的期望编码到几个集成测试中。
让我们将新的测试添加到现有的 tests/health_check.rs 文件中——之后我们将重新组织测试套件的文件夹结构。
//! tests/health_check.rs
// [...]
#[tokio::test]
async fn subscribe_returns_a_200_for_valid_form_data() {
// Arrange
let app_address = spawn_app();
let client = reqwest::Client::new();
// Act
let body = "name=le%20guin&email=ursula_le_guin%40gmail.com";
let response = client
.post(&format!("{}/subscriptions", &app_address))
.header("Content-Type", "application/x-www-form-urlencoded")
.body(body)
.send()
.await
.expect("Failed to execute request.");
// Assert
assert_eq!(200, response.status().as_u16());
}
#[tokio::test]
async fn subscribe_returns_a_400_when_data_is_missing() {
// Arrange
let app_address = spawn_app();
let client = reqwest::Client::new();
let test_cases = vec![
("name=le%20guin", "missing the email"),
("email=ursula_le_guin%40gmail.com", "missing the name"),
("", "missing both name and email"),
];
for (invalid_body, error_message) in test_cases {
// Act
let response = client
.post(&format!("{}/subscriptions", &app_address))
.header("Content-Type", "application/x-www-form-urlencoded")
.body(invalid_body)
.send()
.await
.expect("Failed to execute request.");
// Assert
assert_eq!(
400,
response.status().as_u16(),
// Additional customised error message on test failure
"The API did not fail with 400 Bad Request when the payload was {}.",
error_message
);
}
}
subscribe_returns_a_400_when_data_is_missing 是一个表驱动测试的例子,也称为参数化测试。
它在处理错误输入时尤其有用——我们不必多次重复测试逻辑,只需对一组已知无效的主体运行相同的断言即可,这些主体我们预计会以相同的方式失败。
对于参数化测试,在失败时提供清晰的错误消息非常重要:如果您无法确定哪个特定的输入出错,那么在 XYZ 行的断言失败就不太理想!另一方面,该参数化测试涵盖的内容很广泛,因此花更多时间来生成清晰的失败消息是有意义的。
其他语言的测试框架有时原生支持这种测试风格 (例如 pytest 中的参数化测试,或 C# 的 xUnit 中的 InlineData)。Rust 生态系统中有一些 crate,它们扩展了基本测试框架,并提供了类似的功能,但遗憾的是,它们与 #[tokio::test] 宏的互操作性不佳,而我们需要使用宏来编写惯用的异步测试 (参见 rstest 或 test-case)。
现在让我们运行测试套件:
running 3 tests
test subscribe_returns_a_200_for_valid_form_data ... FAILED
test subscribe_returns_a_400_when_data_is_missing ... FAILED
test health_check_works ... ok
failures:
---- subscribe_returns_a_200_for_valid_form_data stdout ----
thread 'subscribe_returns_a_200_for_valid_form_data' panicked at tests/health_check.rs:39:5:
assertion `left == right` failed
left: 200
right: 404
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
---- subscribe_returns_a_400_when_data_is_missing stdout ----
thread 'subscribe_returns_a_400_when_data_is_missing' panicked at tests/health_check.rs:63:9:
assertion `left == right` failed: The API did not fail with 400 Bad Request when the payload was missing the email.
left: 400
right: 404
failures:
subscribe_returns_a_200_for_valid_form_data
subscribe_returns_a_400_when_data_is_missing
test result: FAILED. 1 passed; 2 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.03s
error: test failed, to rerun pass `--test health_check`
正如预期的那样,我们所有的新测试都失败了。
你很快就能发现“自行开发”参数化测试的一个局限性: 一旦一个测试用例失败,执行就会停止,我们也无法知道后续测试用例的结果。
让我们开始实现吧。
从 POST 请求解析表单数据
所有测试都失败了,因为应用程序在 POST 请求到达 /subscriptions 时返回了 404 NOT FOUND 错误。这是合理的:我们没有为该路径注册处理程序。
让我们通过在 src/lib.rs 中添加一个匹配的路由来解决这个问题:
//! src/lib.rs
use std::net::TcpListener;
use actix_web::{App, HttpResponse, HttpServer, Responder, dev::Server, web};
// We were returning `impl Responder` at the very beginning.
// We are now spelling out the type explicitly given that we have
// become more familiar with `actix-web`.
// There is no performance difference! Just a stylistic choice :)
async fn health_check() -> impl Responder {
HttpResponse::Ok()
}
// Let's start simple: we always return a 200 OK
async fn subscribe() -> HttpResponse {
HttpResponse::Ok().finish()
}
pub fn run(listener: TcpListener) -> Result<Server, std::io::Error> {
let server = HttpServer::new(|| {
App::new()
.route("/health_check", web::get().to(health_check))
// A new entry in our routing table for POST /subscriptions requests
.route("/subscriptions", web::post().to(subscribe))
})
.listen(listener)?
.run();
Ok(server)
}
再次运行测试
running 3 tests
test health_check_works ... ok
test subscribe_returns_a_200_for_valid_form_data ... ok
test subscribe_returns_a_400_when_data_is_missing ... FAILED
failures:
---- subscribe_returns_a_400_when_data_is_missing stdout ----
thread 'subscribe_returns_a_400_when_data_is_missing' panicked at tests/health_check.rs:63:9:
assertion `left == right` failed: The API did not fail with 400 Bad Request when the payload was missing the email.
left: 400
right: 200
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
subscribe_returns_a_400_when_data_is_missing
test result: FAILED. 2 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.03s
subscribe_returns_a_200_for_valid_form_data 现在通过了: 好吧,我们的处理程序将所有传入的数据视为有效数据,这并不奇怪。
subscribe_returns_a_400_when_data_is_missing 仍然是红色 (未通过)。
是时候对该请求主体进行一些真正的解析了。actix-web 为我们提供了什么?
Extractors
actix-web 用户指南中, Extractors 部分尤为突出。 顾名思义,Extractors 用于指示框架从传入请求中提取特定信息。 actix-web 提供了几个开箱即用的提取器,以满足最常见的用例:
- Path 用于从请求路径中获取动态路径段
- Query 用于查询参数
- Json 用于解析 JSON 编码的请求正文
- 等等
幸运的是,有一个Extractor正好可以满足我们的用例: Form
阅读它的文档:
表单数据助手 (
application/x-www-form-urlencoded)。 可用于从请求正文中提取 URL 编码数据,或将 URL 编码数据作为响应发送。
这真是太棒了!
我们该如何使用它?
查看 actix-web 的用户指南:
提取器可以作为处理函数的参数访问。Actix-web 每个处理函数最多支持 10 个提取器。参数位置无关紧要。
例子:
use actix_web::web;
#[derive(serde::Deserialize)]
struct FormData {
username: String,
}
/// Extract form data using serde.
/// This handler get called only if content type is *x-www-form-urlencoded*
/// and content of the request could be deserialized to a `FormData` struct
fn index(form: web::Form<FormData>) -> String {
format!("Welcome {}!", form.username)
}
所以,基本上……你只需将它作为处理程序和 actix-web 的参数添加到那里,当请求到达时,它就会以某种方式为你完成繁重的工作。我们现在先了解一下,稍后再回过头来了解底层发生了什么。
我们的 subscribe handler目前如下所示:
async fn subscribe() -> HttpResponse {
HttpResponse::Ok().finish()
}
使用这个例子作为蓝图,我们可能想要一些类似这样的内容:
//! src/lib.rs
// [...]
#[derive(serde::Deserialize)]
struct FormData {
email: String,
name: String
}
async fn subscribe(_form: web::Form<FormData>) -> HttpResponse {
HttpResponse::Ok().finish()
}
cargo check 并不是很开心
error[E0433]: failed to resolve: use of unresolved module or unlinked crate `serde`
--> src/lib.rs:5:10
|
5 | #[derive(serde::Deserialize)]
| ^^^^^ use of unresolved module or unlinked crate `serde`
好吧,我们需要将 serde 添加到依赖项中。让我们在 Cargo.toml 中添加一行:
[dependencies]
# We need the optional `derive` feature to use `serde`'s procedural macros:
# `#[derive(Serialize)]` and `#[derive(Deserialize)]`.
# The feature is not enabled by default to avoid pulling in
# unnecessary dependencies for projects that do not need it.
serde = { version = "1", features = ["derive"]}
cargo check 现在应该可以通过了, 那 cargo test 呢
running 3 tests
test subscribe_returns_a_200_for_valid_form_data ... ok
test health_check_works ... ok
test subscribe_returns_a_400_when_data_is_missing ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.03s
全部通过!
但是为什么?
Form 和 FromRequest
让我们直接进入源码:Form 是什么样子的?
你可以在这里找到它的源代码
这个定义看起来相当简单:
#[derive(PartialEq, Eq, PartialOrd, Ord, Debug)]
pub struct Form<T>(pub T);
它只不过是一个包装器:它对类型 T 进行泛型,然后用于填充 Form 的唯一字段。
这里没什么可看的。
提取魔法在哪里发生?
提取器是实现 FromRequest trait 的类型。
FromRequest 的定义有点杂乱,因为 Rust 尚不支持 trait 定义中的 async fn 。
稍微修改一下,它大致可以归结为这样的东西:
/// Trait implemented by types that can be extracted from request.
///
/// Types that implement this trait can be used with `Route` handlers.
pub trait FromRequest: Sized {
/// The associated error which can be returned.
type Error: Into<Error>;
type Future: Future<Output = Result<Self, Self::Error>>;
fn from_request(req: &HttpRequest, payload: &mut Payload) -> Self::Future;
/// Omitting some ancillary methods that actix-web implements
/// out of the box for you and supporting associated types
/// [...]
}
from_request 将传入的 HTTP 请求的头部(即 HttpRequest)及其有效负载(即 Payload)的字节作为输入。如果提取成功,它将返回 Self;否则,它将返回一个可以转换为 actix_web::Error 的错误类型。
路由处理程序签名中的所有参数都必须实现 FromRequest trait:actix-web 将为每个参数调用 from_request,如果所有参数的提取都成功,它将运行实际的处理程序函数。
如果其中一个提取失败,则相应的错误将返回给调用者,并且处理程序永远不会被调用(actix_web::Error 可以转换为 HttpResponse)。
这非常方便: 您的处理程序无需处理原始的传入请求,而可以直接处理强类型信息,从而大大简化了处理请求所需的代码。
让我们来看看 Form 的 FromRequest 实现:它做了什么?
再次,我稍微修改了实际代码以突出关键元素并忽略具体的实现细节。
impl<T> FromRequest for Form<T>
where
T: DeserializeOwned + 'static,
{
type Error = actix_web::Error;
async fn from_request(
req: &HttpRequest,
payload: &mut Payload
) -> Result<Self, Self::Error> {
// Omitted stuff around extractor configuration (e.g. payload size limits)
match UrlEncoded::new(req, payload).await {
Ok(item) => Ok(Form(item)),
// The error handler can be customised.
// The default one will return a 400, which is what we want.
Err(e) => Err(error_handler(e))
}
}
}
所有繁重的工作似乎都发生在 UrlEncoded struct中。
UrlEncoded 的功能非常丰富: 它透明地处理压缩和未压缩的有效负载,处理请求主体以字节流的形式一次到达一个块的情况,等等。
处理完所有这些事情之后, 关键的部分是:
serde_urlencoded::from_bytes::<T>(&body).map_err(|_| UrlencodedError::Parse)
serde_urlencoded 为 application/x-www-form-urlencoded 数据格式提供(反)序列化支持。
from_bytes 接受一个连续的字节切片作为输入,并根据 URL 编码格式的规则将其反序列化为一个类型 T 的实例:键和值被编码为键值对元组,并以 & 分隔,键和值之间用 = 分隔;键和值中的非字母数字字符均采用百分号编码。
它是如何知道对于泛型类型 T 执行此操作的?
这是因为 T 实现了 serde 的 DeserializedOwned 特性:
impl<T> FromRequest for Form<T>
where
T: DeserializeOwned + 'static,
{
// [...]
}
要了解其内部实际发生的情况,我们需要仔细研究 serde 本身。
下一节关于 serde 的内容涉及一些 Rust 的高级主题。 如果您第一次阅读时没有完全理解,也没关系! 等您熟悉 Rust 之后再回来阅读,并多学习一些 serde,深入了解其中最难的部分。
Rust 中的序列化: serde
为什么我们需要 serde? serde 为我们做了什么?
引用来自它的教程的话:
Serde 是一个用于高效且通用地序列化和反序列化 Rust 数据结构的框架。
一般而言
serde 本身并不支持从/反序列化任何特定数据格式: serde 内部没有处理 JSON、Avro 或 MessagePack 细节的代码。如果您需要支持特定数据格式,则需要引入另一个 crate(例如,用于 JSON 的 serde_json 或用于 Avro 的 avro-rs)。serde 定义了一组接口,或者用它们自己的话说,一个数据模型。
如果您想要实现一个库来支持新数据格式的序列化,则必须提供 Serializer trait 的实现。
Serializer trait 中的每个方法都对应于构成 serde 数据模型的 29 种类型之一——您的 Serializer 实现指定了每种类型如何映射到您的特定数据格式。
例如,如果您要添加对 JSON 序列化的支持,您的 serialize_seq 实现
将输出一个左方括号 [ 并返回一个可用于序列化序列元素的类型。
另一方面,您有 Serialize trait:您为 Rust 类型实现 Serialize::serialize 的目的是指定如何根据 serde 的数据模型,使用 Serializer trait 中提供的方法对其进行分解。
再次使用序列示例,以下是 Rust 中为 Vec 实现 Serialize 的方式:
use serde::ser::{Serialize, Serializer, SerializeSeq};
impl<T> Serialize for Vec<T>
where
T: Serialize,
{
fn serialize<S>(&self, serializer: S) -> Result<S::Ok, S::Error>
where
S: Serializer,
{
let mut seq = serializer.serialize_seq(Some(self.len()))?;
for element in self {
seq.serialize_element(element)?;
}
seq.end()
}
}
这使得 serde 对数据格式保持不可知:一旦你的类型实现了 Serialize, 你就可以自由地使用任何具体的 Serializer 实现来实际执行序列化步骤 - 也就是说,你可以将你的类型序列化为 crates.io 上可用的 Serializer 实现的任何格式(剧透:几乎所有常用的数据格式)。
反序列化也是如此,通过 Deserialize 和 Deserializer 进行,并在生命周期方面有一些额外的细节,以支持零拷贝反序列化。
效率
serde 的速度变慢是否是因为其对底层数据格式具有泛型性?
不是,这要归功于一个称为单态化的过程。
每次使用一组具体类型调用泛型函数时,Rust 编译器都会创建函数体的副本,将泛型类型参数替换为具体类型。这使得编译器能够针对所涉及的具体类型优化函数体的每个实例:其结果与我们不使用泛型或特征,为每种类型编写单独的函数所获得的结果并无二致。换句话说,我们不会因为使用泛型而付出任何运行时成本。
这个概念非常强大,通常被称为零成本抽象:使用高级语言结构可以生成与使用更丑陋/更“手工编写”的实现相同的机器码。因此,我们可以编写更易于人类阅读的代码(正如它所期望的那样!),而无需在最终成品的质量上做出妥协。
Serde 在内存使用方面也非常谨慎:我们之前提到的中间数据模型是通过 trait 方法隐式定义的,并没有真正的中间序列化结构体。
如果您想了解更多信息,Josh Mcguigan 写了一篇精彩的深度文章,题为《理解 Serde》。
还值得指出的是,对特定类型进行(反)序列化所需的所有信息在编译时即可获得,没有任何运行时开销。
其他语言中的(反)序列化器通常利用运行时反射来获取要(反)序列化的类型的信息(例如,它们的字段名称列表)。Rust 不提供运行时反射, 因此所有信息都必须预先指定。
便捷
这就是 #[derive(Serialize)] 和 #[derive(Deserialize)] 发挥作用的地方。
你肯定不想手动详细说明项目中定义的每个类型应该如何执行序列化。这很繁琐,容易出错,而且会浪费你本应专注于特定于应用程序的逻辑的时间。
这两个过程宏与 derive feature flag 后面的 serde 捆绑在一起,将解析类型的定义并自动为你生成正确的 Serialize/Deserialize 实现。
把所有东西放在一起
结合目前所学的知识,让我们再看一下我们的订阅处理程序:
#[derive(serde::Deserialize)]
struct FormData {
email: String,
name: String,
}
async fn subscribe(_form: web::Form<FormData>) -> HttpResponse {
HttpResponse::Ok().finish()
}
现在,我们对正在发生的事情有了清晰的了解:
- 在调用 subscribe 之前,actix-web 会为所有 subscribe 的输入参数调用 from_request 方法: 在我们的例子中,是 Form::from_request;
- Form::from_request 会尝试根据 URL 编码规则,利用 serde_urlencoded 和 FormData 的 Deserialize 实现(由
#[derive(serde::Deserialize)]自动生成),将 body 反序列化为 FormData - 如果 Form::from_request 失败,则会向调用者返回 400 BAD REQUEST 错误码。如果成功,则会调用 subscribe 并返回 200 OK 错误码。
稍作思考,您会惊叹不已:它看起来如此简单,但其中却蕴含着如此丰富的内容 ——我们主要依靠 Rust 的强大功能以及其生态系统中一些最完善的 crate。
存储数据: 数据库
我们的 POST /订阅端点通过了测试,但其实用性相当有限:我们没有在任何地方存储有效的电子邮件和姓名。
我们从 HTML 表单收集的信息没有永久记录。
该如何解决这个问题?
在定义云原生时,我们列出了我们期望在系统中看到的一些新兴行为: 特别是,我们希望在易出错的环境中运行时实现高可用性。
因此,我们的应用程序被迫分布式——应该在多台机器上运行多个实例,以应对硬件故障。
这会对数据持久性产生影响:我们不能依赖主机的文件系统作为传入数据的存储层。
我们保存在磁盘上的任何内容都只能供应用程序的众多副本之一使用。
此外,如果宿主机崩溃,这些数据很可能会消失。
这解释了为什么云原生应用程序通常是无状态的: 它们的持久性需求被委托给专门的外部系统——数据库。
选择一个数据库
我们的newsletter项目应该使用什么数据库?
我先给出我的个人经验法则,听起来可能有点争议:
如果您不确定持久性需求,请使用关系数据库。
如果您不需要大规模部署,请使用 PostgreSQL。
在过去的二十年里,数据库产品种类繁多。
从数据模型的角度来看, NoSQL 运动为我们带来了文档存储 (例如 MongoDB) 、键值存储 (例如 AWS DynamoDB)、图形数据库(例如 Neo4J) 等。
我们有一些数据库使用 RAM 作为主存储(例如 Redis)。
我们有一些数据库通过列式存储针对分析查询进行了优化(例如 AWS RedShift)。
系统设计中存在着无限可能,您绝对应该充分利用这些可能性。
然而,如果您对应用程序所使用的数据访问模式还不甚了解,那么使用专门的数据存储解决方案很容易让您陷入困境。
关系数据库可以说是万能的:在构建应用程序的第一个版本时,它们通常是一个不错的选择,可以在您探索领域约束的过程中为您提供支持。
即使是关系数据库,也有很多选择。
除了 PostgreSQL 和 MySQL 等经典数据库外,您还会发现一些令人兴奋的新数据库,例如 AWS Aurora、Google Spanner 和 CockroachDB。
它们有什么共同点?
它们都是为了扩展而构建的。远远超出了传统 SQL 数据库的处理能力。
如果您担心扩展性问题,请务必考虑一下。如果不是,则无需考虑额外的复杂性。
这就是我们最终选择 PostgreSQL 的原因:它是一项久经考验的技术,如果您需要托管服务,它受到所有云提供商的广泛支持,开源,拥有详尽的文档,易于在本地运行以及通过 Docker 在 CI 中运行,并且在 Rust 生态系统中得到良好支持。
选择一个数据库 Crate
截至 2020 年 8 月,在 Rust 项目中与 PostgreSQL 交互时,有三个最常用的选项:
译者注: 在2025还有一个比较欢迎的选项叫做 sea-ql, 基于sqlx 的一个数据库crate
这三个项目都非常受欢迎,并且被广泛采用,在生产环境中也占有相当的份额。您该如何选择呢? 这取决于您对以下三个主题的看法:
- 编译时安全性
- SQL 优先 vs. DSL 用于查询构建
- 异步 vs. 同步接口
编译期安全
与关系数据库交互时,很容易犯错——例如,我们可能会:
- 查询中提到的列名或表名出现拼写错误;
- 尝试执行数据库引擎拒绝的操作(例如,将字符串和数字相加,或在错误的列上连接两个表);
- 期望返回的数据中包含实际上不存在的某个字段。
关键问题是:我们何时意识到自己犯了错误?
在大多数编程语言中,错误发生在运行时: 当我们尝试执行查询时,
数据库会拒绝它,然后我们会收到错误或异常。使用 tokio-postgres 时就会发生这种情况。
diesel 和 sqlx 试图通过在编译时检测大多数此类错误来加快反馈周期。
diesel 利用其 CLI 将数据库schema生成为 Rust 代码的表示,然后用于检查所有查询的假设。
相反, sqlx 使用过程宏在编译时连接到数据库,并检查提供的查询是否确实合理
查询接口
tokio-postgres 和 sqlx 都要求您直接使用 SQL 编写查询。
而 diesel 则提供了自己的查询构建器:查询以 Rust 类型表示,您可以通过调用其方法来添加过滤器、执行连接和类似的操作。这通常被称为领域特定语言 (DSL)。
哪一个更好?
一如既往,这取决于具体情况。
SQL 具有极高的可移植性——您可以在任何需要与关系数据库交互的项目中使用它, 无论应用程序使用哪种编程语言或框架编写。
而 diesel 的 DSL 仅在使用 diesel 时才有意义:您需要预先支付学习成本才能熟练掌握它,而且只有在您当前和未来的项目中坚持使用 diesel 时,这才值得。还值得指出的是,使用 diesel 的 DSL 表达复杂查询可能很困难, 您最终可能还是需要编写原始 SQL。
另一方面,Diesel 的 DSL 使得编写可重用组件变得更加容易:你可以将复杂的查询拆分成更小的单元,并在多个地方使用它们,就像使用普通的 Rust 函数一样。
异步支持
我记得在某处读过一篇关于异步IO的精彩解释, 大致如下:
线程用于并行工作,异步用于并行等待。
您的数据库并不与您的应用程序位于同一物理主机上:要运行查询,您必须执行网络调用。
异步数据库驱动程序不会减少处理单个查询所需的时间,但它可以让您的应用程序在等待数据库返回结果的同时,充分利用所有 CPU 核心来执行其他有意义的工作(例如,处理另一个 HTTP 请求)。
这是否足以让您接受异步代码带来的额外复杂性?
这取决于您应用程序的性能要求。
一般来说,对于大多数用例来说,在单独的线程池上运行查询应该已经足够了。同时,如果您的 Web 框架已经是异步的,那么使用异步数据库驱动程序实际上会减少您的麻烦28。
sqlx 和 tokio-postgres 都提供了异步接口,而 diesel 是同步的,并且 不打算在不久的将来推出异步支持。
还值得一提的是,tokio-postgres 是目前唯一支持查询流水线的 crate。该功能在 sqlx 中仍处于设计阶段,而我在 diesel 的文档或问题跟踪器中找不到任何提及。
总结
让我们总结一下比较矩阵中涵盖的所有内容:
| Crate | 编译期安全 | 查询接口 | 异步 |
|---|---|---|---|
| tokio-postgres | No | SQL | Yes |
| sqlx | Yes | SQL | Yes |
| diesel | Yes | DSL | No |
我们的选择: sqlx
对于“从零到生产”阶段,我们将使用 sqlx:它的异步支持简化了与 actix-web 的集成,而无需我们在编译时保证上做出妥协。
由于它使用原始 SQL 进行查询,因此它还限制了我们必须覆盖和精通的 API 范围。
有副作用的集成测试
我们想要实现什么目标?
让我们再回顾一下“满意案例”测试:
#[tokio::test]
async fn subscribe_returns_a_200_for_valid_form_data() {
// Arrange
let app_address = spawn_app();
let client = reqwest::Client::new();
// Act
let body = "name=le%20guin&email=ursula_le_guin%40gmail.com";
let response = client
.post(&format!("{}/subscriptions", &app_address))
.header("Content-Type", "application/x-www-form-urlencoded")
.body(body)
.send()
.await
.expect("Failed to execute request.");
// Assert
assert_eq!(200, response.status().as_u16());
}
我们现有的断言是不够的。
我们无法仅通过查看 API 响应来判断预期的业务结果是否已实现——我们想知道是否发生了副作用,例如数据存储。
我们想检查新订阅者的详细信息是否已实际保存。
该怎么做呢?
我们有两个选择:
- 利用公共 API 的另一个端点来检查应用程序状态;
- 在测试用例中直接查询数据库。
如果可能,您应该选择选项 1:您的测试不会考虑 API 的实现细节(例如底层数据库技术及其模式),因此不太可能受到未来重构的干扰。
遗憾的是,我们的 API 上没有任何公共端点可以让我们验证订阅者是否存在。
我们可以添加一个 GET /subscriptions 端点来获取现有订阅者列表,但这样一来,我们就必须担心它的安全性:我们不希望在没有任何形式的身份验证的情况下,将订阅者的姓名和电子邮件暴露在公共互联网上。
我们最终可能会编写一个 GET /subscriptions 端点(也就是说,我们不想登录生产数据库来查看订阅者列表),但我们不应该仅仅为了测试正在开发的功能而开始编写新功能。
让我们咬紧牙关,在测试中编写一个小查询。当出现更好的测试策略时,我们会将其删除。
设置数据库
为了在测试套件中运行查询,我们需要:
- 一个正在运行的 Postgres 实例
- 一个用于存储订阅者数据的表
Docker
我们将使用 Docker 来运行 Postgres。在启动测试套件之前,我们将使用 Postgres 的官方 Docker 镜像启动一个新的 Docker 容器。
您可以按照 Docker 网站上的说明将其安装到您的机器上。
让我们为它创建一个小型 Bash 脚本 scripts/init_db.sh,并添加一些自定义 Postgres 默认设置的功能:
#!/usr/bin/env bash
set -x
set -eo pipefail
# Check if a custom user has been set, otherwise default to 'postgres'
DB_USER=${POSTGRES_USER:=postgres}
# Check if a custom password has been set, otherwise default to 'password'
DB_PASSWORD="${POSTGRES_PASSWORD:=password}"
# Check if a custom database name has been set, otherwise default to 'newsletter'
DB_NAME="${POSTGRES_DB:=newsletter}"
# Check if a custom port has been set, otherwise default to '5432'
DB_PORT="${POSTGRES_PORT:=5432}"
# Launch postgres using Docker
docker run \
-e POSTGRES_USER=${DB_USER} \
-e POSTGRES_PASSWORD=${DB_PASSWORD} \
-e POSTGRES_DB=${DB_NAME} \
-p "${DB_PORT}":5432 \
-d postgres \
postgres -N 1000
# ^ Increased maximum number of connections for testing purposes
执行如下命令让这个文件可以被执行
chmod +x scripts/init_db.sh
然后我们可以启动 PostgreSQL
./scripts/init_db.sh
如果你运行 docker ps 你应该会看到类似这样的内容
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
06b8e8a7252d postgres "docker-entrypoint.s…" 5 seconds ago Up 4 seconds 0.0.0.0:5432->5432/tcp, [::]:5432->5432/tcp zen_herschel
注意 - 如果您没有在用 Linux,端口映射位可能会略有不同!
数据库迁移
为了存储订阅者的详细信息,我们需要创建第一张表。
要向数据库添加新表,我们需要更改其架构——这通常称为数据库迁移。
sqlx-cli
sqlx 提供了一个命令行界面 sqlx-cli 来管理数据库迁移。
我们可以使用以下命令安装 CLI:
cargo install --version=0.8.6 sqlx-cli --no-default-features --features postgres
运行 sqlx --help 检查一切是否按预期工作。
数据库创建
我们通常要运行的第一个命令是 sqlx database create。根据帮助文档:
Creates the database specified in your DATABASE_URL
Usage: sqlx database create [OPTIONS]
Options:
--no-dotenv Do not automatically load `.env` files
-D, --database-url <DATABASE_URL> Location of the DB, by default will be read from the DATABASE_URL env var or `.env`
files [env: DATABASE_URL=]
--connect-timeout <CONNECT_TIMEOUT> The maximum time, in seconds, to try connecting to the database server before
returning an error [default: 10]
-h, --help Print help
在我们的例子中,这并非绝对必要:我们的 Postgres Docker 实例已经自带了一个名为 newsletter 的默认数据库,这要归功于我们在启动它时使用环境变量指定的设置。尽管如此,您仍需要在 CI 管道和生产环境中执行创建步骤,所以无论如何都值得介绍一下。
正如帮助文档所示,sqlx database create 依赖于 DATABASE_URL 环境变量来
确定要执行的操作。
DATABASE_URL 应为有效的 Postgres 连接字符串 - 格式如下:
postgres://${DB_USER}:${DB_PASSWORD}@${DB_HOST}:${DB_PORT}/${DB_NAME}
因此,我们可以在 scripts/init_db.sh 脚本中添加几行
# [...]
export DATABASE_URL=postgres://${DB_USER}:${DB_PASSWORD}@localhost:${DB_PORT}/${DB_NAME}
sqlx database create
您可能偶尔会遇到一个恼人的问题:当我们尝试运行 sqlx database create 命令时,Postgres 容器尚未准备好接受连接。
我经常遇到这种情况,因此想找个解决办法:我们需要等待 Postgres 恢复正常, 然后才能开始对其运行命令。让我们将脚本更新为:
#!/usr/bin/env bash
set -x
set -eo pipefail
# Check if a custom user has been set, otherwise default to 'postgres'
DB_USER=${POSTGRES_USER:=postgres}
# Check if a custom password has been set, otherwise default to 'password'
DB_PASSWORD="${POSTGRES_PASSWORD:=password}"
# Check if a custom database name has been set, otherwise default to 'newsletter'
DB_NAME="${POSTGRES_DB:=newsletter}"
# Check if a custom port has been set, otherwise default to '5432'
DB_PORT="${POSTGRES_PORT:=5432}"
# Launch postgres using Docker
docker run \
-e POSTGRES_USER=${DB_USER} \
-e POSTGRES_PASSWORD=${DB_PASSWORD} \
-e POSTGRES_DB=${DB_NAME} \
-p "${DB_PORT}":5432 \
-d postgres \
postgres -N 1000
# ^ Increased maximum number of connections for testing purposes
# Keep pinging Postgres until it's ready to accept commands
export PGPASSWORD="${DB_PASSWORD}"
until psql -h "localhost" -U "${DB_USER}" -p "${DB_PORT}" -d "postgres" -c '\q'; do
>&2 echo "Postgres is still unavailable - sleeping"
sleep 1
done
>&2 echo "Postgres is up and running on port ${DB_PORT}!"
export DATABASE_URL=postgres://${DB_USER}:${DB_PASSWORD}@localhost:${DB_PORT}/${DB_NAME}
sqlx database create
问题解决了!
健康检查使用 Postgres 的命令行客户端 psql。请查看以下说明,了解如何在您的操作系统上安装它。
脚本本身没有附带清单文件来声明其依赖项:很遗憾,在没有安装所有先决条件的情况下启动脚本的情况非常常见。这通常会导致脚本在执行过程中崩溃,有时会导致系统处于半崩溃状态。
我们可以在初始化脚本中做得更好:让我们在一开始就检查 psql 和 sqlx-cli 是否都已安装。
set -x
set -eo pipefail
if ! [ -x "$(command -v psql)" ]; then
echo >&2 "Error: psql is not installed."
exit 1
fi
if ! [ -x "$(command -v sqlx)" ]; then
echo >&2 "Error: sqlx is not installed."
echo >&2 "Use:"
echo >&2 "
cargo install --version=0.5.7 sqlx-cli --no-default-features --features postgres"
echo >&2 "to install it."
exit 1
fi
# [...]
添加迁移
现在让我们创建第一个迁移
# Assuming you used the default parameters to launch Postgres in Docker!
export DATABASE_URL=postgres://postgres:password@127.0.0.1:5432/newsletter
sqlx migrate add create_subscriptions_table
您的项目中现在应该会出现一个新的顶级目录 - migrations。sqlx 的 CLI 将把我们项目的所有迁移文件存储在这里。
在 migrations 下,您应该已经有一个名为 {timestamp}_create_subscriptions_table.sql 的文件。
我们需要在这里编写第一个迁移文件的 SQL 代码。
让我们快速勾勒出我们需要的查询:
-- migrations/{timestamp}_create_subscriptions_table.sql
-- Create Subscriptions Table
CREATE TABLE subscriptions(
id uuid NOT NULL,
PRIMARY KEY (id),
email TEXT NOT NULL UNIQUE,
name TEXT NOT NULL,
subscribed_at timestamptz NOT NULL
);
关于主键的争论一直存在:有些人喜欢使用具有业务含义的列(例如,电子邮件、自然键),而另一些人则觉得使用没有任何业务含义的合成键更安全(例如,ID、随机生成的 UUID、代理键)。
除非有非常充分的理由,否则我通常默认使用合成标识符——如果您对此有不同意见,请随意。
另外需要注意以下几点:
- 我们使用 subscribed_at 来跟踪订阅的创建时间(timestamptz 是一种支持时区的日期和时间类型)
- 我们使用 UNIQUE 约束在数据库级别强制确保电子邮件的唯一性
- 我们强制所有字段的每一列都应使用 NOT NULL 约束进行填充
- 我们使用 TEXT 格式来表示电子邮件和姓名,因为我们对它们的最大长度没有任何限制
数据库约束是防止应用程序错误的最后一道防线,但它是有代价的——数据库必须确保所有检查都通过后才能将新数据写入表。因此,约束会影响我们的写入吞吐量,即单位时间内我们可以在表中插入/更新的行数。
特别是 UNIQUE 约束,它会在我们的电子邮件列上引入一个额外的 BTree 索引:该索引必须在每次执行 INSERT/UPDATE/DELETE 查询时更新,而且会占用磁盘空间。
就我们的具体情况而言,我不会太担心: 我们的邮件列表必须非常受欢迎,才会遇到写入吞吐量的问题。如果真的遇到这个问题,那绝对是个好事。
运行迁移
我们可以使用以下方法对数据库进行迁移:
sqlx migrate run
它的行为与 sqlx database create 相同——它会查看 DATABASE_URL 环境变量,以了解需要迁移的数据库。
让我们将它添加到 scripts/init_db.sh 脚本中:
#!/usr/bin/env bash
set -x
set -eo pipefail
if ! [ -x "$(command -v psql)" ]; then
echo >&2 "Error: psql is not installed."
exit 1
fi
if ! [ -x "$(command -v sqlx)" ]; then
echo >&2 "Error: sqlx is not installed."
echo >&2 "Use:"
echo >&2 "
cargo install --version=0.5.7 sqlx-cli --no-default-features --features postgres"
echo >&2 "to install it."
exit 1
fi
# Check if a custom user has been set, otherwise default to 'postgres'
DB_USER=${POSTGRES_USER:=postgres}
# Check if a custom password has been set, otherwise default to 'password'
DB_PASSWORD="${POSTGRES_PASSWORD:=password}"
# Check if a custom database name has been set, otherwise default to 'newsletter'
DB_NAME="${POSTGRES_DB:=newsletter}"
# Check if a custom port has been set, otherwise default to '5432'
DB_PORT="${POSTGRES_PORT:=5432}"
if [[ -z "${SKIP_DOCKER}" ]]
then
# Launuh postgrecs sing Docker
docker run \
-e POSTGRES_USER=${DB_USER} \
-e POSTGRES_PASSWORD=${DB_PASSWORD} \
-e POSTGRES_DB=${DB_NAME} \
-p "${DB_PORT}":5432 \
-d postgres \
postgres -N 1000
# ^ Increased maximum number of connections for testing purposes
fi
# Keep pinging Postgres until it's ready to accept commands
export PGPASSWORD="${DB_PASSWORD}"
until psql -h "localhost" -U "${DB_USER}" -p "${DB_PORT}" -d "postgres" -c '\q'; do
>&2 echo "Postgres is still unavailable - sleeping"
sleep 1
done
>&2 echo "Postgres is up and running on port ${DB_PORT}!"
export DATABASE_URL=postgres://${DB_USER}:${DB_PASSWORD}@localhost:${DB_PORT}/${DB_NAME}
sqlx database create
sqlx migrate run
注意在这里我们进行了两处修改, 一处是文件末尾的 sqlx migrate run 另外一处是对 SKIP_DOCKER 环境变量的判断
我们将 docker run 命令置于 SKIP_DOCKER 标志之后,以便轻松针对现有 Postgres 实例运行迁移,而无需手动将其关闭并使用 scripts/init_db.sh 重新创建。如果我们的脚本未启动 Postgres,此命令在 CI 中也非常有用。
现在,我们可以使用以下命令迁移数据库
SKIP_DOCKER=true ./scripts/init_db.sh
您应该能够在输出中发现类似这样的内容
+ sqlx migrate run
如果您使用您最喜欢的 Postgres GUI 检查数据库,您现在会看到一个 subscriptions 表,旁边还有一个全新的 _sqlx_migrations 表: 这是 sqlx 跟踪针对您的数据库运行了哪些迁移的地方——现在它应该包含一行,用于记录我们的 create_subscriptions_table 迁移。
编写我们的第一个查询
我们已迁移并运行数据库。该如何与它通信?
Sqlx Feature Flags
我们安装了 sqlx-cli,但实际上还没有将 sqlx 本身添加为我们应用程序的依赖项。
我们在 Cargo.toml 中添加一行新代码:
[dependencies.sqlx]
version = "0.8.6"
default-features = false
features = [
"tls-rustls",
"macros",
"postgres",
"uuid",
"chrono",
"migrate",
"runtime-tokio"
]
是的,有很多功能开关。让我们逐一介绍一下:
tls-rustls指示 sqlx 使用 actix 运行时作为其 Future,并使用 rustls 作为 TLS 后端;macros允许我们访问 sqlx::query! 和 sqlx::query_as!,我们将会广泛使用它们;postgres解锁 Postgres 特有的功能(例如非标准 SQL 类型);uuid增加了将 SQL UUID 映射到 uuid crate 中的 Uuid 类型的支持。我们需要它来处理我们的 id 列;chrono增加了将 SQL timestamptz 映射到 chrono cratev 中的DateTime<T>类型的支持。我们需要它来处理我们的 subscribed_at 列;migrate允许我们访问 sqlx-cli 后台用来管理迁移的相同函数。事实证明,它对我们的测试套件很有用。 这些应该足够我们完成本章所需的工作了。
配置管理
连接到 Postgres 数据库最简单的入口点是 PgConnection。
PgConnection 实现了 Connection trait,它为我们提供了一个 connect 方法:
它接受连接字符串作为输入,并异步返回一个 Result<PostgresConnection,sqlx::Error> 。
我们从哪里获取连接字符串?
我们可以在应用程序中硬编码一个连接字符串,然后将其用于测试。
或者,我们可以选择立即引入一些基本的配置管理机制。
这比听起来简单,而且可以节省我们在整个应用程序中追踪一堆硬编码值的成本。
config crate 是 Rust 配置方面的“瑞士军刀”:它支持多种文件格式,并允许您分层组合不同的源(例如环境变量、配置文件等),从而轻松地根据每个部署环境定制应用程序的行为。
我们暂时不需要任何花哨的东西: 一个配置文件就可以了。
腾出空间
目前,我们所有的应用程序代码都位于一个文件 lib.rs 中。
为了避免在添加新功能时造成混乱,我们需要快速将其拆分成多个子模块。我们希望采用以下文件夹结构:
src/
├── configuration.rs
├── lib.rs
├── main.rs
├── routes
│ ├── health_check.rs
│ └── subscriptions.rs
├── routes.rs
└── startup.rs
lib.rs 看起来是这样
//! src/lib.rs
pub mod configuration;
pub mod routes;
pub mod startup;
startup.rs 将包含我们的运行函数, health_check 函数存放在 routes/health_check.rs 中, subscribe 和 FormData 函数存放在 routes/subscriptions.rs 中,
configuration.rs 初始为空。这两个处理程序都重新导出到 routes.rs 中:
//! /src/routes.rs
mod health_check;
mod subscriptions;
pub use health_check::*;
pub use subscriptions::*;
您可能需要添加一些 pub 可见性修饰符, 以及对 main.rs 和 tests/health_check.rs 中的 use 语句进行一些修正。
请确保 cargo test 通过, 然后再继续下一步。
读取配置文件
要使用 config 管理配置,我们必须将应用程序设置表示为实现 serde 的 Deserialize trait 的 Rust 类型。
让我们创建一个新的 Settings struct:
//! src/configuration.rs
#[derive(serde::Deserialize)]
pub struct Settings {}
目前我们有两组配置值:
- 应用程序端口,actix-web 监听传入请求(目前在 main.rs 中硬编码为 8000)
- 数据库连接参数
让我们在“设置”中为每个配置值添加一个字段:
#[derive(serde::Deserialize)]
pub struct Settings {
pub database: DatabaseSettings,
pub application_port: u16
}
#[derive(serde::Deserialize)]
pub struct DatabaseSettings {
pub username: String,
pub password: String,
pub port: u16,
pub host: String,
pub database_name: String,
}
我们需要在 DatabaseSettings 之上添加 #[derive(serde::Deserialize)], 否则编译器会报错
error[E0277]: the trait bound `DatabaseSettings: configuration::_::_serde::Deserialize<'_>` is not satisfied
--> src/configuration.rs:3:19
|
3 | pub database: DatabaseSettings,
| ^^^^^^^^^^^^^^^^ the trait `configuration::_::_serde::Deserialize<'_>` is not implemented for `DatabaseSettings`
|
这是有道理的: 为了使整个类型可反序列化,类型中的所有字段都必须可反序列化。
我们有配置类型了,接下来做什么?
首先, 让我们使用以下命令将配置添加到依赖项中
cargo add config
我们想从名为 configuration 的配置文件中读取我们的应用程序设置:
pub fn get_configuration() -> Result<Settings, config::ConfigError> {
let settings = config::Config::builder()
// Add configuration values from a file named `configuration`.
// It will look for any top-level file with an extension
// that `config` knows how to parse: yaml, json, etc.
.add_source(config::File::with_name("configuration"))
.build()
.unwrap();
// Try to convert the configuration values it read into
// our Settings type
settings.try_deserialize()
}
让我们修改 main 方法 以读取配置作为第一步:
//! src/main.rs
use std::net::TcpListener;
use zero2prod::{configuration::get_configuration, run};
#[tokio::main]
async fn main() -> std::io::Result<()> {
let configuration = get_configuration().expect("Failed to read config");
let address = format!("0.0.0.0:{}", configuration.application_port);
let listener = TcpListener::bind(address)?;
run(listener)?.await
}
如果这时候尝试运行 cargo run 会崩溃
thread 'main' panicked at src/configuration.rs:20:10:
called `Result::unwrap()` on an `Err` value: configuration file "configuration" not found
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
让我们写一个配置文件来修复这个问题
我们可以使用任何文件格式,只要 config crate 知道如何处理它: 我们将选择 YAML。
# configuration.yaml
application_port: 8000
database:
host: "127.0.0.1"
port: 5432
username: "postgres"
password: "password"
database_name: "newsletter"
cargo run 现在应该可以顺利执行了。
连接到 Postgres
PgConnection::connect 需要单个连接字符串作为输入, 而 DatabaseSettings 则提供了对所有连接参数的精细访问。
让我们添加一个便捷的 connection_string 方法来做到这一点:
//! src/configuration.rs
// [...]
impl DatabaseSettings {
pub fn connection_string(&self) -> String {
format!(
"postgres://{}:{}@{}:{}/{}",
self.username, self.password, self.host, self.port, self.database_name
)
}
}
我们终于可以连接了!
让我们调整一下正常情况下的测试:
use sqlx::{Connection, PgConnection};
use zero2prod::configuration::get_configuration;
#[tokio::test]
async fn subscribe_returns_a_200_for_valid_form_data() {
// Arrange
let app_address = spawn_app();
let configuration = get_configuration().expect("Failed to read configuration");
let connection_string = configuration.database.connection_string();
// The `Connection` trait MUST be in scope for us to invoke
// `PgConnection::connect` - it is not an inherent method of the struct!
let connection = PgConnection::connect(&connection_string)
.await
.expect("Failed to connect to Postgres.");
let client = reqwest::Client::new();
// Act
let body = "name=le%20guin&email=ursula_le_guin%40gmail.com";
let response = client
.post(&format!("{}/subscriptions", &app_address))
.header("Content-Type", "application/x-www-form-urlencoded")
.body(body)
.send()
.await
.expect("Failed to execute request.");
// Assert
assert_eq!(200, response.status().as_u16());
}
而且... cargo test 通过了!
我们刚刚确认, 测试结果显示我们能够成功连接到 Postgres!
对于世界来说,这是一小步,而对于我们来说,却是一大步。
我们的测试断言
现在我们已经连接上了,终于可以编写测试断言了。
我们之前 10 页一直梦想着这些断言。
我们将使用 sqlx 的 query! 宏:
#[tokio::test]
async fn subscribe_returns_a_200_for_valid_form_data() {
// [...]
// The connection has to be marked as mutable!
let mut connection = PgConnection::connect(&connection_string)
.await
.expect("Failed to connect to Postgres.");
// [...]
// Assert
assert_eq!(200, response.status().as_u16());
let saved = sqlx::query!("SELECT email, name FROM subscriptions",)
.fetch_one(&mut connection)
.await
.expect("Failed to fetch saved subscription.");
assert_eq!(saved.email, "ursula_le_guin@gmail.com");
assert_eq!(saved.name, "le guin");
}
saved 的类型是什么? query! 宏返回一个匿名记录类型: 在编译时验证查询有效后,会生成一个结构体定义,其结果中的每个列都有一个成员 (例如, email 列对应的是 saved.email)。
如果我们尝试运行 cargo test, 将会报错:
error: set `DATABASE_URL` to use query macros online, or run `cargo sqlx prepare` to update the query cache
--> tests/health_check.rs:52:17
|
52 | let saved = sqlx::query!("SELECT email, name FROM subscriptions",)
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: this error originates in the macro `$crate::sqlx_macros::expand_query` which comes from the expansion of the macro `sqlx::query` (in Nightly builds, run with -Z macro-backtrace for more inf
o)
error: could not compile `zero2prod` (test "health_check") due to 1 previous error
正如我们之前讨论过的,sqlx 在编译时会联系 Postgres 来检查查询是否格式正确。就像 sqlx-cli 命令一样,它依赖 DATABASE_URL 环境变量来获取数据库的地址。
我们可以手动导出 DATABASE_URL, 但每次启动机器并开始处理这个项目时,都会遇到同样的问题。我们不妨参考 sqlx 作者的建议——添加一个顶层 .env 文件。
DATABASE_URL="postgres://postgres:password@localhost:5432/newsletter"
sqlx 会从中读取 DATABASE_URL, 省去了我们每次都重新导出环境变量的麻烦。
数据库连接参数放在两个地方 (.env 和
configuration.yaml) 感觉有点麻烦,但这不是什么大问题: configuration.yaml 可以用来
在应用程序编译后更改其运行时行为,而 .env 只与我们的开发流程、构建和测试步骤相关。
将 .env 文件提交到版本控制——我们很快就会在持续集成 (CI) 中用到它!
让我们再次尝试运行 cargo test:
running 3 tests
test health_check_works ... ok
test subscribe_returns_a_400_when_data_is_missing ... ok
test subscribe_returns_a_200_for_valid_form_data ... FAILED
failures:
---- subscribe_returns_a_200_for_valid_form_data stdout ----
thread 'subscribe_returns_a_200_for_valid_form_data' panicked at tests/health_check.rs:55:10:
Failed to fetch saved subscription.: RowNotFound
它失败了,这正是我们想要的!
现在我们可以专注于修补应用程序,让它恢复正常。
更新 CI 流
如果你检查一下,你会发现你的 CI 流现在无法执行我们在开始时引入的大多数检查。
我们的测试现在依赖于正在运行的 Postgres 数据库才能正确执行。由于 sqlx 的编译时检查,我们所有的构建命令 (cargo check、cargo lint、cargo build )都需要一个正常运行的数据库!
我们不想再冒险使用一个损坏的 CI。
您可以在这里找到 GitHub Actions 设置的更新版本。只需更新 general.yml 文件即可。
持久化新订阅者
就像我们在测试中编写了 SELECT 查询来检查哪些订阅已持久保存到数据库中一样,现在我们需要编写 INSERT 查询,以便在收到有效的 POST /subscriptions 请求时实际存储新订阅者的详细信息。
让我们看看我们的handler:
use actix_web::{HttpResponse, web};
#[derive(serde::Deserialize)]
pub struct FormData {
email: String,
name: String,
}
pub async fn subscribe(_form: web::Form<FormData>) -> HttpResponse {
HttpResponse::Ok().finish()
}
要在 subscribe 中执行查询,我们需要获取数据库connection。
让我们来看看如何获取。
actix-web 中的应用程序状态
到目前为止,我们的应用程序完全是无状态的:我们的处理程序仅处理来自传入请求的数据。
actix-web 让我们能够将与单个传入请求的生命周期无关的其他数据附加到应用程序 - 即所谓的应用程序状态。
您可以使用 App 上的 app_data 方法向应用程序状态添加信息。
让我们尝试使用 app_data 将 PgConnection 注册为应用程序状态的一部分。我们需要修改 run 方法,使其与 TcpListener 一起接受 PgConnection:
//! src/startup.rs
use std::net::TcpListener;
use actix_web::{dev::Server, web, App, HttpServer};
use sqlx::PgConnection;
use crate::routes::{health_check, subscribe};
pub fn run(
listener: TcpListener,
// New parameter!
connection: PgConnection,
) -> Result<Server, std::io::Error> {
let server = HttpServer::new(|| {
App::new()
.route("/health_check", web::get().to(health_check))
.route("/subscriptions", web::post().to(subscribe))
.app_data(connection)
})
.listen(listener)?
.run();
Ok(server)
}
这不能真正工作, cargo check 提示如下信息
error[E0277]: the trait bound `PgConnection: Clone` is not satisfied in `{closure@src/startup.rs:13
:34: 13:36}`
--> src/startup.rs:13:18
|
13 | let server = HttpServer::new(|| {
| ^^^^^^^^^^ -- within this `{closure@src/startup.rs:13:34: 13:36}`
| |
| unsatisfied trait bound
|
= help: within `{closure@src/startup.rs:13:34: 13:36}`, the trait `Clone` is not implemented for
`PgConnection`
note: required because it's used within this closure
--> src/startup.rs:13:34
|
13 | let server = HttpServer::new(|| {
| ^^
note: required by a bound in `HttpServer`
--> /home/cubewhy/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/actix-web-4.11.0/src/serve
r.rs:72:27
|
70 | pub struct HttpServer<F, I, S, B>
| ---------- required by a bound in this struct
71 | where
72 | F: Fn() -> I + Send + Clone + 'static,
| ^^^^^ required by this bound in `HttpServer`
For more information about this error, try `rustc --explain E0277`.
HttpServer 期望 PgConnection 可克隆, 但不幸的是, 事实并非如此。
为什么它首先需要实现 Clone trait呢?
actix-web Workers
让我们放大对 HttpServer::new 的调用:
let server = HttpServer::new(|| {
App::new()
.route("/health_check", web::get().to(health_check))
.route("/subscriptions", web::post().to(subscribe))
})
HttpServer::new 不接受 App 作为参数——它需要一个返回 App 结构体的闭包。
这是为了支持 actix-web 的运行时模型:actix-web 会为您机器上的每个可用核心启动一个工作进程。
每个工作进程都运行由 HttpServer 构建的应用程序副本,并调用 HttpServer::new 作为参数的同一个闭包。 这就是为什么连接必须是可克隆的——我们需要为每个 App 副本创建一个连接。
但是,正如我们所说,PgConnection 没有实现 Clone 接口,因为它位于一个不可克隆的系统资源之上,即与 Postgres 的 TCP 连接。我们该怎么办?
我们可以使用另一个 actix-web 提取器 web::Data。
web::Data 将我们的连接包装在一个原子引用计数指针 Arc 中:应用程序的每个实例都将获得一个指向 PgConnection 的指针,而不是获取 PgConnection 的原始副本。
Arc<T> 始终可克隆,无论 T 是什么:克隆 Arc 会增加活动引用的数量,并移交包装值内存地址的拷贝。
然后,处理程序可以使用相同的提取器访问应用程序状态。
让我们试一下:
//! src/startup.rs
use std::net::TcpListener;
use actix_web::{dev::Server, web, App, HttpServer};
use sqlx::PgConnection;
use crate::routes::{health_check, subscribe};
pub fn run(
listener: TcpListener,
// New parameter!
connection: PgConnection,
) -> Result<Server, std::io::Error> {
let connection = web::Data::new(connection);
let server = HttpServer::new(move || {
App::new()
.route("/health_check", web::get().to(health_check))
.route("/subscriptions", web::post().to(subscribe))
.app_data(connection.clone())
})
.listen(listener)?
.run();
Ok(server)
}
它还不能编译,但我们只需要做一些整理工作:
error[E0061]: this function takes 2 arguments but 1 argument was supplied
--> tests/health_check.rs:96:18
|
96 | let server = zero2prod::run(listener).expect("Failed to bind address");
| ^^^^^^^^^^^^^^---------- argument #2 of type `PgConnection` is missing
|
让我们快速修复这个问题:
//! src/main.rs
use std::net::TcpListener;
use sqlx::{Connection, PgConnection};
use zero2prod::{configuration::get_configuration, run};
#[tokio::main]
async fn main() -> std::io::Result<()> {
let configuration = get_configuration().expect("Failed to read config");
let connection = PgConnection::connect(&configuration.database.connection_string())
.await
.expect("Failed to connect to Postgres.");
let address = format!("0.0.0.0:{}", configuration.application_port);
let listener = TcpListener::bind(address)?;
run(listener, connection)?.await
}
完美,编译通过。
Data Extractor
现在, 我们可以在请求处理程序中获取 Arc<PgConnection> 了,订阅时可以使用 web::Data Extractor:
//! src/routes/subscriptions.rs
use actix_web::{HttpResponse, web};
use sqlx::PgConnection;
// [...]
pub async fn subscribe(
_form: web::Form<FormData>,
_connection: web::Data<PgConnection>,
) -> HttpResponse {
HttpResponse::Ok().finish()
}
我们将 Data 称为提取器,但它究竟是从哪里提取 PgConnection 的呢?
actix-web 使用类型映射来表示其应用程序状态:一个 HashMap, 存储任意数据 (使用 Any 类型) 及其唯一类型标识符 (通过 TypeId::of 获取)。
当新请求到来时, web::Data 会计算您在签名中指定的类型 (在我们的例子中是 PgConnection) 的 TypeId,并检查类型映射中是否存在与其对应的记录。如果有,它会将检索到的 Any 值转换为您指定的类型(TypeId 是唯一的, 无需担心), 并将其传递给您的处理程序。
这是一种有趣的技术,可以执行在其他语言生态系统中可能被称为依赖注入的操作。
INSERT 查询
我们终于在 subscribe 中建立了连接: 让我们尝试持久化新订阅者的详细信息。
我们将再次使用在快乐测试中用过的 query! 宏。
//! src/routes/subscriptions.rs
// [...]
use uuid::Uuid;
use chrono::Utc;
// [...]
pub async fn subscribe(
form: web::Form<FormData>,
connection: web::Data<PgConnection>,
) -> HttpResponse {
sqlx::query!(
r#"
INSERT INTO subscriptions (id, email, name, subscribed_at)
VALUES ($1, $2, $3, $4)
"#,
Uuid::new_v4(),
form.email,
form.name,
Utc::now()
)
.execute(connection.get_ref())
.await;
HttpResponse::Ok().finish()
}
让我们来剖析一下发生了什么:
- 我们将动态数据绑定到 INSERT 查询。$1 表示查询本身之后传递给
query!的第一个参数, $2 表示第二个参数,依此类推。query!在编译时会验证 提供的参数数量是否与查询预期相符,以及它们的 类型是否兼容 (例如,不能将数字作为 id 传递) - 我们为 id 生成一个随机的 Uuid
- 我们为 subscribed_at 使用 UTC 时区的当前时间戳
我们还必须在 Cargo.toml 中添加两个新的依赖项来修复明显的编译器错误:
cargo add uuid --features=v4
cargo add chrono
如果我们尝试再次编译它会发生什么?
error[E0277]: the trait bound `&PgConnection: Executor<'_>` is not satisfied
--> src/routes/subscriptions.rs:27:6
|
27 | .await;
| ^^^^^ the trait `Executor<'_>` is not implemented for `&PgConnection`
|
= help: the trait `Executor<'_>` is not implemented for `&PgConnection`
but it is implemented for `&mut PgConnection`
= note: `Executor<'_>` is implemented for `&mut PgConnection`, but not for `&PgConnection`
execute 需要一个实现 sqlx 的 Executor trait 的参数,事实证明, 正如我们在测试中编写的查询中所记得的那样, &PgConnection 并没有实现 Executor - 只有 &mut PgConnection 实现了。
为什么会这样? sqlx 有一个异步接口,但它不允许你在同一个数据库连接上并发运行多个查询。
要求可变引用允许他们在 API 中强制执行此保证。你可以将可变引用视为唯一引用:编译器保证执行时确实拥有对该 PgConnection 的独占访问权,因为在整个程序中不可能同时存在两个指向相同值的活跃可变引用。相当巧妙。
尽管如此,这看起来像是我们把自己设计成了一个死胡同: web::Data 永远不会给我们提供对应用程序状态的可变访问权限。
我们可以利用内部可变性——例如,将我们的 PgConnection 置于锁(例如 Mutex)之后, 这将允许我们同步对底层 TCP 套接字的访问,并在获取锁后获得对包装连接的可变引用。
我们可以让它工作,但这并不理想:我们被限制一次最多只能运行一个查询。这不太好。
让我们再看一下 sqlx 的 Executor trait的文档: 除了 &mut PgConnection 之外,还有什么实现了 Executor?
Bingo: 对 PgPool 的共享引用。
PgPool 是一个 Postgres 数据库连接池。它是如何绕过我们刚刚讨论过的 PgConnection 的并发问题的?
内部仍然有可变性,但类型不同:当你对
&PgPool 运行查询时,sqlx 会从池中借用一个 PgConnection 并用它来执行查询;如果没有可用的连接,它会创建一个新的或等待直到有连接释放。
这增加了我们的应用程序可以运行的并发查询数量,并提高了其弹性: 单个慢查询不会通过在连接锁上创建争用而影响所有传入请求的性能。
让我们重构运行、主函数和订阅函数来使用 PgPool 而不是单个 PgConnection:
//! src/main.rs
use std::net::TcpListener;
use sqlx::{Connection, PgPool};
use zero2prod::{configuration::get_configuration, run};
#[tokio::main]
async fn main() -> std::io::Result<()> {
let configuration = get_configuration().expect("Failed to read config");
// Renamed!
let connection_pool = PgPool::connect(&configuration.database.connection_string())
.await
.expect("Failed to connect to Postgres.");
let address = format!("0.0.0.0:{}", configuration.application_port);
let listener = TcpListener::bind(address)?;
run(listener, connection_pool)?.await
}
//! src/startup.rs
use std::net::TcpListener;
use actix_web::{dev::Server, web, App, HttpServer};
use sqlx::PgPool;
use crate::routes::{health_check, subscribe};
pub fn run(
listener: TcpListener,
db_pool: PgPool,
) -> Result<Server, std::io::Error> {
let db_pool = web::Data::new(db_pool);
let server = HttpServer::new(move || {
App::new()
.route("/health_check", web::get().to(health_check))
.route("/subscriptions", web::post().to(subscribe))
.app_data(db_pool.clone())
})
.listen(listener)?
.run();
Ok(server)
}
//! src/routes/subscriptions.rs
// No longer importing PgConnection!
use sqlx::PgPool;
// [...]
pub async fn subscribe(
form: web::Form<FormData>,
pool: web::Data<PgPool>, // Renamed!
) -> HttpResponse {
sqlx::query!(
/* [...] */
)
.execute(pool.get_ref())
.await;
HttpResponse::Ok().finish()
}
编译器几乎很高兴: cargo check 向我们发出了警告。
warning: unused `Result` that must be used
--> src/routes/subscriptions.rs:16:5
|
16 | / sqlx::query!(
17 | | r#"
18 | | INSERT INTO subscriptions (id, email, name, subscribed_at)
19 | | VALUES ($1, $2, $3, $4)
... |
26 | | .execute(pool.get_ref())
27 | | .await;
| |__________^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
sqlx::query 可能会失败——它返回一个 Result, 这是 Rust 对易错函数建模的方式。
编译器提醒我们处理错误情况——让我们遵循以下建议:
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(
form: web::Form<FormData>,
pool: web::Data<PgPool>, // Renamed!
) -> HttpResponse {
match sqlx::query!(
r#"
INSERT INTO subscriptions (id, email, name, subscribed_at)
VALUES ($1, $2, $3, $4)
"#,
Uuid::new_v4(),
form.email,
form.name,
Utc::now()
)
.execute(pool.get_ref())
.await
{
Ok(_) => HttpResponse::Ok().finish(),
Err(e) => {
println!("Failed to execute query: {e}");
HttpResponse::InternalServerError().finish()
}
}
}
cargo check 满足要求,但 cargo test 却不能满足要求:
error[E0061]: this function takes 2 arguments but 1 argument was supplied
--> tests/health_check.rs:96:18
|
96 | let server = zero2prod::run(listener).expect("Failed to bind address");
| ^^^^^^^^^^^^^^---------- argument #2 of type `Pool<Postgres>` is missing
|
更新我们的测试
错误出在我们的 spawn_app 辅助函数中:
fn spawn_app() -> String {
let listener = TcpListener::bind("127.0.0.1:0").expect("Faield to bind random port");
// We retrieve the port assigned to us by the OS
let port = listener.local_addr().unwrap().port();
let server = zero2prod::run(listener).expect("Failed to bind address");
let _ = tokio::spawn(server);
// We return the application address to the caller!
format!("http://127.0.0.1:{}", port)
}
我们需要传递一个连接池来运行。
考虑到我们接下来在 subscribe_returns_a_200_for_valid_form_data 中需要用到这个连接池来执行 SELECT 查询,因此可以对 spawn_app 进行泛化: 我们不会返回原始字符串,而是会给调用者一个结构体 TestApp。TestApp 将保存测试应用程序实例的地址和连接池的句柄,从而简化测试用例的配置步骤。
//! tests/health_check.rs
use std::net::TcpListener;
use sqlx::{Connection, PgConnection, PgPool};
use zero2prod::configuration::get_configuration;
pub struct TestApp {
pub address: String,
pub db_pool: PgPool,
}
async fn spawn_app() -> TestApp {
let listener = TcpListener::bind("127.0.0.1:0").expect("Faield to bind random port");
// We retrieve the port assigned to us by the OS
let port = listener.local_addr().unwrap().port();
let address = format!("http://127.0.0.1:{}", port);
let configuration = get_configuration().expect("");
let connection_pool = PgPool::connect(&configuration.database.connection_string())
.await
.expect("Failed to connect to Postgres");
let server = zero2prod::run(listener, connection_pool.clone()).expect("Failed to bind address");
let _ = tokio::spawn(server);
TestApp {
address,
db_pool: connection_pool,
}
}
所有测试用例都必须进行相应的更新——这个屏幕外的练习,我留给你了,亲爱的读者。
让我们一起来看看 subscribe_returns_a_200_for_valid_form_data 在完成必要的更改后是什么样子的:
//! tests/health_check.rs
// [...]
#[tokio::test]
async fn subscribe_returns_a_200_for_valid_form_data() {
// Arrange
let app = spawn_app().await;
let app_address = app.address.as_str();
let client = reqwest::Client::new();
// Act
let body = "name=le%20guin&email=ursula_le_guin%40gmail.com";
let response = client
.post(&format!("{}/subscriptions", &app_address))
.header("Content-Type", "application/x-www-form-urlencoded")
.body(body)
.send()
.await
.expect("Failed to execute request.");
// Assert
assert_eq!(200, response.status().as_u16());
let saved = sqlx::query!("SELECT email, name FROM subscriptions",)
.fetch_one(&app.db_pool)
.await
.expect("Failed to fetch saved subscription.");
assert_eq!(saved.email, "ursula_le_guin@gmail.com");
assert_eq!(saved.name, "le guin");
}
现在, 我们去掉了大部分与建立数据库连接相关的样板代码, 测试意图更加清晰了。
TestApp 是我们未来构建的基础, 我们将在此基础上开发出对大多数集成测试都有用的支持功能。
关键时刻终于到来了: 我们更新后的订阅实现是否足以让 subscribe_returns_a_200_for_valid_form_data 测试通过?
running 3 tests
test health_check_works ... ok
test subscribe_returns_a_400_when_data_is_missing ... ok
test subscribe_returns_a_200_for_valid_form_data ... ok
Yesssssssss!
成功了!
让我们再次奔跑,沐浴在这辉煌时刻的光芒之中!
cargo test
running 3 tests
test health_check_works ... ok
test subscribe_returns_a_400_when_data_is_missing ... ok
test subscribe_returns_a_200_for_valid_form_data ... FAILED
failures:
---- subscribe_returns_a_200_for_valid_form_data stdout ----
Failed to execute query: error returned from database: duplicate key value violates unique constrai
nt "subscriptions_email_key"
thread 'subscribe_returns_a_200_for_valid_form_data' panicked at tests/health_check.rs:45:5:
assertion `left == right` failed
left: 200
right: 500
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
subscribe_returns_a_200_for_valid_form_data
test result: FAILED. 2 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.07s
等等,不,搞什么鬼! 别这样对我们!
好吧,我撒谎了——我就知道会发生这种事。
对不起,我让你尝到了胜利的甜蜜滋味,然后又把你扔回了泥潭。
相信我,这里有一个重要的教训需要吸取。
测试隔离
您的数据库是一个巨大的全局变量:所有测试都与其交互,并且它们留下的任何数据都将对套件中的其他测试以及后续测试运行可用。
这正是我们刚才发生的事情:我们的第一次测试运行命令我们的应用程序注册一个邮箱地址为 ursula_le_guin@gmail.com 的新用户;应用程序执行了命令。
当我们重新运行测试套件时,我们再次尝试使用相同的邮箱地址执行另一个 INSERT 操作, 但是, 我们对邮箱列的 UNIQUE 约束引发了唯一键冲突并拒绝了查询, 导致应用程序返回 500 INTERNAL_SERVER_ERROR 错误。
您真的不希望测试之间有任何形式的交互:这会使您的测试运行变得不确定,并最终导致虚假的测试失败,而这些失败极难排查和修复。
据我所知,在测试中与关系数据库交互时,有两种技术可以确保测试隔离性:
- 将整个测试包装在 SQL 事务中,并在事务结束时回滚;
- 为每个集成测试启动一个全新的逻辑数据库。
第一种方法很巧妙,通常速度更快:回滚 SQL 事务比启动新的逻辑数据库所需的时间更少。在为查询编写单元测试时,这种方法效果很好,但在像我们这样的集成测试中,实现起来比较棘手:我们的应用程序将从 PgPool 借用一个 PgConnection,而我们无法在 SQL 事务上下文中“捕获”该连接。
这就引出了第二种方案:可能速度更慢,但实现起来更容易。
如何实现?
在每次测试运行之前,我们需要:
- 创建一个具有唯一名称的新逻辑数据库;
- 在其上运行数据库迁移。
执行此操作的最佳位置是 spawn_app,在启动我们的 actix-web 测试应用程序之前。
让我们再看一下:
// [...]
pub struct TestApp {
pub address: String,
pub db_pool: PgPool,
}
async fn spawn_app() -> TestApp {
let listener = TcpListener::bind("127.0.0.1:0").expect("Faield to bind random port");
let port = listener.local_addr().unwrap().port();
let address = format!("http://127.0.0.1:{}", port);
let configuration = get_configuration().expect("");
let connection_pool = PgPool::connect(&configuration.database.connection_string())
.await
.expect("Failed to connect to Postgres");
let server = zero2prod::run(listener, connection_pool.clone()).expect("Failed to bind address");
let _ = tokio::spawn(server);
TestApp {
address,
db_pool: connection_pool,
}
}
configuration.database.connection_string() 使用我们在 configuration.yaml 文件中指定的数据库名称 - 所有测试都相同。
让我们将其随机化
let mut configuration = get_configuration().expect("");
configuration.database.database_name = Uuid::new_v4().to_string();
cargo test 将会失败: 没有数据库准备好使用我们生成的名称来接受连接。
让我们在 DatabaseSettings 中添加一个 connection_string_without_db 方法:
//! src/configuration.rs
// [...]
impl DatabaseSettings {
pub fn connection_string(&self) -> String {
format!(
"postgres://{}:{}@{}:{}/{}",
self.username, self.password, self.host, self.port, self.database_name
)
}
pub fn connection_string_without_db(&self) -> String {
format!(
"postgres://{}:{}@{}:{}",
self.username, self.password, self.host, self.port
)
}
}
省略数据库名称,我们连接到 Postgres 实例, 而不是特定的逻辑数据库。
现在我们可以使用该连接创建所需的数据库并在其上运行迁移:
//! tests/health_check.rs
// [...]
use sqlx::Executor;
// [...]
async fn spawn_app() -> TestApp {
// [...]
let mut configuration = get_configuration().expect("");
configuration.database.database_name = Uuid::new_v4().to_string();
let connection_pool = configure_database(&configuration.database).await;
// [...]
}
pub async fn configure_database(config: &DatabaseSettings) -> PgPool {
// Create database
let mut connection = PgConnection::connect(&config.connection_string_without_db())
.await
.expect("Failed to connect to Postgres");
connection
.execute(format!(r#"CREATE DATABASE "{}";"#, config.database_name).as_str())
.await
.expect("Failed to create database.");
// Migrate database
let connection_pool = PgPool::connect(&config.connection_string())
.await
.expect("Failed to connect to Postgres");
sqlx::migrate!("./migrations")
.run(&connection_pool)
.await
.expect("Failed to migrate the database");
connection_pool
}
sqlx::migrate! 与 sqlx-cli 在执行 sqlx migration run 时使用的宏相同——无需
再添加 Bash 脚本即可达到相同的效果。
让我们再次尝试运行 cargo test:
running 3 tests
test subscribe_returns_a_400_when_data_is_missing ... ok
test health_check_works ... ok
test subscribe_returns_a_200_for_valid_form_data ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.23s
这次成功了,而且是永久性的。
您可能已经注意到,我们在测试结束时没有执行任何清理步骤——我们创建的逻辑数据库不会被删除。这是有意为之: 我们可以添加清理步骤,但我们的 Postgres 实例仅用于测试目的,如果在数百次测试运行之后,由于大量残留(几乎为空)数据库而导致性能下降,重启它很容易。
小结
本章涵盖了大量主题: actix-web 提取器和 HTML 表单、 使用 serde 进行序列化/反序列化、Rust 生态系统中可用数据库 crate 的概述、sqlx 的基础知识以及在处理数据库时确保测试隔离的基本技术。
请花时间消化这些内容,并在必要时回头复习各个章节。
遥测
在第三章中,我们成功地完成了 POST /订阅的第一个实现,以完成我们电子邮件通讯项目的一个用户故事:
作为博客访问者, 我想订阅新闻简报, 以便在博客发布新内容时收到电子邮件更新
我们尚未创建包含 HTML 表单的网页来实际测试端到端流程,但我们已进行了一些黑盒集成测试,涵盖了现阶段我们关注的两种基本场景:
- 如果提交了有效的表单数据(即同时提供了姓名和电子邮件),则数据将保存在我们的数据库中
- 如果提交的表单不完整(例如,缺少电子邮件、姓名或两者兼而有之),则 API 将返回 400 错误。
我们应该满足于现状,急于将应用程序的第一个版本部署到最酷的云服务提供商上吗?
还不行——我们还没有能力在生产环境中正常运行我们的软件。 我们对此一无所知:应用程序尚未进行检测,我们也没有收集任何遥测数据,这让我们容易受到未知因素的影响。
如果您对上一句话的大部分内容感到困惑,请不要担心:彻底弄清楚这个问题将是本章的重点。
未知的未知
我们进行了一些测试。测试固然重要,它们能让我们对自己的软件及其正确性更有信心。
然而,测试套件并不能证明我们应用程序的正确性。我们必须探索截然不同的方法来证明某些东西是正确的(例如形式化方法)。
在运行时,我们会遇到一些在设计应用程序时从未测试过,甚至从未考虑过的场景。
根据我们迄今为止所做的工作以及我过去的经验,我可以指出一些盲点:
- 如果数据库连接断开会发生什么?sqlx::PgPool 会尝试自动恢复吗?还是从那时起,所有数据库交互都会失败,直到我们重新启动应用程序?
- 如果攻击者试图在 POST/subscriptions 请求的主体中传递恶意负载(例如,极大的负载、尝试执行 SQL 注入等),会发生什么?
这些通常被称为已知的未知问题:我们已知但尚未调查的缺陷,或者我们认为它们与实际无关,不值得花时间处理。
只要投入足够的时间和精力,我们就能摆脱大多数已知的未知问题。
不幸的是,有些问题我们以前从未见过,也没有预料到,它们就是未知的未知问题。
有时,经验足以将未知的未知问题转化为已知的未知问题:如果你以前从未使用过数据库,你可能从未想过连接中断时会发生什么;一旦你见过一次,它就变成了一种熟悉的故障模式,需要时刻注意。
通常情况下,未知的未知问题是我们正在开发的特定系统特有的故障模式。
它们存在于我们的软件组件、底层操作系统、我们正在使用的硬件、我们开发流程的特性以及被称为“外部世界”的巨大随机性来源之间的交汇处。
它们可能出现在以下情况:
- 系统超出其正常运行条件(例如,异常的流量峰值)
- 多个组件同时发生故障(例如,数据库进行主从故障转移时,SQL 事务被挂起)
- 引入了改变系统平衡的变更(例如,调整重试策略)
- 长时间未引入任何变更(例如,应用程序数周未重启,然后开始出现各种内存泄漏)
- 等等
所有这些场景都有一个关键的相似之处: 它们通常无法在实际环境之外重现。
我们该如何做好准备,以应对由未知陌生人造成的中断或错误?
可观察性
我们必须假设,当未知问题出现时,我们可能不在现场:可能是深夜,也可能正在处理其他事情,等等。
即使我们在问题开始出现的那一刻注意到了问题,通常也不可能或不切实际地将调试器连接到生产环境中运行的进程(假设你一开始就知道应该查看哪个进程),而且性能下降可能会同时影响 多个系统。
我们唯一可以依赖的理解和调试未知问题的方法是遥测数据: 关于我们正在运行的应用程序的信息,这些信息会被自动收集,之后可以进行检查,以解答有关系统在某个时间点状态的问题。 什么问题?
好吧,如果这是一个未知的未知问题,我们事先并不知道需要提出哪些问题来隔离其根本原因——这就是关键所在。
我们的目标是拥有一个可观察的应用程序
引用自 Honeycomb 的可观察性指南:
可观察性是指能够针对你的环境提出任意问题,而无需 (——这是关键部分——) 提前知道你想问什么。
“任意”这个词用得有点过头了——就像所有绝对的表述一样,如果我们从字面上理解它,可能需要投入不合理的时间和金钱。
实际上,我们也会乐意选择一个具有足够可观察性的应用程序,以便我们能够提供我们向用户承诺的服务水平。
简而言之,要构建一个可观察的系统,我们需要:
- 对我们的应用程序进行检测,以收集高质量的遥测数据;
- 能够使用工具和系统,高效地对数据进行切片、切块和操作,以找到问题的答案。
我们将讨论一些可用于实现第二点的选项,但详尽的讨论超出了本书的范围。
在本章的其余部分,我们将重点讨论第一点。
日志记录
日志是最常见的遥测数据类型。
即使是从未听说过可观察性的开发人员,也能直观地理解日志的用处:当事情出错时,你会查看日志来了解正在发生的事情, 并祈祷自己能捕获足够的信息来有效地进行故障排除。
那么,日志是什么呢?
它的格式因时代、平台和你使用的技术而异。
如今,日志记录通常是一堆文本数据,并用换行符分隔当前记录和下一个记录。例如
The application is starting on port 8080
Handling a request to /index
Handling a request to /index
Returned a 200 OK
对于 Web 服务器来说,这四条日志记录完全有效。
Rust 生态系统在日志记录方面能为我们提供什么?
log crate
Rust 中用于日志记录的首选 crate 是 log。
log 提供了五个宏:trace、debug、info、warn 和 error。
它们的作用相同——发出一条日志记录——但正如其名称所暗示的那样,它们各自使用不同的日志级别。
trace 是最低级别: trace 级别的日志通常非常冗长,信噪比较低(例如,每次 Web 服务器收到 TCP 数据包时都会发出一条 trace 级别的日志记录)。
然后,我们依次按严重程度递增,依次为 debug、info、warn 和 error。
Error 级别的日志用于报告可能对用户造成影响的严重故障(例如,我们未能处理传入的请求或数据库查询超时)。
让我们看一个简单的使用示例:
fn fallible_operation() -> Result<String, String> { ... }
pub fn main() {
match fallible_operation() {
Ok(success) => {
log::info!("Operation succeeded: {}", success);
}
Err(err) => {
log::error!("Operation failed: {}", err);
}
}
}
我们正在尝试执行一个可能会失败的操作。
如果成功,我们将发出一条信息级别的日志记录。
如果失败,我们将发出一条错误级别的日志记录。
另请注意,log 的宏支持与标准库中 println/print 相同的插值语法。
我们可以使用 log 的宏来检测我们的代码库。
选择记录关于特定函数执行的信息通常是一个本地决策:只需查看函数本身即可决定哪些信息值得在日志记录中捕获。
这使得库能够被有效地检测,将遥测的范围扩展到我们亲自编写的代码之外。
actix-web 的日志中间件
actix_web 提供了一个 Logger 中间件。它会为每个传入的请求发出一条日志记录。
让我们将它添加到我们的应用程序中。
//! src/startup.rs
use std::net::TcpListener;
use actix_web::{dev::Server, middleware::Logger, web, App, HttpServer};
use sqlx::PgPool;
use crate::routes::{health_check, subscribe};
pub fn run(
listener: TcpListener,
db_pool: PgPool,
) -> Result<Server, std::io::Error> {
let db_pool = web::Data::new(db_pool);
let server = HttpServer::new(move || {
App::new()
// Middlewares are added using the `wrap` method on `App`
.wrap(Logger::default())
.route("/health_check", web::get().to(health_check))
.route("/subscriptions", web::post().to(subscribe))
.app_data(db_pool.clone())
})
.listen(listener)?
.run();
Ok(server)
}
现在,我们可以使用 cargo run 启动该应用,并使用 curl 快速发送一个请求:curl http://127.0.0.1:8000/health_check -v。
请求返回 200,但是......我们用来启动应用的终端上没有任何反应。
没有日志。什么也没有。屏幕一片空白。
门面模式
我们说过,检测是一个局部决策。
相反,应用程序需要做出一个全局决策:我们应该如何处理所有这些日志记录?
应该将它们附加到文件中吗? 应该将它们打印到终端吗? 应该通过 HTTP 将它们发送到远程系统(例如 ElasticSearch)吗?
log crate 利用门面模式来处理这种二元性。
它为您提供了发出日志记录所需的工具,但没有规定应该如何处理这些日志记录。相反,它提供了一个 Log trait:
//! From `log`'s source code - src/lib.rs
/// A trait encapsulating the operations required of a logger.
pub trait Log: Sync + Send {
/// Determines if a log message with the specified metadata would be
/// logged.
///
/// This is used by the `log_enabled!` macro to allow callers to avoid
/// expensive computation of log message arguments if the message would be
/// discarded anyway.
fn enabled(&self, metadata: &Metadata) -> bool;
/// Logs the `Record`.
///
/// Note that `enabled` is *not* necessarily called before this method.
/// Implementations of `log` should perform all necessary filtering
/// internally.
fn log(&self, record: &Record);
}
在主函数的开头, 您可以调用 set_logger 函数并传递 Log trait 的实现: 每次发出日志记录时,都会在您提供的记录器上调用 Log::log,从而可以执行您认为必要的任何形式的日志记录处理。
如果不调用 set_logger,所有日志记录都会被丢弃。这正是我们应用程序所发生的事情。
这次让我们初始化我们的日志记录器。
crates.io 上有一些日志实现 - 最常用的选项列在 log 本身的文档中。
我们将使用 env_logger - 如果像我们的例子一样,主要目标是将所有日志记录打印到终端,那么它就非常有效。
让我们将其添加为依赖项
cargo add env_logger
env_logger::Logger 将日志记录打印到终端,使用以下格式:
[<timestamp> <level> <module path>] <log message>
它会查看 RUST_LOG 环境变量来确定哪些日志应该打印,哪些日志应该被过滤掉。
例如, RUST_LOG=debug cargo run 会显示由我们的应用程序或我们正在使用的 crate 发出的所有调试级别或更高级别的日志。而 RUST_LOG=zero2prod 则会过滤掉由我们的依赖项发出的所有记录。
让我们根据需要修改 main.rs 文件:
//! src/main.rs
// [...]
use env_logger::Env;
#[tokio::main]
async fn main() -> std::io::Result<()> {
// `init` does call `get_logger`, so this is all we need to do.
// We are falling back to printing all logs at into-level or above
// if the RUST_LOG envirionment variable has not been set.
env_logger::Builder::from_env(Env::default().default_filter_or("info")).init();
// [...]
}
让我们尝试使用 cargo run 再次启动该应用程序(根据我们的默认逻辑,这相当于 RUST_LOG=info cargo run)。终端上应该会显示两条日志记录(使用换行符,并缩进以使其适合页边距)。
[2025-08-23T01:23:50Z INFO actix_server::builder] starting 20 workers
[2025-08-23T01:23:50Z INFO actix_server::server] Tokio runtime found; starting in existing Tokio r
untime
[2025-08-23T01:23:50Z INFO actix_server::server] starting service: "actix-web-service-0.0.0.0:8000
", workers: 20, listening on: 0.0.0.0:8000
如果我们使用 curl 发送 http://127.0.0.1:8000/health_check 请求,你应该会看到另一条日志记录,
这条记录是由我们在前几段中添加的 Logger 中间件发出的。
[2025-08-23T01:24:24Z INFO actix_web::middleware::logger] 127.0.0.1 "GET /health_check HTTP/1.1" 200 0 "-" "curl/8.15.0" 0.000094
日志也是探索我们正在使用的软件如何工作的绝佳工具。
尝试将 RUST_LOG 设置为 trace 并重新启动应用程序。
您应该会看到一堆来自 docs.rs/mio(一个用于非阻塞 IO 的底层库)的轮询器注册日志记录,以及由 actix-web 生成的每个工作进程的几个启动日志记录(每个工作进程对应您机器上每个可用的物理核心!)。
通过研究 trace 级别的日志,您可以学到很多有深度的东西。
检测 POST /订阅
让我们利用之前学到的关于日志的知识,来设计一个 POST /subscriptions 请求的处理程序。
目前它看起来像这样:
pub async fn subscribe(
form: web::Form<FormData>,
pool: web::Data<PgPool>,
) -> HttpResponse {
match sqlx::query!(/* [...] */)
.execute(pool.get_ref())
.await
{
Ok(_) => HttpResponse::Ok().finish(),
Err(e) => {
println!("Failed to execute query: {e}");
HttpResponse::InternalServerError().finish()
}
}
}
让我们添加 log crate
cargo add log
我们应该在日志记录中捕获什么?
与外部系统的交互
让我们从一条久经考验的经验法则开始:任何通过网络与外部系统的交互都应受到密切监控。我们可能会遇到网络问题,数据库可能不可用,查询速度可能会随着订阅者表的变长而变慢,等等。
让我们添加两条日志记录: 一条在查询执行开始之前,一条在查询执行完成后立即记录。
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(
form: web::Form<FormData>,
pool: web::Data<PgPool>,
) -> HttpResponse {
log::info!("Saving new subscriber details in the database");
match sqlx::query!(
r#"
INSERT INTO subscriptions (id, email, name, subscribed_at)
VALUES ($1, $2, $3, $4)
"#,
Uuid::new_v4(),
form.email,
form.name,
Utc::now()
)
.execute(pool.get_ref())
.await
{
Ok(_) => {
log::info!("New subscriber details have been saved");
HttpResponse::Ok().finish()
},
Err(e) => {
log::error!("Failed to execute query: {e:?}");
HttpResponse::InternalServerError().finish()
}
}
}
目前,我们只会在查询成功时发出日志记录。为了捕获失败,我们需要将 println 语句转换为错误级别的日志:
log::error!("Failed to execute query: {e:?}");
好多了——我们现在已经基本覆盖了那个查询。
请注意一个小而关键的细节:我们使用了 std::fmt::Debug 格式的 {:?} 来捕获查询错误。
操作员是日志的主要受众——我们应该尽可能多地提取有关任何故障的信息,以便于故障排除。Debug 提供了原始视图,而 std::fmt::Display ({}) 会返回更美观的错误消息,更适合直接显示给我们的最终用户。
向用户一样思考
我们还应该捕捉什么?
之前我们说过
我们很乐意选择一个具有足够可观察性的应用程序,以便我们能够提供我们向用户承诺的服务水平。
这在实践中意味着什么?
我们需要改变我们的参考系统。
暂时忘记我们是这款软件的作者。
设身处地为你的一位用户着想,一个访问你网站、对你发布的内容感兴趣并想订阅你的新闻通讯的人。
对他们来说,失败意味着什么?
故事可能是这样的:
嘿! 我尝试用我的主邮箱地址
thomas_mann@hotmail.com订阅你的新闻通讯,但网站出现了一个奇怪的错误。 你能帮我看看发生了什么吗? 祝好, 汤姆 附言:继续加油,你的博客太棒了!
Tom 访问了我们的网站,点击“提交”按钮时收到了“一个奇怪的错误”。
如果我们能根据他提供的信息(例如他输入的电子邮件地址)对问题进行分类,那么我们的申请就足够容易被观察到了。
我们能做到吗?
首先,让我们确认一下这个问题:Tom 是否注册为订阅者?
我们可以连接到数据库,并运行一个快速查询,再次确认我们的订阅者表中没有包含 thomas_mann@hotmail.com 邮箱地址的记录。
问题已确认。现在怎么办?
我们的日志中没有包含订阅者的邮箱地址,所以我们无法搜索。这完全是死路一条。 我们可以要求 Tom 提供更多信息:我们所有的日志记录都有时间戳,也许如果他记得自己尝试订阅的时间,我们就能找到一些线索?
这清楚地表明我们当前的日志质量不够好。
让我们改进它们:
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
log::info!(
"Adding '{}' '{}' as a new subscriber.",
form.email,
form.name,
);
log::info!("Saving new subscriber details in the database");
match sqlx::query!(/* [...] */)
.execute(pool.get_ref())
.await
{
Ok(_) => {
log::info!("New subscriber details have been saved");
HttpResponse::Ok().finish()
}
Err(e) => {
println!("Failed to execute query: {e}");
HttpResponse::InternalServerError().finish()
}
}
}
好多了——我们现在有一条日志行,可以同时捕获姓名和电子邮件。
这足以解决 Tom 的问题吗?
我们应该记录姓名和电子邮件吗?如果您在欧洲运营,这些信息通常属于个人身份信息 (PII),其处理必须遵守《通用数据保护条例》(GDPR) 中规定的原则和规则。我们应该严格控制谁可以访问这些信息、我们计划存储这些信息的时间、如果用户要求被遗忘,应该如何删除这些信息等等。一般来说,有很多类型的信息对于调试目的有用,但不能随意记录(例如密码)——您要么不得不放弃它们,要么依靠混淆技术(例如标记化/假名化)来在安全性、隐私性和实用性之间取得平衡。
日志必须易于关联
为了让示例简洁,我将在后续的终端输出中省略 sqlx 发出的日志。sqlx 的日志默认使用 INFO 级别——我们将在第 5 章中将其调低为 TRACE 级别。
如果我们的 Web 服务器只有一个副本在运行,并且该副本每次只能处理一个请求,那么我们可能会想象终端中显示的日志大致如下:
# First request
[.. INFO zero2prod] Adding 'thomas_mann@hotmail.com' 'Tom' as a new subscriber
[.. INFO zero2prod] Saving new subscriber details in the database
[.. INFO zero2prod] New subscriber details have been saved
[.. INFO actix_web] .. "POST /subscriptions HTTP/1.1" 200 ..
# Second request
[.. INFO zero2prod] Adding 's_erikson@malazan.io' 'Steven' as a new subscriber
[.. ERROR zero2prod] Failed to execute query: connection error with the database
[.. ERROR actix_web] .. "POST /subscriptions HTTP/1.1" 500 ..
您可以清楚地看到单个请求从哪里开始,在我们尝试执行该请求时发生了什么,我们返回了什么响应,下一个请求从哪里开始等等。
这很容易理解。
但当您同时处理多个请求时,情况并非如此:
[.. INFO zero2prod] Receiving request for POST /subscriptions
[.. INFO zero2prod] Receiving request for POST /subscriptions
[.. INFO zero2prod] Adding 'thomas_mann@hotmail.com' 'Tom' as a new subscriber
[.. INFO zero2prod] Adding 's_erikson@malazan.io' 'Steven' as a new subscriber
[.. INFO zero2prod] Saving new subscriber details in the database
[.. ERROR zero2prod] Failed to execute query: connection error with the database
[.. ERROR actix_web] .. "POST /subscriptions HTTP/1.1" 500 ..
[.. INFO zero2prod] Saving new subscriber details in the database
[.. INFO zero2prod] New subscriber details have been saved
[.. INFO actix_web] .. "POST /subscriptions HTTP/1.1" 200 ..
但是,我们哪些细节没有保存呢? thomas_mann@hotmail.com 还是 s_erikson@malazan.io?
从日志中无法判断。
我们需要一种方法来关联与同一请求相关的所有日志。
这通常使用请求 ID(也称为关联 ID)来实现:当我们开始处理传入请求时,我们会生成一个随机标识符(例如 UUID),然后将其与所有与该特定请求执行相关的日志关联起来。
让我们在处理程序中添加一个:
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
let request_id = Uuid::new_v4();
log::info!(
"request_id {} - Adding '{}' '{}' as a new subscriber.",
request_id,
form.email,
form.name,
);
log::info!("request_id {request_id} - Saving new subscriber details in the database");
match sqlx::query!(/* [...] */)
.execute(pool.get_ref())
.await
{
Ok(_) => {
log::info!("request_id {request_id} - New subscriber details have been saved");
HttpResponse::Ok().finish()
}
Err(e) => {
println!("request_id {request_id} - Failed to execute query: {e}");
HttpResponse::InternalServerError().finish()
}
}
}
传入请求的日志现在看起来像这样:
curl -i -X POST -d 'email=thomas_mann@hotmail.com&name=Tom' \
http://127.0.0.1:8000/subscriptions
[.. INFO zero2prod] request_id 9ebde7e9-1efe-40b9-ab65-86ab422e6b87 - Adding
'thomas_mann@hotmail.com' 'Tom' as a new subscriber.
[.. INFO zero2prod] request_id 9ebde7e9-1efe-40b9-ab65-86ab422e6b87 - Saving
new subscriber details in the database
[.. INFO zero2prod] request_id 9ebde7e9-1efe-40b9-ab65-86ab422e6b87 - New
subscriber details have been saved
[.. INFO actix_web] .. "POST /subscriptions HTTP/1.1" 200 ..
现在,我们可以在日志中搜索 thomas_mann@hotmail.com,找到第一条记录,获取 request_id,然后拉取与该请求关联的所有其他日志记录。
几乎所有日志的 request_id 都是在我们的订阅处理程序中创建的,因此 actix_web 的 Logger 中间件完全不知道它的存在。
这意味着,当用户尝试订阅我们的新闻通讯时,我们无法知道应用程序返回的状态码是什么。
我们该怎么办?
我们可以硬着头皮移除 actix_web 的 Logger,编写一个中间件为每个传入请求生成一个随机的请求标识符,然后编写我们自己的日志中间件,使其能够识别该标识符并将其包含在所有日志行中。
这样可以吗? 可以。
我们应该这样做吗? 可能不应该。
结构化日志
为了确保所有日志记录都包含 request_id, 我们必须:
- 重写请求处理管道中的所有上游组件 (例如 actix-web 的 Logger)
- 更改我们从订阅处理程序调用的所有下游函数的签名;如果它们要发出日志语句,则需要包含
request_id, 因此需要将其作为参数传递下去。
那么我们导入到项目中的 crate 发出的日志记录呢?我们也应该重写这些 crate 吗?
显然,这种方法无法扩展。
让我们退一步思考:我们的代码是什么样的?
我们有一个总体任务(HTTP 请求),它被分解为一系列子任务(例如,解析输入、进行查询等),这些子任务又可以递归地分解为更小的子例程。
每个工作单元都有一个持续时间(即开始和结束)。
每个工作单元都有一个与其关联的上下文(例如,新订阅者的姓名和电子邮件地址、request_id),这些上下文自然会被其所有子工作单元共享。
毫无疑问,我们正面临困境:日志语句是在特定时间点发生的孤立事件,而我们却固执地试图用它来表示树状处理流水线。 日志是一种错误的抽象。
那么,我们应该使用什么呢?
tracing Crate
tracing crate 可以帮助我们
tracing 扩展了日志式诊断,允许库和应用程序记录结构化事件,并附加有关时间性和因果关系的信息——与日志消息不同,跟踪中的跨度具有开始和结束时间,可以通过执行流进入和退出,并且可以存在于类似跨度的嵌套树中。
这真是天籁之音。
实际效果如何?
从 log 迁移到 tracing
只有一种方法可以找到答案——让我们将订阅处理程序转换为使用 tracing 而不是 log 进行检测。
让我们将 tracing 添加到依赖项中:
cargo add tracing --features=log
迁移的第一步非常简单:搜索函数主体中所有出现的 log:: 字符串,并将其替换为 tracing。
pub async fn subscribe(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
let request_id = Uuid::new_v4();
tracing::info!(
"request_id {} - Adding '{}' '{}' as a new subscriber.",
request_id,
form.email,
form.name,
);
tracing::info!("request_id {request_id} - Saving new subscriber details in the database");
match sqlx::query!(/* [...] */)
.execute(pool.get_ref())
.await
{
Ok(_) => {
tracing::info!("request_id {request_id} - New subscriber details have been saved");
HttpResponse::Ok().finish()
}
Err(e) => {
println!("request_id {request_id} - Failed to execute query: {e}");
HttpResponse::InternalServerError().finish()
}
}
}
这样就好了。
如果您运行该应用程序并发出 POST /subscriptions 请求,
您将在控制台中看到完全相同的日志。完全相同。
很酷,不是吗?
这得益于我们在 Cargo.toml 中启用的 tracing log 功能标志。它确保每次使用 tracing 的宏创建事件或跨度时,都会发出相应的日志事件,
以便日志的记录器(在本例中为 env_logger)能够捕获它。
tracing 的 Span
现在,我们可以开始利用跟踪的 Span 来更好地捕获程序的结构。
我们需要创建一个代表整个 HTTP 请求的 span:
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
let request_id = Uuid::new_v4();
// Spans, like logs, have an associated level
// `into_span` creates a span at the into-level
let request_span = tracing::info_span!(
"Adding a new subscriber.",
%request_id,
subscriber_email = %form.email,
subscriber_name = %form.name,
);
// Using `enter` in an async function is a recipe for disaster!
// Bear with me for now, but don't do this at home.
// See the floowing secion on `Instrumenting Futures`
let _request_span_guard = request_span.enter();
// [...]
// `_request_span_guard` is dropped at the end of `subscribe`
// That's when we "exit" the span
}
这里有很多事情要做——让我们分解一下。
我们使用 info_span! 宏创建一个新的 span,并将一些值附加到其上下文中: request_id、form.email 和 form.name。
我们不再使用字符串插值:跟踪允许我们将结构化信息关联到 span,作为键值对的集合32。我们可以显式命名它们(例如,将 form.email 命名为subscriber_email), 也可以隐式使用变量名作为键(例如,单独的 request_id 等同于 request_id = request_id)。
请注意,我们在所有 span 前面都添加了 % 符号: 我们告诉 tracing 使用它们的 Display 实现进行日志记录。您可以在它们的文档中找到有关其他可用选项的更多详细信息。
info_span 返回新创建的 span,但我们必须使用 .enter() 方法显式进入其中才能激活它。
.enter() 返回 Entered 的一个实例,它是一个守卫:只要守卫变量未被丢弃,所有下游 span 和日志事件都将被注册为已进入 span 的子级。这是一种典型的 Rust 模式,通常被称为资源获取即初始化 (RAII):编译器会跟踪所有变量的生命周期,当它们超出作用域时,会插入对其析构函数的调用,Drop::drop。
Drop trait 的默认实现只负责释放该变量所拥有的资源。不过,我们可以指定一个自定义的 Drop 实现,以便在 drop 时执行其他清理操作——例如,当 Entered 守卫被 drop 时退出 span:
//! `tracing`'s source code
impl<'a> Drop for Entered<'a> {
#[inline]
fn drop(&mut self) {
// Dropping the guard exits the span.
//
// Running this behaviour on drop rather than with an explicit function
// call means that spans may still be exited when unwinding.
if let Some(inner) = self.span.inner.as_ref() {
inner.subscriber.exit(&inner.id);
}
}
}
if_log_enabled! {{
if let Some(ref meta) = self.span.meta {
self.span.log(
ACTIVITY_LOG_TARGET,
log::Level::Trace,
format_args!("<- {}", meta.name())
);
}
}}
检查依赖项的源代码通常可以发现一些有用信息——我们刚刚发现,如果启用了日志功能标志,当 span 退出时,跟踪将会发出跟踪级别的日志。
让我们立即尝试一下:
RUST_LOG=trace cargo run
[.. INFO zero2prod] Adding a new subscriber.; request_id=f349b0fe..
subscriber_email=ursulale_guin@gmail.com subscriber_name=le guin
[.. TRACE zero2prod] -> Adding a new subscriber.
[.. INFO zero2prod] request_id f349b0fe.. - Saving new subscriber details
in the database
[.. INFO zero2prod] request_id f349b0fe.. - New subscriber details have
been saved
[.. TRACE zero2prod] <- Adding a new subscriber.
[.. TRACE zero2prod] -- Adding a new subscriber.
[.. INFO actix_web] .. "POST /subscriptions HTTP/1.1" 200 ..
注意,我们在 span 上下文中捕获的所有信息是如何在发出的日志行中报告的。
我们可以使用发出的日志密切跟踪 span 的生命周期:
- 创建 span 时记录添加新订阅者的操作;
- 进入 span (->);
- 执行 INSERT 查询;
- 退出 span (<-);
- 最终关闭 span (--)。
等等,退出 span 和关闭 span 有什么区别?
很高兴你问这个问题!
你可以多次进入(和退出)一个 span。而关闭 span 是最终操作: 它发生在 span 本身被丢弃时。
当你有一个可以暂停然后恢复的工作单元时,这非常方便——例如一个异步任务!
检测 Futures
让我们以数据库查询为例。
执行器可能需要多次轮询其 Future 才能使其完成——当该 Future 处于空闲状态时,我们将处理其他 Future。 这显然会引发问题:我们如何确保不混淆它们各自的跨度?
最好的方法是紧密模拟 Future 的生命周期:每次执行器轮询 Future 时,我们都应该进入与其关联的跨度, 并在其每次暂停时退出。
这就是 Instrument 的用武之地。它是 Future 的一个扩展特性。Instrument::instrument 正是我们想要的:每次轮询 self(Future)时,进入我们作为参数传递的跨度;并在 Future 每次暂停时退出跨度。
让我们在查询中尝试一下:
//! src/routes/subscriptions.rs
use tracing::Instrument;
// [...]
pub async fn subscribe(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
let request_id = Uuid::new_v4();
let request_span = tracing::info_span!(
"Adding a new subscriber.",
%request_id,
subscriber_email = %form.email,
subscriber_name = %form.name,
);
let _request_span_guard = request_span.enter();
// We do not call `.enter` on query_span!
// `.instrument` takes care of it at the right moments
// in the query future lifetime
let query_span = tracing::info_span!("Saving new subscriber details in the database");
match sqlx::query!(/* [...] */)
.execute(pool.get_ref())
.instrument(query_span)
.await
{
Ok(_) => {
tracing::info!("request_id {request_id} - New subscriber details have been saved");
HttpResponse::Ok().finish()
}
Err(e) => {
println!("request_id {request_id} - Failed to execute query: {e}");
HttpResponse::InternalServerError().finish()
}
}
}
如果我们使用 RUST_LOG=trace 再次启动应用程序并尝试 POST /subscriptions 请求,我们将看到类似以下的日志:
[.. INFO zero2prod] Adding a new subscriber.; request_id=f349b0fe..
subscriber_email=ursulale_guin@gmail.com subscriber_name=le guin
[.. TRACE zero2prod] -> Adding a new subscriber.
[.. INFO zero2prod] Saving new subscriber details in the database
[.. TRACE zero2prod] -> Saving new subscriber details in the database
[.. TRACE zero2prod] <- Saving new subscriber details in the database
[.. TRACE zero2prod] -> Saving new subscriber details in the database
[.. TRACE zero2prod] <- Saving new subscriber details in the database
[.. TRACE zero2prod] -> Saving new subscriber details in the database
[.. TRACE zero2prod] <- Saving new subscriber details in the database
[.. TRACE zero2prod] -> Saving new subscriber details in the database
[.. TRACE zero2prod] -> Saving new subscriber details in the database
[.. TRACE zero2prod] <- Saving new subscriber details in the database
[.. TRACE zero2prod] -- Saving new subscriber details in the database
[.. TRACE zero2prod] <- Adding a new subscriber.
[.. TRACE zero2prod] -- Adding a new subscriber.
[.. INFO actix_web] .. "POST /subscriptions HTTP/1.1" 200 ..
我们可以清楚地看到查询 Future 在完成之前被执行器轮询了多少次。
太酷了!?
tracing 的 Subscriber
我们着手从日志迁移到跟踪,是因为我们需要一个更好的抽象来有效地检测我们的代码。我们特别希望将 request_id 附加到与同一传入 HTTP 请求相关的所有日志中。
虽然我保证跟踪会解决我们的问题,但看看那些日志:request_id 只打印在第一个日志语句中,我们把它明确地附加到 span 上下文中。
为什么呢?
嗯,我们还没有完成迁移。
虽然我们已经将所有检测代码从 log 迁移到了 tracing,但我们仍然使用 env_logger 来处理所有事情!
//! src/main.rs
// [...]
#[tokio::main]
async fn main() -> std::io::Result<()> {
env_logger::Builder::from_env(Env::default().default_filter_or("info")).init();
// [...]
}
env_logger 的日志记录器实现了 log 的 Log 特性——它对 tracing 的 Span 所暴露的丰富结构一无所知! tracing 与 log 的兼容性非常出色,现在是时候用 tracing 原生解决方案替换 env_logger 了。
tracing crate 遵循 log 使用的相同外观模式——您可以自由地使用它的宏来 检测您的代码,但应用程序负责明确如何处理该 Span 遥测数据。
Subscriber 是 log 的 Log 的 tracing 对应物:Subscriber 特性的实现 暴露了各种方法来管理 Span 生命周期的每个阶段——创建、进入/退出、闭包等等。
//! `tracing`'s source code
pub trait Subscriber: 'static {
fn new_span(&self, span: &span::Attributes<'_>) -> span::Id;
fn event(&self, event: &Event<'_>);
fn enter(&self, span: &span::Id);
fn exit(&self, span: &span::Id);
fn clone_span(&self, id: &span::Id) -> span::Id;
// [...]
}
跟踪文档的质量令人叹为观止——我强烈建议您亲自查看 Subscriber 的文档,以正确理解每个方法的作用。
tracing-subscriber
tracing 不提供任何开箱即用的 subscriber。
我们需要研究 tracing-subscriber(这是 tracing 项目内部维护的另一个 crate), 以便找到一些基本的订阅器来启动它。让我们将它添加到我们的依赖项中:
cargo add tracing-subscriber --features=registry,env-filter
tracing-subscriber 的功能远不止提供一些便捷的订阅器。
它引入了另一个关键特性:Layer。
Layer 使得构建跨度数据的处理管道成为可能:我们不必提供一个包罗万象的订阅器来完成我们想要的一切;相反,我们可以组合多个较小的层来获得所需的处理管道。
这大大减少了整个追踪生态系统中的重复工作:人们专注于通过大量创建新的层来添加新功能,而不是试图构建功能最齐全的订阅器。
分层方法的基石是 Registry。
Registry 实现了 Subscriber 特性,并处理了所有棘手的问题:
Registry 实际上并不记录自身 trace: 相反,它收集并存储暴露给任何包裹它的层的 span 数据 [...]。Registry 负责存储 span 元数据,记录 span 之间的关系,并跟踪哪些 span 处于活动状态,哪些 span 已关闭。
下游层可以搭载 Registry 的功能并专注于其目的: 过滤需要处理的 span、格式化 span 数据、将 span 数据发送到远程系统等。
tracing-bunyan-formatter
我们希望创建一个与旧版 env_logger 功能相同的订阅器。
我们将通过组合三个层来实现此目标:
- tracing_subscriber::filter::EnvFilter 根据日志级别和来源丢弃 span,就像我们在 env_logger 中通过 RUST_LOG 环境变量所做的那样;
- tracing_bunyan_formatter::JsonStorageLayer 处理 span 数据,并将相关元数据以易于理解的 JSON 格式存储,以供下游层使用。它尤其会将上下文从父 span 传播到其子 span;
- tracing_bunyan_formatter::BunyanFormatterLayer 构建于 JsonStorageLayer 之上,并以兼容 bunyan 的 JSON 格式输出日志记录。
让我们将 tracing_bunyan_formatter 添加到我们的依赖项中:
cargo add tracing_bunyan_formatter
现在我们可以将所有内容整合到我们的 main 方法中:
//! src/main.rs
use tracing::subscriber::set_global_default;
use tracing_bunyan_formatter::{BunyanFormattingLayer, JsonStorageLayer};
use tracing_subscriber::{layer::SubscriberExt, EnvFilter, Registry};
// [...]
#[tokio::main]
async fn main() -> std::io::Result<()> {
// We removed the `env_logger` line we had before!
// We are falling back to printing all spans at into-level or above
// if the RUST_LOG environment variable has not been set.
let env_filter = EnvFilter::try_from_default_env()
.unwrap_or_else(|_| EnvFilter::new("info"));
let formatting_layer = BunyanFormattingLayer::new(
"zero2prod".into(),
std::io::stdout
);
// The `with` method is provided by `SubscriberExt`, an extension
// trait for `Subscriber` exposed by `tracing_subscriber`
let subscriber = Registry::default()
.with(env_filter)
.with(JsonStorageLayer)
.with(formatting_layer);
// `set_global_default` can be used by applications to specify
// what subscriber should be used to process spans
set_global_default(subscriber).expect("Failed to set subscriber");
// [...]
}
如果你使用 cargo run 启动应用程序并发出请求,你会看到这些日志(为了更容易阅读,这里格式化后打印):
{
"msg": "[ADDING A NEW SUBSCRIBER - START]",
"subscriber_name": "le guin",
"request_id": "30f8cce1-f587-4104-92f2-5448e1cc21f6",
"subscriber_email": "ursula_le_guin@gmail.com"
...
}
{
"msg": "[SAVING NEW SUBSCRIBER DETAILS IN THE DATABASE - START]",
"subscriber_name": "le guin",
"request_id": "30f8cce1-f587-4104-92f2-5448e1cc21f6",
"subscriber_email": "ursula_le_guin@gmail.com"
...
}
{
"msg": "[SAVING NEW SUBSCRIBER DETAILS IN THE DATABASE - END]",
"elapsed_milliseconds": 4,
"subscriber_name": "le guin",
"request_id": "30f8cce1-f587-4104-92f2-5448e1cc21f6",
"subscriber_email": "ursula_le_guin@gmail.com"
...
}
{
"msg": "[ADDING A NEW SUBSCRIBER - END]",
"elapsed_milliseconds": 5
"subscriber_name": "le guin",
"request_id": "30f8cce1-f587-4104-92f2-5448e1cc21f6",
"subscriber_email": "ursula_le_guin@gmail.com",
...
}
我们成功了:所有附加到原始上下文的内容都已传播到其所有子跨度。
tracing-bunyan-formatter 还提供了开箱即用的持续时间:每次关闭跨度时,都会在控制台上打印一条 JSON 消息,并附加 elapsed_millisecond 属性。
JSON 格式在搜索方面非常友好:像 ElasticSearch 这样的引擎可以轻松提取所有这些记录,推断出模式并索引 request_id、name 和 email 字段。它释放了查询引擎的全部功能来筛选我们的日志!
这比我们以前的方法好得多:为了执行复杂的搜索,我们必须使用自定义的正则表达式,因此大大限制了我们可以轻松向日志提出的问题范围。
tracing-log
如果你仔细观察,就会发现我们遗漏了一些东西:我们的终端只显示由应用程序直接发出的日志。actix-web 的日志记录怎么了?
tracing 的日志功能标志确保每次发生跟踪事件时都会发出一条日志记录,从而允许 log 的记录器获取它们。 反之则不然:log 本身并不提供跟踪事件的发送功能,也没有提供启用此功能的功能标志。
如果需要,我们需要显式注册一个记录器实现,将日志重定向到我们的跟踪订阅者进行处理。
我们可以使用 tracing-log crate 提供的 LogTracer。
cargo add tracing-log
让我们按需求修改 main.rs
//! src/main.rs
// [...]
#[tokio::main]
async fn main() -> std::io::Result<()> {
// Redirect all `log`'s events to our subscriber
LogTracer::init().expect("Failed to set logger");
let env_filter = EnvFilter::try_from_default_env()
.unwrap_or_else(|_| EnvFilter::new("info"));
let formatting_layer = BunyanFormattingLayer::new(
"zero2prod".into(),
std::io::stdout
);
let subscriber = Registry::default()
.with(env_filter)
.with(JsonStorageLayer)
.with(formatting_layer);
set_global_default(subscriber).expect("Failed to set subscriber");
// [...]
}
所有 actix-web 的日志应该再次在我们的控制台中输出。
删除没有用到的依赖
如果你快速浏览一下我们所有的文件,你会发现我们目前还没有在任何地方使用 log 或 env_logger。我们应该将它们从 Cargo.toml 文件中删除。
在大型项目中,重构后很难发现某个依赖项已不再使用。
幸运的是,工具再次派上用场——让我们安装 cargo-udeps (未使用的依赖项):
cargo install cargo-udeps
cargo-udeps 会扫描你的 Cargo.toml 文件,并检查 [dependencies] 下列出的所有 crate 是否已在项目中实际使用。查看 cargo-deps 的“战利品陈列柜”,了解一系列热门 Rust 项目,这些项目都曾使用 cargo-udeps 识别未使用的依赖项并缩短构建时间。
现在就在我们的项目上运行它吧!
# cargo-udeps requires the nightly compiler.
# We add +nightly to our cargo invocation
# to tell cargo explicitly what toolchain we want to use.
cargo +nightly udeps
输出应该是
zero2prod
dependencies
"env-logger"
不幸的是,它没有识别到 log。
让我们从 Cargo.toml 文件中删除这两项。
清理初始化
我们坚持不懈地努力改进应用程序的可观察性。
现在,让我们回顾一下我们编写的代码,看看是否有任何有意义的改进空间。
让我们从 main 函数开始:
#[tokio::main]
async fn main() -> std::io::Result<()> {
LogTracer::init().expect("Failed to set logger");
let env_filter = EnvFilter::try_from_default_env()
.unwrap_or_else(|_| EnvFilter::new("info"));
let formatting_layer = BunyanFormattingLayer::new(
"zero2prod".into(),
std::io::stdout
);
let subscriber = Registry::default()
.with(env_filter)
.with(JsonStorageLayer)
.with(formatting_layer);
set_global_default(subscriber).expect("Failed to set subscriber");
let configuration = get_configuration().expect("Failed to read config");
let connection_pool = PgPool::connect(&configuration.database.connection_string())
.await
.expect("Failed to connect to Postgres.");
let address = format!("0.0.0.0:{}", configuration.application_port);
let listener = TcpListener::bind(address)?;
run(listener, connection_pool)?.await
}
现在主函数中有很多事情要做。
我们来分解一下:
//! src/main.rs
use std::net::TcpListener;
use sqlx::PgPool;
use tracing::{subscriber::set_global_default, Subscriber};
use tracing_bunyan_formatter::{BunyanFormattingLayer, JsonStorageLayer};
use tracing_log::LogTracer;
use tracing_subscriber::{layer::SubscriberExt, EnvFilter, Registry};
use zero2prod::{configuration::get_configuration, run};
/// Compose multiple layers into a `tracing`'s subscriber.
///
/// # Implementation Notes
///
/// We are using `impl Subscriber` as return type to avoid having to
/// spell out the actual type of the returned subscriber, which is
/// indeed quite complex.
/// We need to explicitly call out that the returned subscriber is
/// `Send` and `Sync` to make it possible to pass it to `init_subscriber`
/// later on.
pub fn get_subscriber(
name: impl Into<String>,
env_filter: impl Into<String>,
) -> impl Subscriber + Send + Sync {
let env_filter = EnvFilter::try_from_default_env()
.unwrap_or_else(|_| EnvFilter::new(env_filter.into()));
let formatting_layer = BunyanFormattingLayer::new(
name.into(),
std::io::stdout
);
Registry::default()
.with(env_filter)
.with(JsonStorageLayer)
.with(formatting_layer)
}
/// Register a subscriber as global default to process span data.
///
/// It should only be called once!
pub fn init_subscriber(subscriber: impl Subscriber + Send + Sync) {
LogTracer::init().expect("Failed to set logger");
set_global_default(subscriber).expect("Failed to set subscriber");
}
#[tokio::main]
async fn main() -> std::io::Result<()> {
let subscriber = get_subscriber("zero2prod", "info");
init_subscriber(subscriber);
// [...]
}
我们现在可以将 get_subscriber 和 init_subscriber 移到 zero2prod 库中的一个模块中,叫做 telemetry。
//! src/lib.rs
pub mod configuration;
pub mod routes;
pub mod startup;
pub mod telemetry;
//! src/telemetry.rs
use tracing::{subscriber::set_global_default, Subscriber};
use tracing_bunyan_formatter::{BunyanFormattingLayer, JsonStorageLayer};
use tracing_log::LogTracer;
use tracing_subscriber::{layer::SubscriberExt, EnvFilter, Registry};
pub fn get_subscriber(
name: impl Into<String>,
env_filter: impl Into<String>,
) -> impl Subscriber + Send + Sync {
// [...]
}
pub fn init_subscriber(subscriber: impl Subscriber + Send + Sync) {
// [...]
}
然后在 main.rs 中删除 get_subscriber 和 init_subscriber, 随后导入我们在 telemetry 模块的两个方法
//! src/main.rs
use zero2prod::telemetry::{get_subscriber, init_subscriber};
// [...]
太棒了!
集成测试的日志
我们不仅仅是为了美观/可读性而进行清理——我们还将这两个函数移到了 zero2prod 库中,以便我们的测试套件可以使用它们!
根据经验,我们在应用程序中使用的所有内容都应该反映在我们的集成测试中。
尤其是结构化日志记录,当集成测试失败时,它可以显著加快我们的调试速度: 我们可能不需要附加调试器,日志通常可以告诉我们哪里出了问题。这也是一个很好的基准:如果你无法从日志中调试,想象一下在生产环境中调试会有多么困难!
让我们修改我们的 spawn_app 辅助函数,让它负责初始化我们的 tracing 堆栈:
//! tests/health_check.rs
use zero2prod::telemetry::{get_subscriber, init_subscriber};
async fn spawn_app() -> TestApp {
let subscriber = get_subscriber("test", "debug");
init_subscriber(subscriber);
// [...]
}
// [...]
如果您尝试运行 cargo test,您将会看到一次成功和一系列的测试失败:
test subscribe_returns_a_400_when_data_is_missing ... ok
failures:
---- subscribe_returns_a_200_for_valid_form_data stdout ----
thread 'subscribe_returns_a_200_for_valid_form_data' panicked at zero
2prod/src/telemetry.rs:27:23:
Failed to set logger: SetLoggerError(())
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
---- health_check_works stdout ----
thread 'health_check_works' panicked at zero2prod/src/telemetry.rs:27
:23:
Failed to set logger: SetLoggerError(())
failures:
health_check_works
subscribe_returns_a_200_for_valid_form_data
init_subscriber 应该只调用一次,但我们所有的测试都在调用它。
我们可以使用 once_cell 来解决这个问题
cargo add once_cell
use once_cell::sync::Lazy;
//! tests/health_check.rs
// Ensure that the `tracing` stack is only initialised once using `once_cell`
static TRACING: Lazy<()> = Lazy::new(|| {
let subscriber = get_subscriber("test", "debug");
init_subscriber(subscriber);
});
async fn spawn_app() -> TestApp {
// The first time `initialize` is invoked the code in `TRACING` is executed.
// All other invocations will instead skip execution.
Lazy::force(&TRACING);
// [...]
}
cargo test 现在通过了
然而,输出非常嘈杂:每个测试用例都会输出多行日志。
我们希望跟踪工具在每个测试中都能运行,但我们不想每次运行测试套件时都查看这些日志。
cargo test 解决了 println/print 语句的相同问题。默认情况下,它会吞掉所有打印到控制台的内容。您可以使用 cargo test ---nocapture 明确选择查看这些打印语句。
我们需要一个与跟踪工具等效的策略。
让我们为 get_subscriber 添加一个新参数,以便自定义日志应该写入到哪个接收器:
pub fn get_subscriber<Sink>(
name: impl Into<String>,
env_filter: impl Into<String>,
sink: Sink
) -> impl Subscriber + Send + Sync
// This "weird" syntax is a higher-ranked trait bound (HRTB)
// It basically means that Sink implements the `MakeWriter`
// trait for all choices of the lifetime parameter `'a`
// Check out https://doc.rust-lang.org/nomicon/hrtb.html
// for more details.
where Sink: for<'a> MakeWriter<'a> + Send + Sync + 'static
{
let env_filter = EnvFilter::try_from_default_env()
.unwrap_or_else(|_| EnvFilter::new(env_filter.into()));
let formatting_layer = BunyanFormattingLayer::new(
name.into(),
sink
);
Registry::default()
.with(env_filter)
.with(JsonStorageLayer)
.with(formatting_layer)
}
我们可以调整 main 方法使用 stdout:
//! src/main.rs
// [...]
#[tokio::main]
async fn main() {
let subscriber = get_subscriber("zero2prod", "info", std::io::stdout);
// [...]
}
在我们的测试套件中,我们将根据环境变量 TEST_LOG 动态选择接收器。
- 如果设置了 TEST_LOG,我们将使用 std::io::stdout
- 如果未设置 TEST_LOG,我们将使用 std::io::sink 将所有日志发送到 void
我们自己编写的 --nocapture flag 版本
//! tests/health_check.rs
// [...]
static TRACING: Lazy<()> = Lazy::new(|| {
let default_filter_level = "info";
let subscriber_name = "test";c
// We cannot assign the output of `get_subscriber` to a variable based on the value of `TEST_LOG`
// because the sink is part of the type returned by `get_subscriber`, therefore they are not the
// same type. We could work around it, but this is the most straight-forward way of moving forward.
if std::env::var("TEST_LOG").is_ok() {
let subscriber = get_subscriber(subscriber_name, default_filter_level, std::io::stdout);
init_subscriber(subscriber);
} else {
let subscriber = get_subscriber(subscriber_name, default_filter_level, std::io::sink);
init_subscriber(subscriber);
}
});
当你想查看某个测试用例的所有日志来调试它时,你可以运行
# We are using the `bunyan` CLI to prettify the outputted logs
# The original `bunyan` requires NPM, but you can install a Rust-port with
# `cargo install bunyan`
TEST_LOG=true cargo test health_check_works | bunyan
并仔细检查输出以了解发生了什么。
是不是很棒?
清理仪表代码 - tracing::instrument
我们重构了初始化逻辑。现在来看看我们的插桩代码。
是时候再次回归 subscribe 了。
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
let request_id = Uuid::new_v4();
let request_span = tracing::info_span!(
"Adding a new subscriber.",
%request_id,
subscriber_email = %form.email,
subscriber_name = %form.name,
);
let _request_span_guard = request_span.enter();
// We do not call `.enter` on query_span!
// `.instrument` takes care of it at the right moments
// in the query future lifetime
let query_span = tracing::info_span!("Saving new subscriber details in the database");
match sqlx::query!(
r#"
INSERT INTO subscriptions (id, email, name, subscribed_at)
VALUES ($1, $2, $3, $4)
"#,
Uuid::new_v4(),
form.email,
form.name,
Utc::now()
)
.execute(pool.get_ref())
// First we attach the instrumentation, then we `.await` it
.instrument(query_span)
.await
{
Ok(_) => {
tracing::info!("request_id {request_id} - New subscriber details have been saved");
HttpResponse::Ok().finish()
}
Err(e) => {
println!("request_id {request_id} - Failed to execute query: {e}");
HttpResponse::InternalServerError().finish()
}
}
}
公平地说,日志记录给我们的订阅函数带来了一些噪音。
让我们看看能否稍微减少一下。
我们将从 request_span 开始: 我们希望订阅函数中的所有操作都在 request_span 的上下文中发生。
换句话说,我们希望将订阅函数包装在一个 span 中。
这种需求相当普遍: 将每个子任务提取到其各自的函数中是构建例程的常用方法,可以提高可读性并简化测试的编写;因此,我们经常会希望将 span 附加到函数声明中。
tracing 通过其 tracing::instrument 过程宏来满足这种特定的用例。让我们看看它的实际效果:
//! src/rotues/subscriptions.rs
// [...]
#[tracing::instrument(
name = "Adding a new subscriber",
skip(form, pool),
fields(
request_id = %Uuid::new_v4(),
subscriber_email = %form.email,
subscriber_name = %form.name,
)
)]
pub async fn subscribe(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
let query_span = tracing::info_span!("Saving new subscriber details in the database");
match sqlx::query!(/* [...] */)
.execute(pool.get_ref())
.instrument(query_span)
.await
{
Ok(_) => {
HttpResponse::Ok().finish()
}
Err(e) => {
tracing::error!("Failed to execute query: {e}");
HttpResponse::InternalServerError().finish()
}
}
}
#[tracing::instrument] 在函数调用开始时创建一个 span,并自动将传递给函数的所有参数附加到 span 的上下文中——在我们的例子中是 form 和 pool。函数参数通常不会显示在日志记录中(例如 pool),或者我们希望更明确地指定应该捕获哪些参数/如何捕获它们(例如,命名 form 的每个字段)——我们可以使用 skip 指令明确地告诉跟踪忽略它们。
name 可用于指定与函数 span 关联的消息 - 如果省略,则默认为函数名称。
我们还可以使用 fields 指令来丰富 span 的上下文。它利用了我们之前在 info_span! 宏中见过的相同语法。 结果相当不错:所有插桩关注点在视觉上都被执行关注点分隔开来,
前者由一个过程宏来处理,该宏“修饰”函数声明,而函数体则专注于实际的业务逻辑。
需要指出的是,如果将 tracing::instrument 应用于异步函数,它也会小心地使用 Instrument::instrument。
让我们将查询提取到其自己的函数中,并使用 tracing::instrument 来摆脱 query_span
以及对 .instrument 方法的调用:
//! src/routes/subscription.rs
// [...]
#[tracing::instrument(
name = "Adding a new subscriber",
skip(form, pool),
fields(
request_id = %Uuid::new_v4(),
subscriber_email = %form.email,
subscriber_name = %form.name,
)
)]
pub async fn subscribe(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
match insert_subscriber(&pool, &form).await {
Ok(_) => HttpResponse::Ok().finish(),
Err(_) => HttpResponse::InternalServerError().finish(),
}
}
#[tracing::instrument(
name = "Saving new subscriber details in the database",
skip(form, pool)
)]
pub async fn insert_subscriber(pool: &PgPool, form: &FormData) -> Result<(), sqlx::Error> {
sqlx::query!(
r#"
INSERT INTO subscriptions (id, email, name, subscribed_at)
VALUES ($1, $2, $3, $4)
"#,
Uuid::new_v4(),
form.email,
form.name,
Utc::now()
)
.execute(pool)
.await
.inspect_err(|e| {
tracing::error!("Failed to execute query: {:?}", e);
})?;
Ok(())
}
错误事件现在确实落在查询范围内,并且我们实现了更好的关注点分离:
- insert_subscriber 负责数据库逻辑,它不感知周围的 Web 框架 - 也就是说,我们不会将
web::Form或web::Data包装器作为输入类型传递 - subscribe 通过调用所需的例程来协调要完成的工作,并根据 HTTP 协议的规则和约定将其结果转换为正确的响应
我必须承认我对 tracing::instrument 的无限热爱: 它显著降低了检测代码所需的工作量。
它会将你推向成功的深渊: 做正确的事是最容易的事。
保护你的秘密 - secrecy
#[tracing::instrument] 中其实有一个我不太喜欢的元素:它会自动将传递给函数的所有参数附加到 span 的上下文中——你必须选择不记录函数输入(通过 skip 选项),而不是选择加入。
你肯定不希望日志中包含机密信息(例如密码)或个人身份信息(例如最终用户的账单地址)。
选择退出是一个危险的默认设置——每次使用 #[tracing::instrument] 向函数添加新输入时,你都需要问自己: 记录这段输入安全吗? 我应该跳过它吗?
如果时间过长,别人就会忘记——你现在要处理一个安全事件。
你可以通过引入一个包装器类型来避免这种情况,该包装器类型明确标记哪些字段被视为敏感字段——secrecy::Secret。
cargo add secrecy --features=serde
我们来看看它的定义:
/// Wrapper type for values that contains secrets, which attempts to limit
/// accidental exposure and ensure secrets are wiped from memory when dropped.
/// (e.g. passwords, cryptographic keys, access tokens or other credentials)
///
/// Access to the secret inner value occurs through the [...]
/// `expose_secret()` method [...]
pub struct Secret<S>
where
S: Zeroize,
{
/// Inner secret value
inner_secret: S,
}
Zeroize trait 提供的内存擦除功能非常实用。
我们正在寻找的关键属性是 SecretBox 的屏蔽 Debug 实现: println!("{:?}", my_secret_string) 输出的是 Secret([REDACTED String]) 而不是实际的 secret 值。这正是我们防止敏感信息通过 #[tracing::instrument] 或其他日志语句意外泄露所需要的。
显式包装器类型还有一个额外的好处: 它可以作为新开发人员的文档,帮助他们熟悉代码库。它明确了在你的领域/根据相关法规,哪些内容被视为敏感信息。
现在我们唯一需要担心的秘密值是数据库密码。让我们写一下:
//! src/configuration.rs
use secrecy::SecretBox;
// [...]
#[derive(serde::Deserialize)]
pub struct DatabaseSettings {
// [...]
pub password: SecretBox<String>,
}
SecretBox 不会干扰反序列化 - SecretBox 通过委托给包装类型的反序列化逻辑来实现 serde::Deserialize(如果您像我们一样启用了 serde 功能标志)。
编译器不满意:
error[E0277]: `SecretBox<std::string::String>` doesn't implement `std::fmt::Display`
--> src/configuration.rs:22:28
|
21 | "postgres://{}:{}@{}:{}/{}",
| -- required by this formatting parameter
22 | self.username, self.password, self.host, self.port, self.database_name
| ^^^^^^^^^^^^^ `SecretBox<std::string::String>` cannot be formatted
with the default formatter
|
= help: the trait `std::fmt::Display` is not implemented for `SecretBox<std::string::String>`
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
= note: this error originates in the macro `$crate::__export::format_args` which comes from the
expansion of the macro `format` (in Nightly builds, run with -Z macro-backtrace for more info)
error[E0277]: `SecretBox<std::string::String>` doesn't implement `std::fmt::Display`
--> src/configuration.rs:29:28
|
28 | "postgres://{}:{}@{}:{}",
| -- required by this formatting parameter
29 | self.username, self.password, self.host, self.port
| ^^^^^^^^^^^^^ `SecretBox<std::string::String>` cannot be formatted
with the default formatter
|
= help: the trait `std::fmt::Display` is not implemented for `SecretBox<std::string::String>`
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
= note: this error originates in the macro `$crate::__export::format_args` which comes from the
expansion of the macro `format` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0277`.
error: could not compile `zero2prod` (lib) due to 2 previous errors
这是一项功能,而非 bug —— secret::SecretBox 没有实现 Display 接口,因此我们需要
明确允许暴露已包装的 secret。编译器错误提示我们,
由于整个数据库连接字符串嵌入了数据库密码,因此也应该将其标记为 SecretBox:
//! src/configuration.rs
use secrecy::{ExposeSecret, SecretBox};
// [...]
impl DatabaseSettings {
pub fn connection_string(&self) -> SecretBox<String> {
SecretBox::new(Box::new(format!(
"postgres://{}:{}@{}:{}/{}",
self.username, self.password.expose_secret(), self.host, self.port, self.database_name
)))
}
pub fn connection_string_without_db(&self) -> SecretBox<String> {
SecretBox::new(Box::new(format!(
"postgres://{}:{}@{}:{}",
self.username, self.password.expose_secret(), self.host, self.port
)))
}
}
//! src/main.rs
use secrecy::ExposeSecret;
use sqlx::PgPool;
use zero2prod::{configuration::get_configuration, run, telemetry::{get_subscriber, init_subscriber}};
#[tokio::main]
async fn main() -> std::io::Result<()> {
// [...]
let connection_pool = PgPool::connect(&configuration.database.connection_string().expose_secret())
.await
.expect("Failed to connect to Postgres.");
// [...]
}
//! tests/health_check.rs
use secrecy::ExposeSecret;
// [...]
pub async fn configure_database(config: &DatabaseSettings) -> PgPool {
// Create database
let mut connection = PgConnection::connect(&config.connection_string_without_db().expose_secret())
.await
.expect("Failed to connect to Postgres");
connection
.execute(format!(r#"CREATE DATABASE "{}";"#, config.database_name).as_str())
.await
.expect("Failed to create database.");
// Migrate database
let connection_pool = PgPool::connect(&config.connection_string().expose_secret())
.await
.expect("Failed to connect to Postgres");
sqlx::migrate!("./migrations")
.run(&connection_pool)
.await
.expect("Failed to migrate the database");
connection_pool
}
暂时就是这样——以后,一旦引入敏感值,我们将确保将其包装到 SecretBox 中。
请求Id
我们还有最后一项工作要做:确保特定请求的所有日志,特别是包含返回状态码的记录,都添加了 request_id 属性。怎么做呢?
如果我们的目标是避免接触 actix_web::Logger,最简单的解决方案是添加另一个中间件,RequestIdMiddleware, 它负责:
- 生成唯一的请求标识符
- 创建一个新的 span,并将请求标识符作为上下文附加
- 将其余的中间件链包装到新创建的 span 中
不过,这样会留下很多问题: actix_web::Logger 无法像其他日志那样以相同的结构化 JSON 格式让我们访问其丰富的信息(状态码、处理时间、调用者 IP 等)——我们必须从其消息字符串中解析出所有这些信息。
在这种情况下,我们最好引入一个支持跟踪的解决方案。
让我们将 tracing-actix-web 添加为依赖项之一
cargo add tracing-actix-web
//! src/startup.rs
use std::net::TcpListener;
use actix_web::{dev::Server, web, App, HttpServer};
use sqlx::PgPool;
use tracing_actix_web::TracingLogger;
use crate::routes::{health_check, subscribe};
pub fn run(
listener: TcpListener,
db_pool: PgPool,
) -> Result<Server, std::io::Error> {
let db_pool = web::Data::new(db_pool);
let server = HttpServer::new(move || {
App::new()
// Instead of `Logger::default`
.wrap(TracingLogger::default())
.route("/health_check", web::get().to(health_check))
.route("/subscriptions", web::post().to(subscribe))
.app_data(db_pool.clone())
})
.listen(listener)?
.run();
Ok(server)
}
如果您启动应用程序并发出请求,您应该会在所有日志中看到 request_id 以及 request_path 和其他一些有用的信息。
我们快完成了——还有一个未解决的问题需要解决。
让我们仔细看看 POST /subscriptions 请求发出的日志记录:
{
"msg": "[REQUEST - START]",
"request_id": "21fec996-ace2-4000-b301-263e319a04c5",
...
}
{
"msg": "[ADDING A NEW SUBSCRIBER - START]",
"request_id":"aaccef45-5a13-4693-9a69-5",
...
}
同一个请求却有两个不同的 request_id!
这个 bug 可以追溯到我们 subscribe 函数中的 #[tracing::instrument] 注解:
//! src/routes/subscriptions.rs
// [...]
#[tracing::instrument(
name = "Adding a new subscriber",
skip(form, pool),
fields(
request_id = %Uuid::new_v4(),
subscriber_email = %form.email,
subscriber_name = %form.name,
)
)]
pub async fn subscribe(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
// [...]
}
我们仍在函数级别生成一个 request_id,它会覆盖来自 TracingLogger 的 request_id。
让我们摆脱它来解决这个问题:
//! src/routes/subscriptions.rs
// [...]
#[tracing::instrument(
name = "Adding a new subscriber",
skip(form, pool),
fields(
subscriber_email = %form.email,
subscriber_name = %form.name,
)
)]
pub async fn subscribe(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
// [...]
}
现在一切都很好 - 我们应用程序的每个端点都有一个一致的 request_id。
利用 tracing 生态系统
我们介绍了 tracing 的诸多功能——它显著提升了我们收集的遥测数据的质量,并提高了插桩代码的清晰度。
与此同时,我们几乎没有触及整个 tracing 生态系统在订阅层方面的丰富性。
以下列举一些现成的组件:
- tracing-actix-web 与 OpenTelemetry 兼容。如果您插入 tracing-opentelemetry,则可以将 span 发送到与 OpenTelemetry 兼容的服务(例如 Jaeger 或 Honeycomb.io)进行进一步分析;
- tracing-error 使用 SpanTrace 丰富了我们的错误类型,从而简化了故障排除。
毫不夸张地说,tracing 是 Rust 生态系统的基础 crate。虽然日志是最小公分母,但 tracing 现已成为整个诊断和插桩生态系统的现代支柱。
小结
我们从一个完全静默的 actix-web 应用程序开始,最终获得了高质量的遥测数据。现在是时候将这个新闻通讯 API 上线了!
在下一章中, 我们将为我们的 Rust 项目构建一个基本的部署流。
部署到生产环境
我们已经有了一个可工作的原型通讯API,是时候让我们把他部署到生产环境中了!
我们将会学习到如何去将我们的Rust程序打包成一个Docker镜像来部署到DigitalOcean的APP Platform
到最后的章节,我们会拥有一个自动部署(CD)的流程:每一个提交到main分支的代码都会自动触发最新版的生产环境应用给用户们使用。
我们必须谈谈部署
几乎所有人都喜欢强调:软件要尽可能频繁地部署到生产环境(我自己也不例外!)。
“要尽早获得客户反馈!”
“要快速发布,不断迭代产品!”
然而,真正告诉你如何去做的人却寥寥无几。
随便翻一本 Web 开发的书,或者某个框架的入门手册。
大多数书对“部署”一笔带过,顶多就是几句话。
有些书会安排一章来讲,但通常放在书的最后——那个往往没人翻到的章节。
只有极少数的书,会在尽可能靠前的部分,给予部署应有的篇幅。
为什么会这样?
因为部署至今仍然是一件棘手的事情。
市面上的服务商数不胜数,大多数并不好用;而所谓的“最佳实践”或者“前沿技术”也变化得极快。
因此,大多数作者都选择回避这个话题: 不仅需要花费大量篇幅,还可能在一两年后发现自己写下的内容已经完全过时。
但现实是,部署在软件工程师的日常工作中占据着非常重要的位置。
比如,当我们谈到数据库模式迁移、领域验证、API 演进时,如果不结合部署流程来讨论,就很难真正把问题讲清楚。
正因如此,在一本名为《从零到生产》的书里,我们绝对不能忽视“部署”这个主题。
选择我们的工具
本章的目的,是让你亲身体验一下:在每一次提交到主分支时,真正把应用部署出去意味着什么。
这也是为什么我们会在第五章就开始谈论部署:为了让你从现在开始,就能在后续章节不断练习这块“肌肉”,就像在一个真实的商业项目中会做的那样。
我们尤其关心的是:持续部署这一工程实践,会如何影响我们的设计决策与开发习惯。
当然,构建一个完美的持续部署流水线并不是本书的重点——那本身就足以写成一本书,甚至需要一整家公司来专注解决。
因此,我们必须务实,在“实用价值”(例如学习到业界广泛使用的工具)与“开发者体验”之间找到平衡。
即便我们现在花费大量精力去拼凑出一个所谓“最佳”的部署方案,等你真正落地到工作中,还是很可能会因为组织的具体限制而选择不同的工具和服务商。
真正重要的是其背后的理念,以及让你能够亲自实践“持续部署”这种方法论。
Docker 这一块
我们的本地开发环境和生产环境,其实承担着截然不同的角色。
在本地机器上,浏览器、IDE,甚至我们的音乐播放列表都能和平共处——它是一个多用途的工作站。 而生产环境则不同,它的关注点非常单一:运行我们的软件,并让用户能够访问。任何与这个目标无关的东西,轻则浪费资源,重则成为安全隐患。
这种差异,长期以来让“部署”变得非常棘手,也催生了一个经典的抱怨——“在我机器上能跑啊!”。
仅仅把源代码拷贝到生产服务器上是远远不够的。 我们的软件往往会依赖一些前提条件,比如:
操作系统的能力:一个原生的 Windows 应用无法在 Linux 上运行。
额外软件的可用性:比如特定版本的 Python 解释器。
系统配置:例如是否拥有 root 权限。
即便我们最初在本地和生产搭建了两套完全一致的环境,随着时间推移,版本的漂移和细微的不一致,依然会在某个深夜或周末“突然反噬”。
确保软件能够稳定运行的最简单方式,就是严格控制它所运行的环境。
这就是虚拟化技术的核心理念: 与其把代码“运”到生产环境,不如直接把包含应用的自给自足的环境一同打包送过去!
这样一来,双方都能获益:
对开发者来说,周五晚上少了许多意外。
对运维来说,得到的是一个稳定、一致的抽象层,可以在其上进一步构建。
如果这个环境本身还能用代码来定义,从而确保可复现性,那就更完美了。
好消息是:虚拟化早已不是什么新鲜事,它已经普及了将近十年。
像技术领域的多数情况一样,你会有多种选择:
-
虚拟机
-
容器(如 Docker)
-
以及一些更轻量化的解决方案(如 Firecracker)
在本书中,我们会选择最主流、最普及的方案——Docker 容器。
Digital Ocean
AWS、Google Cloud、Azure、Digital Ocean、Clever Cloud、Heroku、Qovery…… 你可以选择的软件托管服务商名单还远不止这些。
如今,甚至有人专门靠“根据你的需求和场景推荐最合适的云服务”做起了生意——不过,这既不是我的工作(至少现在还不是),也不是这本书的目的。
我们要寻找的,是易于使用(良好的开发者体验、尽量少的无谓复杂性),同时又相对成熟可靠的解决方案。
在 2020 年 11 月,满足这两个条件的交集似乎就是 Digital Ocean,尤其是他们新推出的 App Platform 服务。
声明:Digital Ocean 没有付钱让我在这里推广他们的服务。
我们项目的Dockerfile
DigitalOcean 的 App Platform 原生支持容器化应用的部署。
我们的第一项任务,就是编写一个 Dockerfile,以便将应用打包并作为 Docker 容器来构建和运行。
Dockerfiles
Dockerfile是你项目环境的配方。
它们包含了这些东西:你的基础镜像(通常是一个OS包含了编程语言的工具链)和一个接一个的命令(COPY, RUN, 等)。这样就可以构建一个你需要的环境。
让我们看看一个最简单的可用的Rust项目的Dockerfile
# We use the latest Rust stable release as base image
FROM rust:1.89.0
# Let's switch our working directory to `app` (equivalent to `cd app`)
# The `app` folder will be created for us by Docker in case it does not
# exist already.
WORKDIR /app
# Install the required system dependencies for our linking configuration
RUN apt update && apt install lld clang -y
# Copy all files from our working environment to our Docker image
COPY . .
# Let's build our binary!
# We'll use the release profile to make it faaaast
RUN cargo build --release
# When `docker run` is executed, launch the binary!
ENTRYPOINT ["./target/release/zero2prod"]
将这个Dockerfile文件保存到项目的根目录:
zero2prod/
.github/
migrations/
scripts/
src/
tests/
.gitignore
Cargo.lock
Cargo.toml
configuration.yaml
Dockerfile
执行这些命令来生成镜像的过程叫做构建。
使用Docker CLI来操作,我们需要输入以下指令。
docker build -t zero2prod --file Dockerfile .
命令最后的点是干什么的?
构建上下文
docker build的执行依赖两个要素:一个配方(即Dockerfile),以及一个构建上下文(build context)
你可以把正在构建的docker镜像想象成一个完全隔离的环境。
它和本地机器唯一的接触点就是诸如COPY或ADD这样的命令。
而构建上下文则决定了:在执行COPY等命令时,镜像内部能够“看见”你主机上的那些文件。
举个例子,当我们使用.,就是告诉docker: “请把当前目录作为这次构建镜像时的上下文。”
因此,命令
COPY . /app
会将当前目录下的所有文件(包括源代码!)复制到镜像 /app 目录。
使用 . 作为构建上下文同时也意味着:
Docker 不会允许你直接通过 COPY 去访问父目录,或任意指定主机上的其他路径。
根据需求,你也可以使用其他路径,甚至是一个 URL (!) 作为构建上下文。
Sqlx 离线模式
如果你很急,那么你可能已经运行了构建命令……但是你要意识到他是不能正常运行的。
# [...]
Step 4/5 : RUN cargo build --release
# [...]
error: error communicating with the server:
Cannot assign reguested address (os error 99)
--> src/routes/subscriptions.rs:35:5
|
35 | / sqlx: :query!(
36 | | r#"
37 | | INSERT INTO subscriptions (id, email, name, subscribed_at)
38 | | VALUES ($1,$2,$3,$4)
... |
43 | | Utc::now()
44 | | )
| |____-
|
= note: this error originates in a macro
发生了什么?
sqlx 在构建时访问了我们的数据库来确保所有的查询可以被成功的执行。
当我们在docker运行 cargo build 时,显然的,sqlx无法通过.env文件中确定的 DATABASE_URL 环境变量建立到数据库的连接。
如何解决?
我们可以通过--network来在构建镜像时允许镜像去和本地主机运行的数据库通信。这是我们在CI管道中遵循的策略,因为我们无论如何都需要数据库来运行集成测试。
不幸的是,由于在不同的操作系统(例如MACOS)上实施Docker网络会大大损害我们的构建可重现性,这对Docker构建有些麻烦。
更好的选择是sqlx的离线模式。
让我们在Cargo.toml加入sqlx的离线模式feature:
注: 在 0.8.6 版本的sqlx 中, offline mode 默认开启, 见 README
#! Cargo.toml
# [...]
[dependencies.sqlx]
version = "0.8.6"
default-features = false
features = [
"tls-rustls",
"macros",
"postgres",
"uuid",
"chrono",
"migrate",
"runtime-tokio",
]
下一步依赖于 sqlx 的命令行界面 (CLI)。我们要找的命令是 sqlx prepare。我们来看看它的帮助信息:
sqlx prepare --help
Generate query metadata to support offline compile-time verification.
Saves metadata for all invocations of `query!` and related macros to a `.sqlx` directory in the current directory (or workspace root with `--workspace`), overwriting if needed.
During project compilation, the absence of the `DATABASE_URL` environment variable or the presence of `SQLX_OFFLINE` (with a value of `true` or `1`) will constrain the compile-time verification to
only read from the cached query metadata.
Usage: sqlx prepare [OPTIONS] [-- <ARGS>...]
Arguments:
[ARGS]...
Arguments to be passed to `cargo rustc ...`
Options:
--check
Run in 'check' mode. Exits with 0 if the query metadata is up-to-date. Exits with 1 if the query metadata needs updating
--all
Prepare query macros in dependencies that exist outside the current crate or workspace
--workspace
Generate a single workspace-level `.sqlx` folder.
This option is intended for workspaces where multiple crates use SQLx. If there is only one, it is better to run `cargo sqlx prepare` without this option inside that crate.
--no-dotenv
Do not automatically load `.env` files
-D, --database-url <DATABASE_URL>
Location of the DB, by default will be read from the DATABASE_URL env var or `.env` files
[env: DATABASE_URL=postgres://postgres:password@localhost:5432/newsletter]
--connect-timeout <CONNECT_TIMEOUT>
The maximum time, in seconds, to try connecting to the database server before returning an error
[default: 10]
-h, --help
Print help (see a summary with '-h')
换句话说,prepare 执行的操作与调用 cargo build 时通常执行的操作相同, 但它会将这些查询的结果保存到元数据文件 (sqlx-data.json) 中,该文件稍后可以被 sqlx 自身检测到,并用于完全跳过查询并执行离线构建。
让我们调用它吧!
# It must be invoked as a cargo subcommand
# All options after `--` are passed to cargo itself
# We need to point it at our library since it contains
# all our SQL queries.
cargo sqlx prepare -- --lib
query data written to .sqlx in the current directory; please check this into version control
正如命令输出所示,我们确实会将文件提交到版本控制。.
让我们在 Dockerfile 中将 SQLX_OFFLINE 环境变量设置为 true, 以强制 sqlx 查看已保存的元数据,而不是尝试查询实时数据库:
FROM rust:1.89.0
WORKDIR /app
RUN apt update && apt install lld clang -y
COPY . .
ENV SQLX_OFFLINE=true
RUN cargo build --release
ENTRYPOINT ["./target/release/zero2prod"]
让我们试试构建我们的 docker image!
docker build --tag zero2prod --file Dockerfile .
这次应该不会出错了!
不过,我们有一个问题:如何确保 sqlx-data.json 不会不同步(例如,当数据库架构发生变化或添加新查询时)?
我们可以在 CI 流中使用 --check 标志来确保它保持最新状态——请参考本书 GitHub 仓库中更新的管道定义。
运行映像
在构建映像时,我们为其附加了一个标签 zero2prod:
docker build --tag zero2prod --file Dockerfile .
我们可以在其他命令中使用该标签来引用该图像。具体来说,运行以下命令:
docker run zero2prod
docker run 将触发我们在 ENTRYPOINT 语句中指定的命令的执行:
ENTRYPOINT ["./target/release/zero2prod"]
在我们的例子中,它将执行我们的二进制文件,从而启动我们的 API。
接下来,让我们启动我们的镜像!
你应该会立即看到一个错误:
Failed to connect to Postgres.: PoolTimedOut
这是来自我们 main 方法中的这一行:
//! src/main.rs
// [...]
#[tokio::main]
async fn main() -> std::io::Result<()> {
// [...]
let connection_pool = PgPool::connect(&configuration.database.connection_string().expose_secret())
.await
.expect("Failed to connect to Postgres.");
// [...]
}
我们可以通过使用 connect_lazy 来放宽我们的要求——它只会在第一次使用池时尝试建立连接。
//! src/main.rs
// [...]
#[tokio::main]
async fn main() -> std::io::Result<()> {
// [...]
let connection_pool = PgPool::connect_lazy(&configuration.database.connection_string().expose_secret())
.expect("Failed to connect to Postgres.");
// [...]
}
现在我们可以重新构建 Docker 镜像并再次运行它: 你应该会立即看到几行日志!
让我们打开另一个终端,尝试向 health_check 端点发送请求:
curl http://127.0.0.1:8000/health_check
curl: (7) Failed to connect to 127.0.0.1 port 8000: Connection refused
不是很好...
Networking
默认情况下,Docker 镜像不会将其端口暴露给底层主机。我们需要使用 -p 标志显式地进行此操作。
让我们终止正在运行的镜像,然后使用以下命令重新启动它:
docker run -p 8000:8000 zero2prod
尝试访问健康检查端点将触发相同的错误消息。
我们需要深入研究 main.rs 文件来了解原因:
我们使用 127.0.0.1 作为主机地址 - 指示我们的应用程序仅接受来自同一台机器的连接。
然而,我们从主机向 /health_check 发出了一个 GET 请求,而我们的 Docker 镜像不会将其视为本地主机,因此触发了我们刚刚看到的“连接被拒绝”错误。
我们需要使用 0.0.0.0 作为主机地址,以指示我们的应用程序接受来自任何网络接口的连接,而不仅仅是本地接口。
不过,我们需要小心:使用 0.0.0.0 会显著增加我们应用程序的“受众”,并带来一些安全隐患。
最好的方法是使地址的主机部分可配置 - 我们将继续使用 127.0.0.1 进行本地开发,并在 Docker 镜像中将其设置为 0.0.0.0。
//! src/main.rs
#[tokio::main]
async fn main() -> std::io::Result<()> {
// [...]
let address = format!("0.0.0.0:{}", configuration.application_port);
// [...]
}
分层配置
我们的设置结构目前如下所示:
//! src/configuration.rs
// [...]
#[derive(serde::Deserialize)]
pub struct Settings {
pub database: DatabaseSettings,
pub application_port: u16,
}
#[derive(serde::Deserialize)]
pub struct DatabaseSettings {
pub username: String,
pub password: SecretBox<String>,
pub port: u16,
pub host: String,
pub database_name: String,
}
// [...]
让我们引入另一个结构体 ApplicationSettings, 将所有与应用程序地址相关的配置值组合在一起:
//! src/configuration.rs
#[derive(serde::Deserialize)]
pub struct Settings {
pub database: DatabaseSettings,
pub application: ApplicationSettings,
}
#[derive(serde::Deserialize)]
pub struct ApplicationSettings {
pub port: u16,
pub host: String,
}
// [...]
我们需要更新我们的 configuration.yml 文件以匹配新的结构:
#! configuration.yaml
application:
port: 8000
host: 127.0.0.1
database: ...
以及我们的 main.rs,我们将利用新的可配置 host 参数
//! src/main.rs
// [...]
#[tokio::main]
async fn main() {
// [...]
let address = format!("{}:{}", configuration.application.host, configuration.application.port);
// [...]
}
现在可以从配置中读取主机名了,但是如何针对不同的环境使用不同的值呢?
我们需要将配置分层化。
我们来看看 get_configuration, 这个函数负责加载我们的 Settings 结构体:
//! src/configuration.rs
// [...]
pub fn get_configuration() -> Result<Settings, config::ConfigError> {
let settings = config::Config::builder()
.add_source(config::File::with_name("configuration"))
.build()
.unwrap();
settings.try_deserialize()
}
我们正在从名为 configuration 的文件中读取数据,以填充“设置”的字段。configuration.yaml 中指定的值已无进一步调整的空间。
让我们采用更精细的方法。我们将拥有:
- 一个基础配置文件,用于在本地和生产环境中共享的值(例如数据库名称);
- 一组特定于环境的配置文件,用于指定需要根据每个环境进行自定义的字段的值(例如主机);
- 一个环境变量 APP_ENVIRONMENT,用于确定运行环境(例如生产环境或本地环境)。
所有配置文件都将位于同一个顶级目录 configuration 中。 好消息是,我们正在使用的 crate config 开箱即用地支持上述所有功能?
让我们将它们组合起来:
//! src/configuration.rs
// [...]
pub fn get_configuration() -> Result<Settings, config::ConfigError> {
let mut settings = config::Config::builder();
let base_path = std::env::current_dir().expect("Failed to determine the current directory");
let configuration_directory = base_path.join("configuration");
// Read the "default" configuration file
settings = settings
.add_source(config::File::from(configuration_directory.join("base")).required(true));
// Detect the running environment.
// Default to `local` if unspecified.
let environment: Environment = std::env::var("APP_ENVIRONMENT")
.unwrap_or_else(|_| "local".into())
.try_into()
.expect("Failed to parse APP_ENVIRONMENT.");
// Layer on the environment-specific values
settings = settings.add_source(
config::File::from(configuration_directory.join(environment.as_str())).required(true),
);
settings.build().unwrap().try_deserialize()
}
pub enum Environment {
Local,
Production,
}
impl Environment {
pub fn as_str(&self) -> &'static str {
match self {
Environment::Local => "local",
Environment::Production => "production",
}
}
}
impl TryFrom<String> for Environment {
type Error = String;
fn try_from(value: String) -> Result<Self, Self::Error> {
match value.to_lowercase().as_str() {
"local" => Ok(Self::Local),
"production" => Ok(Self::Production),
other => Err(format!(
"{other} is not a supported environment. Use either `local` or `production`."
)),
}
}
}
让我们重构配置文件以适应新的结构。
我们必须删除 configuration.yaml 文件,并创建一个新的配置目录,其中包含 base.yaml、local.yaml 和 production.yaml 文件。
#! configuration/base.yaml
application:
port: 8000
database:
host: "127.0.0.1"
port: 5432
username: "postgres"
password: "password"
database_name: "newsletter"
#! configuration/local.yaml
application:
host: 127.0.0.1
#! configuration/production.yaml
application:
host: 0.0.0.0
现在,我们可以通过使用 ENV 指令设置 PP_ENVIRONMENT 环境变量来指示 Docker 镜像中的二进制文件使用生产配置:
FROM rust:1.89.0
WORKDIR /app
RUN apt update && apt install lld clang -y
COPY . .
ENV SQLX_OFFLINE=true
RUN cargo build --release
ENV APP_ENVIRONMENT=production
ENTRYPOINT ["./target/release/zero2prod"]
让我们重新构建映像并再次启动它:
docker build --tag zero2prod --file Dockerfile .
docker run -p 8000:8000 zero2prod
第一条日志行应该是这样的
{
"name":"zero2prod",
"msg":"Starting \"actix-web-service-0.0.0.0:8000\" service on 0.0.0.0:8000",
}
如果你的运行结果和这个差不多, 这是个好消息 - 配置文件正在按照我们期待的方式工作!
我们再试试请求 health check 端点
curl -v http://127.0.0.1:8080/health_check
* Trying 127.0.0.1:8000...
* Connected to 127.0.0.1 (127.0.0.1) port 8000
* using HTTP/1.x
> GET /health_check HTTP/1.1
> Host: 127.0.0.1:8000
> User-Agent: curl/8.15.0
> Accept: */*
>
* Request completely sent off
< HTTP/1.1 200 OK
< content-length: 0
< date: Sun, 24 Aug 2025 02:40:04 GMT
<
* Connection #0 to host 127.0.0.1 left intact
太棒了, 这能用!
数据库连接
那么 POST /subscriptions 怎么样?
curl --request POST \
--data 'name=le%20guin&email=ursula_le_guin%40gmail.com' \
127.0.0.1:8000/subscriptions --verbose
经过长时间的等待, 服务端返回了 500!
我们看看应用程序日志 (很有用的, 难道不是吗?)
{
"msg": "[SAVING NEW SUBSCRIBER DETAILS IN THE DATABASE - EVENT] \
Failed to execute query: PoolTimedOut",
}
这应该不会让你感到意外——我们将 connect 替换成了 connect_lazy,以避免立即与数据库打交道。
我们等了半分钟才看到返回 500 错误——这是因为 sqlx 中从连接池获取连接的默认超时时间为 30 秒。
让我们使用更短的超时时间,让失败速度更快一些:
//! src/main.rs
// [...]
#[tokio::main]
async fn main() -> std::io::Result<()> {
// [...]
let connection_pool = PgPoolOptions::new()
.acquire_timeout(std::time::Duration::from_secs(2))
.connect_lazy(&configuration.database.connection_string().expose_secret())
.expect("Failed to connect to Postgres.");
// [...]
}
使用 Docker 容器获取有效的本地设置有多种方法:
- 使用 --network=host 运行应用程序容器,就像我们目前对 Postgres 容器所做的那样;
- 使用 docker-compose;
- 创建用户自定义网络。
有效的本地设置并不能让我们在部署到 Digital Ocean 时获得有效的数据库连接。因此,我们暂时先这样。
优化 Docker 映像
就我们的 Docker 镜像而言,它似乎按预期运行了——是时候部署它了!
嗯,还没有。
我们可以对 Dockerfile 进行两项优化,以简化后续工作:
- 减小镜像大小,提高使用速度
- 使用 Docker 层缓存,提高构建速度。
Docker 映像大小
我们不会在托管我们应用程序的机器上运行 docker build。它们将使用 docker pull 下载我们的 Docker 镜像,而无需经历从头构建的过程。
这非常方便:构建镜像可能需要很长时间(Rust 确实如此!),而我们只需支付一次费用。
要实际使用镜像,我们只需支付下载费用,该费用与镜像的大小直接相关。
我们的镜像有多大?
我们可以使用
docker images zero2prod
REPOSITORY TAG IMAGE ID CREATED SIZE
zero2prod latest 01f54e7e0153 8 minutes ago 16.5GB
这是大还是小?
嗯,我们的最终镜像不能小于我们用作基础镜像的 rust。它有多大?
docker images rust:1.89.0
注: 译者这里懒得 docker pull 了, 反正这个映像很大就是了
好的,我们的最终镜像几乎是基础镜像的两倍大。 我们可以做得更好!
我们的第一步是通过排除构建镜像不需要的文件来减小 Docker 构建上下文的大小。
Docker 会在我们的项目中查找一个特定的文件 - .dockerignore 来确定哪些文件应该被忽略。
让我们在根目录中创建一个包含以下内容的文件:
#! .dockerignore
.env
target/
tests/
Dockerfile
scripts/
migrations/
所有符合 .dockerignore 中指定模式的文件都不会被 Docker 作为构建上下文的一部分发送到镜像,这意味着它们不在 COPY 指令的范围内。
如果我们能够忽略繁重的目录(例如 Rust 项目的目标文件夹),这将大大加快我们的构建速度(并减小最终镜像的大小)。
而下一个优化则利用了 Rust 的独特优势之一。
Rust 的二进制文件是静态链接的——我们不需要保留源代码或中间编译工件来运行二进制文件,它是完全独立的。
这与 Docker 的一项实用功能——多阶段构建完美兼容。我们可以将构建分为两个阶段:
builder阶段,用于生成编译后的二进制文件runtime阶段,用于运行二进制文件
修改后的 Dockerfile 如下所示:
# Builder stage
FROM rust:1.89.0 AS builder
WORKDIR /app
RUN apt update && apt install lld clang -y
COPY . .
ENV SQLX_OFFLINE=true
RUN cargo build --release
# Runtime stage
FROM rust:1.89.0
WORKDIR /app
# Copy the compiled binary from the builder environment
# to your runtime env
COPY --from=builder /app/target/release/zero2prod zero2prod
# We need the configuration file at runtime!
COPY configuration configuration
ENV APP_ENVIRONMENT=production
ENTRYPOINT ["./target/release/zero2prod"]
runtime 是我们的最终镜像。
builder 阶段不会影响其大小——它是一个中间步骤,会在构建结束时被丢弃。最终工件中唯一存在的构建器阶段部分就是我们明确复制的内容——编译后的二进制文件!
使用上述 Dockerfile 生成的镜像大小是多少?
docker images zero2prod
只有1.3GB!
只比基础镜像大 20 MB,好太多了!
我们可以更进一步:在运行时阶段,我们不再使用 rust:1.89.0,而是改用 rust:1.589.0-slim,这是一个使用相同底层操作系统的较小镜像。
这比我们一开始的体积小了 4 倍——一点也不差!
我们可以通过减少整个 Rust 工具链和机器(例如 rustc、cargo 等)的重量来进一步缩小体积——运行我们的二进制文件时,这些都不再需要。
我们可以使用裸操作系统 (debian:bullseye-slim) 作为运行时阶段的基础镜像:
# [...]
# Runtime stage
FROM debian:bullseye-slim
WORKDIR /app
RUN apt-get update -y \
&& apt-get install -y
--no-install-recommends openssl
ca-certificates \
# Clean up
&& apt-get autoremove -y \
&& apt-get clean -y \
&& rm -rf /var/lib/apt/lists/*
# Copy the compiled binary from the builder environment
# to your runtime env
COPY --from=builder /app/target/release/zero2prod zero2prod
# We need the configuration file at runtime!
COPY configuration configuration
ENV APP_ENVIRONMENT=production
ENTRYPOINT ["./target/release/zero2prod"]
不到 100 MB——比我们最初的尝试小了约 25 倍。
我们可以通过使用 rust:1.89.0-alpine 来进一步减小文件大小,但我们必须交叉编译到 linux-musl 目标——目前超出了我们的范围。如果您有兴趣生成微型 Docker 镜像,请查看 rust-musl-builder。
进一步减小二进制文件大小的另一种方法是从中剥离符号——您可以在不到 100 MB——比我们最初的尝试小了约 25 倍 42。 我们可以通过使用 rust:1.59.0-alpine 来进一步减小文件大小,但我们必须交叉编译到 linux-musl 目标——目前超出了我们的范围。如果您有兴趣生成微型 Docker 镜像,请查看 rust-musl-builder。 进一步减小二进制文件大小的另一种方法是从中剥离符号——您可以在此处找到 更多信息。找到更多信息。
为Rust Docker 构建缓存
Rust 在运行时表现出色,始终提供卓越的性能,但这也带来了一些代价:编译时间。在 Rust 年度调查中,Rust 项目面临的最大挑战或问题中,编译时间一直是热门话题。
优化构建(--release)尤其令人头疼——对于包含多个依赖项的中型项目,编译时间可能长达 15/20 分钟。这在我们这样的 Web 开发项目中相当常见,因为我们会从异步生态系统(tokio、actix-web、sqlx 等)中引入许多基础 crate。
不幸的是,我们在 Dockerfile 中使用 --release 选项来在生产环境中获得最佳性能。如何缓解这个问题? 我们可以利用 Docker 的另一个特性:层缓存。
Dockerfile 中的每个 RUN、COPY 和 ADD 指令都会创建一个层:执行指定命令后,先前状态(上一层)与当前状态之间的差异。
层会被缓存:如果操作的起始点(例如基础镜像)未发生变化,并且命令本身(例如 COPY 复制的文件的校验和)也未发生变化,Docker 不会执行任何计算,而是直接从本地缓存中获取结果副本。
Docker 层缓存速度很快,可以利用它来大幅提升 Docker 构建速度。
诀窍在于优化 Dockerfile 中的操作顺序:任何引用经常更改的文件(例如源代码)的操作都应尽可能晚地出现,从而最大限度地提高前一步保持不变的可能性,并允许 Docker 直接从缓存中获取结果。
开销最大的步骤通常是编译。
大多数编程语言都遵循相同的策略:首先复制某种类型的锁文件,构建依赖项,然后复制其余源代码,最后构建项目。 只要你的依赖关系树在两次构建之间没有发生变化,这就能保证大部分工作都被缓存。
例如,在一个 Python 项目中,你可能会有类似这样的代码:
FROM python:3
COPY requirements.txt
RUN pip install -r requirements.txt
COPY src/ /app
WORKDIR /app
ENTRYPOINT ["python", "app"]
遗憾的是, cargo 没有提供从其 Cargo.lock 文件开始构建项目依赖项的机制(例如 cargo build --only-deps)。
然而,我们可以依靠社区项目 cargo-chef 来扩展 cargo 的默认功能。
让我们按照 cargo-chef 的 README 中的建议修改 Dockerfile:
注: 不要在构建容器外运行 cargo chef, 防止损坏代码库。 (来自README)
FROM lukemathwalker/cargo-chef:latest-rust-1.89.0 AS chef
WORKDIR /app
RUN apt update && apt install lld clang -y
FROM chef AS planner
COPY . .
# Compute a lock-like file for our project
RUN cargo chef prepare --recipe-path recipe.json
FROM chef AS builder
COPY --from=planner /app/recipe.json recipe.json
# Build our project dependencies, not our application!
RUN cargo chef cook --release --recipe-path recipe.json
# Up to this point, if our dependency tree stays the same,
# all layers should be cached.
COPY . .
ENV SQLX_OFFLINE=true
RUN cargo build --release
# Runtime stage
FROM debian:bullseye-slim
WORKDIR /app
RUN apt-get update -y \
&& apt-get install -y --no-install-recommends openssl ca-certificates \
# Clean up
&& apt-get autoremove -y \
&& apt-get clean -y \
&& rm -rf /var/lib/apt/lists/*
# Copy the compiled binary from the builder environment
# to your runtime env
COPY --from=builder /app/target/release/zero2prod zero2prod
# We need the configuration file at runtime!
COPY configuration configuration
ENV APP_ENVIRONMENT=production
ENTRYPOINT ["./target/release/zero2prod"]
我们使用三个阶段:第一阶段计算配方文件,第二阶段缓存依赖项,然后构建二进制文件,第三阶段是运行时环境。只要依赖项保持不变,recipe.json 文件就会保持不变,因此 cargo chef cook --release --recipe-path recipe.json 的结果会被缓存,从而大大加快构建速度。
我们利用了 Docker 层缓存与多阶段构建的交互方式:planner 阶段中的 COPY . . 语句会使 planner 容器的缓存失效,但只要 cargo chef prepare 返回的 recipe.json 的校验和保持不变, 它就不会使构建器容器的缓存失效。
您可以将每个阶段视为具有各自缓存的 Docker 镜像 - 它们仅在使用 COPY --from 语句时才会相互交互。
这将在下一节中为我们节省大量时间。
部署到 DigitalOcean Apps Platform
注: 本章翻译过程中没有核实内容, 因为译者本人不用这个 Digital Ocean (也没有兴趣为其付费), 他本人认为使用SaaS平台托管自己的服务是不好的. 不要完全跳过本章, 建议还是看一下
我们已经构建了一个(非常棒的)容器化应用程序版本。现在就部署它吧!
设置
您必须在 Digital Ocean 的网站上注册。
注册账户后,请安装 doctl (Digital Ocean 的 CLI)——您可以在此处找到说明。
在 Digital Ocean 的应用平台上托管并非免费——维护我们的应用及其相关数据库的正常运行大约需要每月 20 美元。
我建议您在每次会话结束时销毁该应用——这样可以将您的支出保持在 1 美元以下。我在撰写本章的过程中只花了 0.2 美元!
应用程序规范
Digital Ocean 的应用平台使用声明式配置文件来指定应用程序部署的样子——他们称之为 App Spec。
通过查看参考文档以及一些示例,我们可以拼凑出 App Spec 的初稿。
让我们将这个清单 spec.yaml 放在项目目录的根目录下。
#! spec.yaml
name: zero2prod
# See https://www.digitalocean.com/docs/app-platform/#regional-availability for the available options
# You can get region slugs from https://www.digitalocean.com/docs/platform/availability-matrix/
# `fra` stands for Frankfurt (Germany - EU)
region: fra
services:
- name: zero2prod
# Relative to the repository root
dockerfile_path: Dockerfile
source_dir: .
github:
branch: main
deploy_on_push: true
repo: LukeMathWalker/zero-to-production
# Active probe used by DigitalOcean's to ensure our application is healthy
health_check:
# The path to our health check endpoint! It turned out to be useful in the end!
http_path: /health_check
# The port the application will be listening on for incoming requests
# It should match what we specify in our configuration.yaml file!
http_port: 8000
# For production workloads we'd go for at least two!
instance_count: 1
# Let's keep the bill lean for now...
instance_size_slug: basic-xxs
# All incoming requests should be routed to our app
routes:
- path: /
请花点时间仔细检查所有指定的值,并了解它们的用途。
我们可以使用它们的命令行界面 (CLI) doctl 来首次创建应用程序:
doctl apps create --spec spec.yaml
Error: Unable to initialize DigitalOcean API client: access token is required.
(hint: run 'doctl auth init')
嗯,我们必须先进行身份验证。
我们按照他们的建议来吧:
doctl auth init
Please authenticate doctl for use with your DigitalOcean account.
You can generate a token in the control panel at
https://cloud.digitalocean.com/account/api/tokens
一旦您提供了令牌,我们可以再试一次:
doctl apps create --spec spec.yaml
好的,按照他们的指示关联你的 GitHub 帐户。
第三次就成功了,我们再试一次!
doctl apps create --spec spec.yaml
成功了!
您可以使用以下命令检查应用状态
doctl apps list
或者查看 DigitalOcean 的仪表盘。
虽然应用已成功创建,但尚未运行!
查看他们仪表盘上的“部署”选项卡 - 它可能正在构建 Docker 镜像。
查看他们 bug 跟踪器上最近的一些问题,发现可能需要一段时间 - 不少人都报告了构建速度缓慢的问题。Digital Ocean 的支持工程师建议利用 Docker 层缓存来缓解这个问题 - 我们已经涵盖了所有基础内容!
如果您在 DigitalOcean 上构建 Docker 镜像时遇到内存不足错误,请查看此 GitHub issue。
等待这些行显示在其仪表板构建日志中:
zero2prod | 00:00:20 => Uploaded the built image to the container registry
zero2prod | 00:00:20 => Build complete
部署成功!
您应该能够看到每十秒左右一次的健康检查日志,此时Digital Ocean 平台会 ping 我们的应用程序以确保其正常运行。
doctl apps list
你可以检索应用程序的公开 URI。类似于 https://zero2prod-aaaaa.ondigitalocean.app
现在尝试发送健康检查请求,它应该会返回 200 OK!
请注意,DigitalOcean 通过配置证书并将 HTTPS 流量重定向到我们在应用程序规范中指定的端口,帮我们设置了 HTTPS。这样就省了一件需要担心的事情。
POST /subscriptions 端点仍然失败,就像它在本地失败一样:我们的生产环境中没有支持我们应用程序的实时数据库。
让我们配置一个。
将此段添加到您的 spec.yaml 文件中:
#! spec.yaml
# [...]
databases:
# PG = Postgres
- engine: PG
# Database name
name: newsletter
# Again, let's keep the bill lean
num_nodes: 1
size: db-s-dev-database
# Postgres version - using the latest here
version: "14"
然后更新您的应用规范:
# You can retrieve your app id using `doctl apps list`
doctl apps update YOUR-APP-ID --spec=spec.yaml
DigitalOcean 需要一些时间来配置 Postgres 实例。
与此同时,我们需要弄清楚如何在生产环境中将应用程序指向数据库。
如何使用环境变量注入 secret
连接字符串将包含我们不想提交到版本控制的值 - 例如,数据库根用户的用户名和密码。
我们最好的选择是使用环境变量在运行时将机密信息注入应用程序环境。例如,DigitalOcean 的应用程序可以引用 DATABASE_URL 环境变量(或其他一些更精细的视图)来在运行时获取数据库连接字符串。
我们需要(再次)升级 get_configuration 函数以满足我们的新需求。
//! src/configuration.rs
// [...]
pub fn get_configuration() -> Result<Settings, config::ConfigError> {
let mut settings = config::Config::builder();
let base_path = std::env::current_dir().expect("Failed to determine the current directory");
let configuration_directory = base_path.join("configuration");
// Read the "default" configuration file
settings = settings
.add_source(config::File::from(configuration_directory.join("base")).required(true));
// Detect the running environment.
// Default to `local` if unspecified.
let environment: Environment = std::env::var("APP_ENVIRONMENT")
.unwrap_or_else(|_| "local".into())
.try_into()
.expect("Failed to parse APP_ENVIRONMENT.");
// Layer on the environment-specific values
settings = settings.add_source(
config::File::from(configuration_directory.join(environment.as_str())).required(true),
);
// Add in settings from environment variables (with a prefix of APP and '__' as separator)
// E.g. `APP_APPLICATION__PORT=5001` would set `Settings.application.port`
settings = settings.add_source(config::Environment::with_prefix("app").separator("__"));
settings.build().unwrap().try_deserialize()
}
这使我们能够使用环境变量自定义 Settings 结构体中的任何值,从而覆盖配置文件中指定的值。
为什么这很方便? 它使得注入过于动态(即无法预先知道)或过于敏感而无法存储在版本控制中的值成为可能。
它还可以快速更改应用程序的行为: 如果我们想要调整其中一个值(例如数据库端口),则无需进行完全重建。
对于像 Rust 这样的语言来说,全新构建可能需要十分钟或更长时间,这可能会导致短暂的中断和对客户造成可见影响的严重服务质量下降。
在继续之前,我们先处理一个烦人的细节: 环境变量对于配置包来说,是字符串,如果使用 serde 的标准反序列化例程,它将无法获取整数。
幸运的是,我们可以指定一个自定义反序列化函数。
让我们添加一个新的依赖项,serde-aux(serde 辅助函数):
cargo add serde-aux
然后修改 ApplicationSettings 和 DatabaseSettings
//! src/configuration.rs
// [...]
use serde_aux::prelude::deserialize_number_from_string;
#[derive(serde::Deserialize)]
pub struct DatabaseSettings {
#[serde(deserialize_with = "deserialize_number_from_string")]
pub port: u16,
// [...]
}
#[derive(serde::Deserialize)]
pub struct ApplicationSettings {
#[serde(deserialize_with = "deserialize_number_from_string")]
pub port: u16,
// [...]
}
// [...]
连接到 Digital Ocean 的 Postgres 实例
让我们使用 DigitalOcean 仪表板(Compo- nents -> Database)查看数据库的连接字符串:
postgresql://newsletter:<PASSWORD>@<HOST>:<PORT>/newsletter?sslmode=require
我们当前的 DatabaseSettings 不支持 SSL 模式——这在本地开发中并不适用,但在生产环境中,为客户端/数据库通信提供传输级加密是非常必要的。
在尝试添加新功能之前, 让我们先重构 DatabaseSettings 来腾出空间。
当前版本如下所示:
#[derive(serde::Deserialize)]
pub struct DatabaseSettings {
pub username: String,
pub password: SecretBox<String>,
#[serde(deserialize_with = "deserialize_number_from_string")]
pub port: u16,
pub host: String,
pub database_name: String,
}
impl DatabaseSettings {
pub fn connection_string(&self) -> SecretBox<String> {
// [...]
}
pub fn connection_string_without_db(&self) -> SecretBox<String> {
// [...]
}
}
我们将修改它的两个方法, 使其返回 PgConnectOptions 而不是连接字符串:这将使管理所有这些参数变得更加容易。
//! src/configuration.rs
use sqlx::postgres::PgConnectOptions;
// [...]
impl DatabaseSettings {
pub fn without_db(&self) -> PgConnectOptions {
PgConnectOptions::new()
.host(&self.host)
.username(&self.username)
.password(&self.password.expose_secret())
.port(self.port)
}
pub fn with_db(&self) -> PgConnectOptions {
self.without_db().database(&self.database_name)
}
}
当然我们还得修改 src/main.rs 和 tests/health_check.rs
//! src/main.rs
// [...]
#[tokio::main]
async fn main() -> std::io::Result<()> {
// [...]
let connection_pool = PgPoolOptions::new()
.acquire_timeout(std::time::Duration::from_secs(2))
.connect_lazy_with(configuration.database.with_db());
// [...]
}
//! tests/health_check.rs
// [...]
pub async fn configure_database(config: &DatabaseSettings) -> PgPool {
// Create database
let mut connection = PgConnection::connect_with(&config.without_db())
.await
.expect("Failed to connect to Postgres");
connection
.execute(format!(r#"CREATE DATABASE "{}";"#, config.database_name).as_str())
.await
.expect("Failed to create database.");
// Migrate database
let connection_pool = PgPool::connect_with(config.with_db())
.await
.expect("Failed to connect to Postgres");
sqlx::migrate!("./migrations")
.run(&connection_pool)
.await
.expect("Failed to migrate the database");
connection_pool
}
运行 cargo test 以确保一切正常
我们现在需要在 DatabaseSettings 里增加字段 require_ssl:
//! src/configuration.rs
// [...]
#[derive(serde::Deserialize)]
pub struct DatabaseSettings {
// [...]
pub require_ssl: bool,
}
impl DatabaseSettings {
pub fn without_db(&self) -> PgConnectOptions {
let ssl_mode = if self.require_ssl {
PgSslMode::Require
} else {
// Try an encrypted connection, fallback to unencrypted if it fails
PgSslMode::Prefer
};
PgConnectOptions::new()
.host(&self.host)
.username(&self.username)
.password(&self.password.expose_secret())
.port(self.port)
.ssl_mode(ssl_mode)
}
// [...]
}
我们希望在本地运行应用程序(以及测试套件)时, require_ssl 为 false, 但在生产环境中则为 true。
让我们相应地修改配置文件:
#! configuration/local.yaml
application:
host: 127.0.0.1
database:
# New entry!
require_ssl: false
#! configuration/production.yaml
application:
host: 127.0.0.1
database:
# New entry!
require_ssl: true
注: 调整Sqlx log level 部分已过时, 暂时未找到替代方法
应用程序规范中的环境变量
最后一步:我们需要修改 spec.yaml 清单,以注入所需的环境变量。
#! spec.yaml
name: zero2prod
region: fra
services:
- name: zero2prod
# [...]
envs:
- key: APP_APPLICATION__BASE_URL
scope: RUN_TIME
value: ${APP_URL}
- key: APP_DATABASE__USERNAME
scope: RUN_TIME
value: ${newsletter.USERNAME}
- key: APP_DATABASE__PASSWORD
scope: RUN_TIME
value: ${newsletter.PASSWORD}
- key: APP_DATABASE__HOST
scope: RUN_TIME
value: ${newsletter.HOSTNAME}
- key: APP_DATABASE__PORT
scope: RUN_TIME
value: ${newsletter.PORT}
- key: APP_DATABASE__DATABASE_NAME
scope: RUN_TIME
value: ${newsletter.DATABASE}
databases:
# PG = Postgres
- engine: PG
# Database name
name: newsletter
# [...]
范围设置为 RUN_TIME, 以区分 Docker 构建过程中所需的环境变量和 Docker 镜像启动时所需的环境变量。
我们通过插入 Digital Ocean 平台公开的内容(例如 ${newsletter.PORT})来填充环境变量的值 - 更多详情请参阅其文档。
最后一次 Push
让我们应用新规范
# You can retrieve your app id using `doctl apps list`
doctl apps update YOUR-APP-ID --spec=spec.yaml
并将我们的更改推送到 GitHub 以触发新的部署。
我们现在需要迁移数据库:
DATABASE_URL=YOUR-DIGITAL-OCEAN-DB-CONNECTION-STRING sqlx migrate run
一切准备就绪!
让我们向 /subscriptions 发送一个 POST 请求:
curl --request POST \
--data 'name=le%20guin&email=ursula_le_guin%40gmail.com' \
https://zero2prod-adqrw.ondigitalocean.app/subscriptions \
--verbose
服务器应该会返回 200 OK。
恭喜,您刚刚部署了您的第一个 Rust 应用程序!
据说,Ursula Le Guin 刚刚订阅了您的电子邮件简报!
如果您已经看到这里,我很想获取一张您的 Digital Ocean 仪表板的屏幕截图,以展示正在运行的应用程序!
请将其发送至 rust@lpalmieri.com, 或在 X 上分享,并标记 "Zero To Production In Rust"帐户 zero2prod。
拒绝无效订阅者 第一部分
我们的新闻通讯 API 已上线,托管在云服务提供商处。
我们拥有一套基本的工具来排查可能出现的问题。
我们有一个公开的端点 (POST /subscriptions) 来订阅我们的内容。
我们已经取得了很大进展!
但我们也走了一些弯路: POST /subscriptions 相当...宽松。
我们的输入验证极其有限:我们只需确保姓名和邮箱字段都已提供,其他什么都不用做。
我们可以添加一个新的集成测试,用一些“棘手”的输入来探测我们的 API:
//! tests/health_check.rs
// [...]
#[tokio::test]
async fn subscribe_returns_a_200_when_fields_are_present_but_empty() {
// Arrange
let app = spawn_app().await;
let client = reqwest::Client::new();
let test_cases = vec![
("name=&email=ursula_le_guin%40gmail.com", "empty name"),
("name=Ursula&email=", "empty email"),
("name=Ursula&email=definitely-not-an-email", "invalid email"),
];
for (body, description) in test_cases {
// Act
let response = client
.post(&format!("{}/subscriptions", &app.address))
.header("Content-Type", "application/x-www-form-urlencoded")
.body(body)
.send()
.await
.expect("Failed to execute request.");
// Assert
assert_eq!(
200,
response.status().as_u16(),
"The API did not return a 200 OK when the payload was {}.",
description
);
}
}
不幸的是,新的测试通过了。
尽管所有这些有效载荷显然都是无效的,但我们的 API 还是欣然接受它们,并返回 200 OK。
这些麻烦的订阅者详细信息最终会直接进入我们的数据库,并在我们发送新闻通讯时给我们带来麻烦。
订阅新闻通讯时,我们需要提供两项信息:姓名和电子邮件地址。
本章将重点介绍名称验证: 我们应该注意什么?
- 需求
- 第一个实现
- 验证就像一口漏水的大锅
- 类型驱动开发
- 所有权与不变量
- Panics
- 将错误作为值 - Result
- 深刻的断言错误: claim
- 单元测试
- 处理 Result
- 电子邮件格式
- 基于属性的测试
- Payload 验证
- 小结
需求
域约束
事实证明,姓名很复杂。
试图确定姓名的有效性是徒劳的。请记住,我们选择收集姓名是为了将其用于电子邮件的开头——我们不需要它与一个人的真实身份相匹配,无论这在其地理位置上意味着什么。完全没有必要给我们的用户带来错误或过于规范的验证带来的痛苦。
因此,我们可以简单地要求姓名字段非空(即,它必须至少包含一个非空格字符)。
安全约束
不幸的是,互联网上并非所有人都是好人。
如果有足够的时间,尤其是如果我们的简报获得关注并取得成功,我们必然会吸引恶意访问者的注意。
表单和用户输入是主要的攻击目标——如果它们没有得到适当的清理,它们可能会让攻击者破坏我们的数据库(SQL注入)、在我们的服务器上执行代码、导致我们的服务崩溃,以及执行其他恶意操作。
谢谢,但不用了。
在我们的情况下可能会发生什么?在各种可能的攻击中,我们应该做好哪些准备?
我们正在构建一份电子邮件简报,因此我们将重点关注以下方面:
- 拒绝服务 - 例如,试图关闭我们的服务以阻止其他人注册。 这几乎是任何在线服务的常见威胁;
- 数据盗窃 - 例如,窃取大量的电子邮件地址;
- 网络钓鱼 - 例如,使用我们的服务向受害者发送看似合法的电子邮件,诱骗他们点击某些链接或执行其他操作。
我们是否应该尝试在验证逻辑中应对所有这些威胁?
绝对不是!
但采用分层安全方法是一种很好的做法:通过采取缓解措施来降低堆栈中多个层级的这些威胁的风险(例如,输入验证、避免SQL注入的参数化查询、电子邮件中参数化输入的转义等),即使任何一项检查失败或日后被移除,我们也能降低受到攻击的可能性。
我们应该始终牢记,软件是一个活生生的产物:对系统的整体理解是时间流逝的第一个受害者。
当你第一次写下整个系统时,你的脑海里已经有了它,但下一个接触它的开发人员却不会——至少从一开始就不会。因此,应用程序某个不起眼角落的负载检查可能会消失(例如HTML转义),从而使你暴露于一类攻击(例如网络钓鱼)。
冗余可降低风险。
让我们直奔主题——鉴于我们识别出的威胁类别,我们应该对名称进行哪些验证才能提升我们的安全态势?
我的建议是:
- 强制设置最大长度。我们在 Postgres 中的电子邮件类型为 TEXT,这实际上不受限制——嗯,直到磁盘存储空间开始耗尽为止。名称的形式多种多样,但 256 个字符应该足以满足我们绝大多数用户的需求48——如果不够,我们会礼貌地要求他们输入昵称。
- 拒绝包含麻烦字符的名称。
/()"<>\{}在 URL、SQL 查询和 HTML 片段中相当常见,但在名称49中则不那么常见。禁止使用它们会提高 SQL 注入和网络钓鱼攻击的复杂性。
第一个实现
让我们看一下现在的请求处理程序:
//! src/routes/subscriptions.rs
#[derive(serde::Deserialize)]
pub struct FormData {
email: String,
name: String,
}
#[tracing::instrument(
name = "Adding a new subscriber",
skip(form, pool),
fields(
subscriber_email = %form.email,
subscriber_name = %form.name,
)
)]
pub async fn subscribe(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
match insert_subscriber(&pool, &form).await {
Ok(_) => HttpResponse::Ok().finish(),
Err(_) => HttpResponse::InternalServerError().finish(),
}
}
// [...]
我们的新验证应该放在哪里?
第一个草图可能看起来像这样:
// An extension trait to provide the `graphemes` method
// on `String` and `&str`
use unicode_segmentation::UnicodeSegmentation;
pub async fn subscribe(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
if !is_valid_name(&form.name) {
return HttpResponse::BadRequest().finish();
}
match insert_subscriber(&pool, &form).await {
Ok(_) => HttpResponse::Ok().finish(),
Err(_) => HttpResponse::InternalServerError().finish(),
}
}
/// Returns `true` if the input satisfies all our validation constrains
/// on subscriber names, `false` otherwise.
pub fn is_valid_name(s: &str) -> bool {
// `.trim()` returns a view over the input `s` without trailing
// whitespace-like characters.
// `.is_empty` checks if the view contains any character.
let is_empty_or_whitespace = s.trim().is_empty();
// A grapheme is defined by the Unicode standard as a "user-perceived"
// character: `å` is a single grapheme, but it is composed of two characters
// (`a` and `̊`).
//
// `graphemes` returns an iterator over the graphemes in the input `s`.
// `true` specifies that we want to use the extended grapheme definition set,
// the recommended one.
let is_too_long = s.graphemes(true).count() > 256;
// Iterate over all characters in the input `s` to check if any of them matches
// one of the characters in the forbidden array.
let forbidden_characters = ['/', '(', ')', '"', '<', '>', '\\', '{', '}'];
let contains_forbidden_characters = s.chars().any(|g| forbidden_characters.contains(&g));
// Return `false` if any of our conditions have been violated
!(is_empty_or_whitespace || is_too_long || contains_forbidden_characters)
}
为了成功编译新函数,我们必须将 unicode-segmentation crate 添加到我们的依赖项中:
cargo add unicode-segmentation
虽然它看起来是一个完美的解决方案(假设我们添加一堆测试),但像 is_valid_name 这样的函数会给我们一种虚假的安全感。
验证就像一口漏水的大锅
让我们把注意力转移到 insert_subscriber 函数上。
假设它要求 form.name 非空,否则就会发生一些可怕的事情(例如,引发panic!)。
insert_subscriber 函数能安全地假设 form.name 非空吗?
仅从它的类型来看,显然不行:form.name 是一个字符串。它的内容没有任何保证。
如果你完整地看一下我们的程序,你可能会说:我们在请求处理程序的底层检查它是否非空,因此我们可以安全地假设每次调用 insert_subscriber 函数时,form.name 都会非空。
但为了做出这样的断言,我们必须从局部方法(让我们看看这个函数的参数)转变为全局方法(让我们扫描整个代码库)。
虽然对于像我们这样的小型项目来说,这或许可行,但检查函数 (insert_subscriber) 的所有调用点以确保事先执行了某个验证步骤,这在大型项目中很快就会变得不可行。
如果我们坚持使用 is_valid_name,唯一可行的方法就是在 insert_subscriber 函数中再次验证 form.name,以及所有其他要求名称非空的函数。
这才是我们真正确保不变量在需要的地方存在的唯一方法。
如果 insert_subscriber 变得太大,我们不得不将其拆分成多个子函数,会发生什么情况?如果它们需要不变量,那么每个子函数都必须执行验证以确保其成立。
正如您所见,这种方法无法扩展。
这里的问题是 is_valid_name 是一个验证函数:它告诉我们,在程序执行流程的某个时刻,一组条件得到了验证。
但是,关于输入数据中附加结构的信息并没有存储在任何地方。它会立即丢失。
程序的其他部分无法有效地重用它——它们被迫执行另一次时间点检查,导致代码库拥挤,每一步都充满噪音(且浪费)的输入检查。
我们需要的是一个解析函数——一个接受非结构化输入的例程,如果一组条件成立,则返回一个更结构化的输出,这个输出在结构上保证我们关心的不变量从那一刻起一直成立。
怎么做?
使用类型!
类型驱动开发
让我们在项目中添加一个新模块,域,并在其中定义一个新的结构, SubscriberName:
//! src/lib.rs
// [...]
pub mod domain;
//! src/domain.rs
pub struct SubscriberName(String);
SubscriberName 是一个元组结构体,它是一种新类型,包含一个 String 类型的(未命名)字段。
SubscriberName 是一个真正的新类型,而不仅仅是一个别名——它不继承 String 上的任何方法,尝试将 String 赋值给 SubscriberName 类型的变量会触发编译器错误,例如:
let name: SubscriberName = "A string".to_string();
error[E0308]: mismatched types
--> src/main.rs:10:32
|
10 | let name: SubscriberName = "A string".to_string();
| -------------- ^^^^^^^^^^^^^^^^^^^^^^ expected `SubscriberName`,
found `String`
| |
| expected due to this
For more information about this error, try `rustc --explain E0308`.
根据我们当前的定义, SubscriberName 的内部字段是私有的:它只能根据 Rust 的可见性规则从域模块内的代码访问。
一如既往,信任但要验证:如果我们尝试在订阅请求处理程序中构建一个 SubscriberName 会发生什么?
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
let subscriber_name = crate::domain::SubscriberName(form.name.clone());
// [...]
}
编译器会报错
error[E0603]: tuple struct constructor `SubscriberName` is private
--> src/routes/subscriptions.rs:22:42
|
22 | let subscriber_name = crate::domain::SubscriberName(form.name.clone());
| ^^^^^^^^^^^^^^ private tuple struct con
structor
|
::: src/domain.rs:1:27
|
1 | pub struct SubscriberName(String);
| ------ a constructor is private if any of the fields i
s private
|
note: the tuple struct constructor `SubscriberName` is defined here
--> src/domain.rs:1:1
|
1 | pub struct SubscriberName(String);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
因此,就目前情况而言,在域模块之外构建 SubscriberName 实例是不可能的。
让我们为 SubscriberName 添加一个新方法:
//! src/domain.rs
use unicode_segmentation::UnicodeSegmentation;
pub struct SubscriberName(String);
impl SubscriberName {
/// Returns an instance of `SubscriberName` if the input satisfies all
/// our validation constraints on subscriber names.
/// It panics otherwise.
pub fn parse(s: String) -> SubscriberName {
// `.trim()` returns a view over the input `s` without trailing
// whitespace-like characters.
// `.is_empty` checks if the view contains any character.
let is_empty_or_whitespace = s.trim().is_empty();
// A grapheme is defined by the Unicode standard as a "user-perceived"
// character: `å` is a single grapheme, but it is composed of two characters
// (`a` and `̊`).
//
// `graphemes` returns an iterator over the graphemes in the input `s`.
// `true` specifies that we want to use the extended grapheme definition set,
// the recommended one.
let is_too_long = s.graphemes(true).count() > 256;
// Iterate over all characters in the input `s` to check if any of them matches
// one of the characters in the forbidden array.
let forbidden_characters = ['/', '(', ')', '"', '<', '>', '\\', '{', '}'];
let contains_forbidden_characters = s.chars().any(|g| forbidden_characters.contains(&g));
if is_empty_or_whitespace || is_too_long || contains_forbidden_characters {
panic!("{s} is not a valid subscriber name");
} else {
Self(s)
}
}
}
是的,你说得对——这简直就是对 is_valid_name 的厚颜无耻的复制粘贴。
不过,有一个关键的区别:返回类型。
is_valid_name 返回一个布尔值,而 parse 方法如果所有检查都成功,则会返回一个 SubscriberName。
还有更多!
parse 是在域模块之外构建 SubscriberName 实例的唯一方法——我们
在前面几段中已经验证过这一点。
因此,我们可以断言,任何 SubscriberName 实例都将满足我们所有的验证约束。
我们已经确保 SubscriberName 实例不可能违反这些约束。
让我们定义一个新的结构体,NewSubscriber:
//! src/domain.rs
// [...]
pub struct NewSubscriber {
pub email: String,
pub name: SubscriberName,
}
pub struct SubscriberName(String);
// [...]
如果我们将 insert_subscriber 改为接受 NewSubscriber 类型的参数而不是 FormData 类型,会发生什么情况?
pub async fn insert_subscriber(
pool: &PgPool,
new_subscriber: &NewSubscriber,
) -> Result<(), sqlx::Error> {
// [...]
}
有了新的签名,我们可以确保 new_subscriber.name 非空——不可能通过传递空的订阅者名称来调用 insert_subscriber。
我们只需查找函数参数的类型定义即可得出这个结论——我们可以再次进行本地判断,而无需去检查函数的所有调用点。
花点时间回顾一下刚刚发生的事情:我们从一组需求开始(所有订阅者名称都必须验证一些约束),我们发现了一个潜在的陷阱(我们可能会在调用 insert_subscriber 之前忘记验证输入),然后我们利用 Rust 的类型系统彻底消除了这个陷阱。
我们通过构造使一个错误的使用模式变得不可表示——它将无法编译。
这种技术被称为类型驱动开发。
类型驱动开发是一种强大的方法,它可以将我们试图在类型系统内部建模的领域的约束进行编码,并依靠编译器来确保它们得到强制执行。
我们的编程语言的类型系统越具有表达力,我们就能越严格地限制我们的代码,使其只能表示在我们所工作的领域中有效的状态。
Rust 并没有发明类型驱动开发——它已经存在了一段时间,尤其是在函数式编程社区(Haskell、F#、OCaml 等)。Rust“只是”为您提供了一个具有足够表达力的类型系统,可以充分利用过去几十年来在这些语言中开创的许多设计模式。我们刚刚展示的特定模式在 Rust 社区中通常被称为“新型模式”。
在实现过程中,我们将逐步涉及类型驱动开发,但我强烈建议您查看本章脚注中提到的一些资源: 它们是任何开发人员的宝库。
所有权与不变量
我们修改了 insert_subscriber 的签名,但尚未修改主体以符合新的要求——现在就修改吧。
//! src/routes/subscriptions.rs
// [...]
#[tracing::instrument(/*[...]*/)]
pub async fn subscribe(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
let new_subscriber = NewSubscriber {
email: form.0.email,
name: SubscriberName::parse(form.0.name),
};
match insert_subscriber(&pool, &new_subscriber).await {
Ok(_) => HttpResponse::Ok().finish(),
Err(_) => HttpResponse::InternalServerError().finish(),
}
}
#[tracing::instrument(
name = "Saving new subscriber details in the database",
skip(new_subscriber, pool)
)]
pub async fn insert_subscriber(pool: &PgPool, new_subscriber: &NewSubscriber) -> Result<(), sqlx::Error> {
sqlx::query!(
r#"
INSERT INTO subscriptions (id, email, name, subscribed_at)
VALUES ($1, $2, $3, $4)
"#,
Uuid::new_v4(),
new_subscriber.email,
new_subscriber.name,
Utc::now()
)
.execute(pool)
.await
.inspect_err(|e| {
tracing::error!("Failed to execute query: {:?}", e);
})?;
Ok(())
}
我们很接近了, 但 cargo check 还没办法通过:
error[E0308]: mismatched types
--> src/routes/subscriptions.rs:46:9
|
46 | new_subscriber.name,
| ^^^^^^^^^^^^^^
| |
| expected `&str`, found `SubscriberName`
| expected due to the type of this binding
error[E0277]: the trait bound `SubscriberName: sqlx::Encode<'_, Postgres>` is no
t satisfied
这里有一个问题: 我们没有任何方法可以真正访问封装在 SubscriberName 中的字符串值!
我们可以将 SubscriberName 的定义从 SubscriberName(String) 改为 SubscriberName(pubString),但这样一来,我们就会失去前两节中提到的所有好处:
- 其他开发者可以绕过解析,使用任意字符串构建
SubscriberName
let liar = SubscriberName("".to_string());
- 其他开发者可能仍然会选择使用 parse 来构建 SubscriberName,但他们随后可以选择将内部值更改为不再满足我们关心的约束的值
let mut started_well = SubscriberName::parse("A valid name".to_string());
started_well.0 = "".to_string();
我们可以做得更好——这正是 Rust 所有权系统的优势所在! 给定结构体中的某个字段,我们可以选择:
- 通过值暴露它,使用消耗结构体本身:
impl SubscriberName {
pub fn inner(self) -> String {
// The caller gets the inner string,
// but they do not have a SubscriberName anymore!
// That's because `inner` takes `self` by value,
// consuming it according to move semantics
self.0
}
}
- 暴露可变引用
```rs
impl SubscriberName {
pub fn inner_mut(&mut self) -> &mut str {
// The caller gets a mutable reference to the inner string.
// This allows them to perform *arbitrary* changes to
// value itself, potentially breaking our invariants!
&mut self.0
}
}
暴露引用
impl SubscriberName {
pub fn inner_ref(&self) -> &str {
// The caller gets a shared reference to the inner string.
// This gives the caller **read-only** access,
// they have no way to compromise our invariants!
&self.0
}
}
inner_mut 并非我们想要的效果——失去对不变量的控制,相当于使用 SubscriberName(pub String)。
inner 和 inner_ref 都适用,但 inner_ref 更好地传达了我们的意图:
让调用者有机会读取值,但无法对其进行修改。
让我们将 inner_ref 添加到 SubscriberName 中——然后我们可以修改 insert_subscriber 来使用它:
//! src/routes/subscriptions.rs
// [...]
#[tracing::instrument(
name = "Saving new subscriber details in the database",
skip(new_subscriber, pool)
)]
pub async fn insert_subscriber(pool: &PgPool, new_subscriber: &NewSubscriber) -> Result<(), sqlx::Error> {
sqlx::query!(
r#"
INSERT INTO subscriptions (id, email, name, subscribed_at)
VALUES ($1, $2, $3, $4)
"#,
Uuid::new_v4(),
new_subscriber.email,
// Using `inner_ref`!
new_subscriber.name.inner_ref(),
Utc::now()
)
.execute(pool)
.await
.inspect_err(|e| {
tracing::error!("Failed to execute query: {:?}", e);
})?;
Ok(())
}
轰隆,编译成功了!
AsRef
虽然我们的 inner_ref 方法完成了任务,但我必须指出,Rust 的标准库公开了一个专为此类用法而设计的特性——AsRef。
其定义非常简洁:
pub trait AsRef<T>
where
T: ?Sized,
{
// Required method
fn as_ref(&self) -> &T;
}
什么时候应该为某个类型实现 AsRef<T>?
当该类型与 T 足够相似,以至于我们可以使用 &self 来获取 T 自身的引用时!
这听起来是不是太抽象了?再看看 inner_ref 的签名:它本质上就是为 SubscriberName 实现的 AsRef<str>!
AsRef 可以用来提升用户体验——让我们考虑一个具有以下签名的函数:
pub fn do_something_with_a_string_slice(s: &str) {
// [...]
}
没什么太复杂的,但你可能需要花点时间弄清楚 SubscriberName 是否能提供 &str ,以及如何提供,尤其是当该类型来自第三方库时。
我们可以通过更改 do_something_with_a_string_slice 的签名来让体验更加无缝:
// We are constraining T to implement the AsRef<str> trait
// using a trait bound - `T: AsRef<str>`
pub fn do_something_with_a_string_slice<T: AsRef<str>>(s: T) {
let s = s.as_ref();
// [...]
}
我们现在可以写
let name = SubscriberName::parse("A valid name".to_string());
do_something_with_a_string_slice(name)
它会立即编译通过(假设 SubscriberName 实现了 AsRef<str> 接口)。
这种模式被广泛使用,例如,在 Rust 标准库 std::fs 中的文件系统模块中。像 create_dir 这样的函数接受一个 P 类型的参数,并强制要求实现 AsRef<Path> 接口,而不是强迫用户理解如何将 String 转换为 Path,或者如何将 PathBuf 转换为 Path,或者 OsString,等等...你懂的。
该标准库中还有其他一些像 AsRef 这样的小转换特性——它们为整个生态系统提供了一个共享的接口,以便围绕它们进行标准化。为你的类型实现这些特性,可以立即解锁大量通过现有的 crate 中的泛型类型公开的功能。
我们稍后会介绍其他一些转换特性(例如 From/Into、TryFrom/TryInto)。
让我们删除 inner_ref 并为 SubscriberName 实现 AsRef<str>:
//! src/domain.rs
// [...]
impl AsRef<str> for SubscriberName {
fn as_ref(&self) -> &str {
&self.0
}
}
我们还需要修改 insert_subscriber:
//! src/routes/subscriptions.rs
// [...]
pub async fn insert_subscriber(pool: &PgPool, new_subscriber: &NewSubscriber) -> Result<(), sqlx::Error> {
sqlx::query!(
r#"
INSERT INTO subscriptions (id, email, name, subscribed_at)
VALUES ($1, $2, $3, $4)
"#,
Uuid::new_v4(),
new_subscriber.email,
// Using `as_ref` now!
new_subscriber.name.as_ref(),
Utc::now()
)
.execute(pool)
.await
.inspect_err(|e| {
tracing::error!("Failed to execute query: {:?}", e);
})?;
Ok(())
}
该项目可以编译通过...
Panics
...但是我们的测试结果并不理想:
running 4 tests
test subscribe_returns_a_200_when_fields_are_present_but_empty ... FAILED
test subscribe_returns_a_200_for_valid_form_data ... ok
test subscribe_returns_a_400_when_data_is_missing ... ok
test health_check_works ... ok
failures:
---- subscribe_returns_a_200_when_fields_are_present_but_empty stdout ----
thread 'actix-server worker 0' panicked at src/domain.rs:33:13:
is not a valid subscriber name
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
thread 'subscribe_returns_a_200_when_fields_are_present_but_empty' panicked at t
ests/health_check.rs:179:14:
Failed to execute request.: reqwest::Error { kind: Request, url: "http://127.0.0
.1:42035/subscriptions", source: hyper_util::client::legacy::Error(SendRequest,
hyper::Error(IncompleteMessage)) }
好的一面是:我们不再为空名称返回 200 OK 错误。
不好的一面是: 我们的 API 会突然终止请求处理,导致客户端
观察到 IncompleteMessage 错误。这不太优雅。
让我们修改测试以反映我们的新期望:当有效负载包含无效数据时,我们希望看到 400 Bad Request 响应。
//! tests/health_check.rs
// [...]
async fn subscribe_returns_a_200_when_fields_are_present_but_invalid() {
// Arrange
let app = spawn_app().await;
let client = reqwest::Client::new();
let test_cases = vec![
("name=&email=ursula_le_guin%40gmail.com", "empty name"),
("name=Ursula&email=", "empty email"),
("name=Ursula&email=definitely-not-an-email", "invalid email"),
];
for (body, description) in test_cases {
// Act
let response = client
.post(&format!("{}/subscriptions", &app.address))
.header("Content-Type", "application/x-www-form-urlencoded")
.body(body)
.send()
.await
.expect("Failed to execute request.");
// Assert
assert_eq!(
// Not 200 anymore!
400,
response.status().as_u16(),
"The API did not return a 400 OK when the payload was {}.",
description
);
}
}
现在,让我们看看根本原因——当 SubscriberName::parse 中的验证检查失败时,我们选择 panic:
//! src/domain.rs
// [...]
pub fn parse(s: String) -> SubscriberName {
// [...]
if is_empty_or_whitespace || is_too_long || contains_forbidden_characters {
panic!("{s} is not a valid subscriber name");
} else {
Self(s)
}
}
Rust 中的 panic 用于处理不可恢复的错误: 意料之外的故障模式,或者我们无法有效恢复的故障模式。例如,主机内存不足或磁盘已满。Rust 的 panic 并不等同于 Python、C# 或 Java 等语言中的异常。虽然 Rust 提供了一些工具来捕获(某些) panic, 但这绝对不是推荐的方法,应该谨慎使用。Burntsushi 几年前在 Reddit 的一个帖子中就曾明确指出:
[...] 如果您的 Rust 应用程序在响应任何用户输入时出现 panic,则以下情况应该为真:您的应用程序存在错误,无论该错误存在于库中还是主应用程序代码中。
从这个角度来看,我们可以理解正在发生的事情: 当我们的请求处理程序发生恐慌时,actix-web 会认为发生了可怕的事情,并立即丢弃正在处理该 panic 请求的工作进程。
如果恐慌不是解决问题的办法,我们应该用什么来处理可恢复的错误?
将错误作为值 - Result
Rust 的主要错误处理机制建立在 Result 类型之上:
enum Result<T, E> {
Ok(T),
Err(E),
}
Result 用作易出错操作的返回类型: 如果操作成功,则返回 Ok(T); 如果失败,则返回 Err(E)。
我们实际上已经使用过 Result 了,尽管当时我们并没有停下来讨论它的细微差别。
让我们再看一下 insert_subscriber 的签名:
//! src/routes/subscriptions.rs
// [...]
pub async fn insert_subscriber(
pool: &PgPool,
new_subscriber: &NewSubscriber,
) -> Result<(), sqlx::Error> {
// [...]
}
它告诉我们,在数据库中插入订阅者是一个容易出错的操作——如果一切按计划进行,我们不会收到任何返回(() - 单位类型),如果出现问题,我们将收到一个 sqlx::Error,其中包含出错的详细信息(例如连接问题)。
将错误作为值,与 Rust 的枚举相结合,是构建健壮错误处理机制的绝佳基石。
如果你之前使用的语言支持基于异常的错误处理,那么这可能会带来翻天覆地的变化:我们需要了解的关于函数故障模式的一切都包含在它的签名中。
你无需深入研究依赖项的文档来了解某个函数可能抛出的异常(假设它事先已记录在案!)。
你不会在运行时对另一个未记录的异常类型感到惊讶。你不必“以防万一”地插入一个 catch-all 语句。
我们将在这里介绍基础知识,并将更详细的细节(Error trait)留到下一章。
在 parse 中加入 Result 返回值
让我们重构一下 SubscriberName::parse 函数,让它返回一个 Result,而不是因为输入无效而 panic。
我们先修改一下签名,但不修改函数体:
//! src/domain.rs
// [...]
impl SubscriberName {
pub fn parse(s: String) -> Result<SubscriberName, ???> {
// [...]
}
}
我们应该使用什么类型作为 Result 的 Err 变量?
最简单的选择是字符串 - 失败时我们只会返回一条错误消息。
impl SubscriberName {
pub fn parse(s: String) -> Result<SubscriberName, String> {
// [...]
}
}
运行 cargo check 会产生两个错误:
error[E0308]: mismatched types
--> src/routes/subscriptions.rs:25:15
|
25 | name: SubscriberName::parse(form.0.name),
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ expected `SubscriberName`,
found `Result<SubscriberName, String>`
|
= note: expected struct `SubscriberName`
found enum `Result<SubscriberName, std::string::String>`
help: consider using `Result::expect` to unwrap the `Result<SubscriberName, std:
:string::String>` value, panicking if the value is a `Result::Err`
|
25 | name: SubscriberName::parse(form.0.name).expect("REASON"),
| +++++++++++++++++
error[E0308]: mismatched types
--> src/domain.rs:20:13
|
11 | pub fn parse(s: String) -> Result<SubscriberName, String> {
| ------------------------------ expected `Res
ult<SubscriberName, std::string::String>` because of return type
...
20 | Self(s)
| ^^^^^^^ expected `Result<SubscriberName, String>`, found `Subsc
riberName`
|
= note: expected enum `Result<SubscriberName, std::string::String>`
found struct `SubscriberName`
help: try wrapping the expression in `Ok`
|
20 | Ok(Self(s))
| +++ +
For more information about this error, try `rustc --explain E0308`.
error: could not compile `zero2prod` (lib) due to 2 previous errors
让我们关注第二个错误:在 parse 结束时,我们无法返回一个 SubscriberName 的裸实例——我们需要在两个 Result 变体中选择一个。
编译器理解了这个问题,并建议了正确的修改:使用 Ok(Self(s)) 而不是 Self(s)。
让我们遵循它的建议:
//! src/domain.rs
// [...]
impl SubscriberName {
pub fn parse(s: String) -> Result<SubscriberName, String> {
// [...]
if is_empty_or_whitespace || is_too_long || contains_forbidden_characters {
panic!("{s} is not a valid subscriber name");
} else {
Ok(Self(s))
}
}
}
cargo check 现在应该返回一个错误:
error[E0308]: mismatched types
--> src/routes/subscriptions.rs:25:15
|
25 | name: SubscriberName::parse(form.0.name),
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ expected `SubscriberName`,
found `Result<SubscriberName, String>`
|
= note: expected struct `SubscriberName`
found enum `Result<SubscriberName, std::string::String>`
help: consider using `Result::expect` to unwrap the `Result<SubscriberName, std:
:string::String>` value, panicking if the value is a `Result::Err`
|
25 | name: SubscriberName::parse(form.0.name).expect("REASON"),
| +++++++++++++++++
For more information about this error, try `rustc --explain E0308`.
error: could not compile `zero2prod` (lib) due to 1 previous error
它抱怨我们在 subscribe 中调用 parse 方法: 当 parse 返回一个 SubscriberName 时,将其输出直接赋值给 Subscriber.name 是完全没问题的。
现在我们返回一个 Result —— Rust 的类型系统迫使我们处理这条不愉快的路径。我们不能假装它不会发生。
不过,我们先避免一下子讲太多——为了让项目尽快再次编译,我们暂时只在验证失败时触发 panic:
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
let new_subscriber = NewSubscriber {
email: form.0.email,
// Notice the usage of `expect` to specify a meaningful panic message
name: SubscriberName::parcse(form.0.name).expect("Name validation failed."),
};
// [...]
}
cargo check 现在应该很顺利了。
该进行测试了!
深刻的断言错误: claim
我们的大多数断言都类似于 assert!(result.is_ok()) 或 assert!(result.is_err())。
使用这些断言时,Cargo Test 失败时返回的错误消息非常糟糕。
到底有多糟糕?让我们来做个快速实验!
如果你在这个虚拟测试上运行 cargo test:
#[test]
fn dummy_fail() {
let result: Result<&str, &str> = Err("The app crashed due to an IO error");
assert!(result.is_ok());
}
将会输出
---- dummy_fail stdout ----
thread 'dummy_fail' panicked at 'assertion failed: result.is_ok()'
我们无法获得任何有关错误本身的详细信息——这会让调试过程变得相当痛苦。
我们将使用 claim crate 来获取更多信息丰富的错误消息:
cargo add claim
claim 提供了相当全面的断言,可以处理常见的 Rust 类型——特别是 Option 和 Result。
如果我们重写 dummy_fail 测试并使用 claim crate
#[test]
fn dummy_fail() {
let result: Result<&str, &str> = Err("The app crashed due to an IO error");
claim::assert_ok!(result);
}
将会输出
---- dummy_fail stdout ----
thread 'dummy_fail' panicked at 'assertion failed, expected Ok(..),
got Err("The app crashed due to an IO error")'
好多了。
单元测试
一切准备就绪——让我们向域模块添加一些单元测试,以确保我们编写的所有代码都能按预期运行。
//! src/domain.rs
// [...]
#[cfg(test)]
mod tests {
use claim::{assert_err, assert_ok};
use crate::domain::SubscriberName;
#[test]
fn a_256_grapheme_log_name_is_valid() {
let name = "a".repeat(256);
assert_ok!(SubscriberName::parse(name));
}
#[test]
fn a_name_longer_than_256_graphemes_is_rejected() {
let name = "a".repeat(257);
assert_err!(SubscriberName::parse(name));
}
#[test]
fn whitespace_only_names_are_rejected() {
let name = " ".to_string();
assert_err!(SubscriberName::parse(name));
}
#[test]
fn empty_string_is_rejected() {
let name = "".to_string();
assert_err!(SubscriberName::parse(name));
}
#[test]
fn names_containing_an_invalid_character_are_rejected() {
let name = "".to_string();
assert_err!(SubscriberName::parse(name));
}
#[test]
fn a_valid_name_is_parsed_successfully() {
let name = "Zhangzhiyu".to_string();
assert_ok!(SubscriberName::parse(name));
}
}
不幸的是, 它不能编译 - cargo 突出显示了我们对 assert_ok/assert_err 的所有用法
error[E0277]: `SubscriberName` doesn't implement `std::fmt::Debug`
--> src/domain.rs:64:9
|
64 | assert_err!(SubscriberName::parse(name));
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
| |
| `SubscriberName` cannot be formatted using `{:?}` because it doesn'
t implement `std::fmt::Debug`
| required by this formatting parameter
|
声明需要我们的类型实现 Debug trait,以便提供这些友好的错误信息。让我们在 SubscriberName 上添加一个 #[derive(Debug)] 属性:
//! src/domain.rs
// [...]
#[derive(Debug)]
pub struct SubscriberName(String);
编译器现在应该没问题了。测试怎么样?
cargo test
running 6 tests
test domain::tests::empty_string_is_rejected ... FAILED
test domain::tests::a_valid_name_is_parsed_successfully ... ok
test domain::tests::names_containing_an_invalid_character_are_rejected ... FAILE
D
test domain::tests::whitespace_only_names_are_rejected ... FAILED
test domain::tests::a_256_grapheme_log_name_is_valid ... ok
test domain::tests::a_name_longer_than_256_graphemes_is_rejected ... FAILED
failures:
---- domain::tests::empty_string_is_rejected stdout ----
thread 'domain::tests::empty_string_is_rejected' panicked at src/domain.rs:19:13
:
is not a valid subscriber name
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
---- domain::tests::names_containing_an_invalid_character_are_rejected stdout --
--
thread 'domain::tests::names_containing_an_invalid_character_are_rejected' panic
ked at src/domain.rs:19:13:
is not a valid subscriber name
---- domain::tests::whitespace_only_names_are_rejected stdout ----
thread 'domain::tests::whitespace_only_names_are_rejected' panicked at src/domai
n.rs:19:13:
is not a valid subscriber name
---- domain::tests::a_name_longer_than_256_graphemes_is_rejected stdout ----
thread 'domain::tests::a_name_longer_than_256_graphemes_is_rejected' panicked at
src/domain.rs:19:13:
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
aaaaaaaaaaaaaaaaa is not a valid subscriber name
failures:
domain::tests::a_name_longer_than_256_graphemes_is_rejected
domain::tests::empty_string_is_rejected
domain::tests::names_containing_an_invalid_character_are_rejected
domain::tests::whitespace_only_names_are_rejected
test result: FAILED. 2 passed; 4 failed; 0 ignored; 0 measured; 0 filtered out;
finished in 0.00s
error: test failed, to rerun pass `--lib`
所有要求失败的路径测试都失败了,因为我们仍然在验证约束不满足的时候panic——让我们改变它:
//! src/domain.rs
// [...]
impl SubscriberName {
pub fn parse(s: String) -> Result<SubscriberName, String> {
// [...]
if is_empty_or_whitespace || is_too_long || contains_forbidden_characters {
// Replacing `panic!` with `Err(...)`
Err(format!("{s} is not a valid subscriber name"))
} else {
Ok(Self(s))
}
}
}
现在,我们所有的领域单元测试都通过了——让我们最终解决本章开头编写的失败的集成测试。
处理 Result
SubscriberName::parse 现在返回的是 Result, 但 subscribe 调用了 expect 方法,因此
如果返回 Err 变量,就会触发 panic。
整个应用程序的行为没有任何变化。
我们如何修改 subscribe,使其在验证错误时返回 400 Bad Request 错误? 我们可以看看我们在 insert_subscriber 调用中已经做了什么!
match
我们如何处理调用方发生故障的可能性?
//! src/routes/subscriptions.rs
// [...]
pub async fn insert_subscriber(
pool: &PgPool,
new_subscriber: &NewSubscriber,
) -> Result<(), sqlx::Error> {
// [...]
}
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(
form: web::Form<FormData>,
pool: web::Data<PgPool>,
) -> HttpResponse {
// [...]
match insert_subscriber(&pool, &new_subscriber).await {
Ok(_) => HttpResponse::Ok().finish(),
Err(_) => HttpResponse::InternalServerError().finish(),
}
}
insert_subscriber 返回 Result<(), sqlx::Error> , 而 subscribe 使用的是 REST API 的语言——它的输出必须是 HttpResponse 类型。为了在错误情况下向调用者返回 HttpResponse, 我们需要将 sqlx::Error 转换为 REST API 技术领域内合理的表示形式——在我们的例子中,是 500 Internal Server Error。
这时 match 就派上用场了:我们告诉编译器在 Ok 和 Err 两种情况下该做什么。
? 操作符
说到错误处理,让我们再看一下 insert_subscriber:
//! src/routes/subscriptions.rs
// [...]
pub async fn insert_subscriber(pool: &PgPool, new_subscriber: &NewSubscriber) -> Result<(), sqlx::Error> {
sqlx::query!(/*[...]*/)
.execute(pool)
.await
.inspect_err(|e| {
tracing::error!("Failed to execute query: {:?}", e);
})?;
Ok(())
}
您是否注意到了 Ok(()) 之前的 ? ?
它是问号操作符 ?。
? 在 Rust 1.13 中引入 - 它是语法糖。
当你使用易错函数并希望 “冒泡” 失败 (例如,类似于重新抛出已捕获的异常) 时, 它可以减少视觉噪音。
此代码块中的 ?
insert_subscriber(&pool, &new_subscriber)
.await
.map_err(|_| HttpResponse::InternalServerError().finish())?;
等于如下代码块中控制流
if let Err(error) = insert_subscriber(&pool, &new_subscriber)
.await
.map_err(|_| HttpResponse::InternalServerError().finish())
{
return Err(error);
}
它允许我们在出现故障时使用单个字符(而不是多行代码块)提前返回。
鉴于 ? 会使用 Err 变量触发提前返回, 因此它只能在返回 Result 的函数中使用。subscribe (暂时) 不符合条件。
400 Bad Request
现在让我们处理 SubscriberName::parse 返回的错误:
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
let name = match SubscriberName::parse(form.0.name) {
Ok(name) => name,
Err(_) => return HttpResponse::BadRequest().finish(),
};
let new_subscriber = NewSubscriber {
email: form.0.email,
name,
};
match insert_subscriber(&pool, &new_subscriber).await {
Ok(_) => HttpResponse::Ok().finish(),
Err(_) => HttpResponse::InternalServerError().finish(),
}
}
cargo test 尚未通过,但我们收到了不同的错误:
---- subscribe_returns_a_200_when_fields_are_present_but_invalid stdout ----
thread 'subscribe_returns_a_200_when_fields_are_present_but_invalid' panicked at
tests/health_check.rs:182:9:
assertion `left == right` failed: The API did not return a 400 OK when the paylo
ad was empty email.
left: 400
right: 200
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
subscribe_returns_a_200_when_fields_are_present_but_invalid
test result: FAILED. 3 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out;
finished in 0.20s
使用空名称的测试用例现在可以通过了,但当提供空的电子邮件地址时,我们无法返回 400 Bad Request。
这并不出乎意料——我们还没有实现任何类型的电子邮件验证!
电子邮件格式
我们直观地熟悉电子邮件地址的常见结构 - XXX@YYY.ZZZ - 但如果你想严谨起见,避免退回实际上有效的电子邮件地址,这个问题很快就会变得更加复杂。
我们如何确定一个电子邮件地址是否“有效”?
互联网工程任务组 (IETF) 发布了几个征求意见稿 (RFC),概述了电子邮件地址的预期结构 - tools.ietf.org/html/rfc6854、RFC 5322 和 RFC 2822。我们必须阅读这些文件,消化其中的内容,然后编写一个符合规范的 is_valid_email 函数。
除非你对理解电子邮件地址格式的细微差别有着浓厚的兴趣,否则我建议你先退一步:它相当混乱。混乱到甚至连 HTML 规范 都故意与我们刚刚链接的 RFC 不兼容。
我们最好的办法是寻找一个长期深入研究过这个问题的现有库, 以便为我们提供即插即用的解决方案。幸运的是, Rust 生态系统中至少有一个这样的库 —— validator crate!
基于属性的测试
我们可以使用另一种方法来测试我们的解析逻辑:与其验证特定输入集是否被正确解析,不如构建一个随机生成器来生成有效值,并检查我们的解析器是否不会拒绝这些值。
换句话说,我们验证我们的实现是否具有某个属性——“不会拒绝任何有效的电子邮件地址”。
这种方法通常被称为基于属性的测试。
例如,如果我们使用时间,我们可以反复采样三个随机整数:
- H,介于 0 到 23 之间(含)
- M,介于 0 到 59 之间(含)
- S,介于 0 到 59 之间(含)
并验证 H:M:S 始终能够被正确解析。
基于属性的测试显著扩大了我们验证的输入范围,从而增强了我们对代码正确性的信心,但它并不能证明我们的解析器是正确的——它并没有彻底探索输入空间(除了微小的输入空间)。
让我们看看我们的 SubscriberEmail 的属性测试是什么样的。
如何使用 fake 生成随机测试数据
首先,我们需要一个有效邮箱地址的随机生成器。 我们可以自己写一个,但这是一个引入 fake crate 的好机会。
fake 提供了原始数据类型(整数、浮点数、字符串)和高级对象(IP 地址、国家/地区代码等)的生成逻辑,特别是电子邮件!让我们将 fake 添加为我们项目的开发依赖项:
cargo add fake
让我们在新的测试中使用它
//! src/domain/subscriber_email.rs
#[cfg(test)]
mod tests {
// We are importing the `SafeEmail` faker!
// We also need the `Fake` trait to get access to the
// `.fake` method on `SafeEmail`
use claim::{assert_err, assert_ok};
use fake::{faker::internet::en::SafeEmail, Fake};
use crate::domain::SubscriberEmail;
// [...]
#[test]
fn valid_emails_are_parsed_successfully() {
let email = SafeEmail().fake();
assert_ok!(SubscriberEmail::parse(email));
}
}
每次运行测试套件时,SafeEmail().fake() 都会生成一个新的随机有效电子邮件地址,然后我们用它来测试我们的解析逻辑。
与硬编码的有效电子邮件地址相比,这已经是一个重大改进,但为了捕捉到边缘情况的问题,我们不得不多次运行测试套件。一个快速而粗略的解决方案是在测试中添加一个 for 循环,但同样,我们可以借此机会深入研究并探索一个围绕基于属性的测试而设计的测试crate。
quickcheck Vs proptest
Rust 生态系统中有两种主流的基于属性的测试方案: quickcheck 和 proptest。 它们的领域有所重叠,但各自在各自的领域中都独树一帜——请查看它们的 README 文件,了解所有细节。
对于我们的项目,我们将使用 quickcheck ——它入门相当简单,而且不使用太多宏,从而带来愉悦的 IDE 体验。
quickcheck 入门
让我们看一下其中一个例子来了解它的工作原理:
/// This function we want to test
fn reverse<T: Clone>(xs: &[T]) -> Vec<T> {
let mut rev = vec![];
for x in xs.iter() {
rev.insert(0, x.clone());
}
rev
}
#[cfg(test)]
mod tests {
#[quickcheck_macros::quickcheck]
fn prop(xs: Vec<u32>) -> bool {
/// A property that is always true, regardless
/// of the vector we are applying the function to:
/// reversing it twice should return the original input.
xs == reverse(&reverse(&xs))
}
}
quickcheck 在一个可配置迭代次数(默认为 100)的循环中调用 prop: 每次迭代时,它会生成一个新的 Vec<u32> 并检查 prop 是否返回 true。
如果 prop 返回 false,它会尝试将生成的输入压缩为尽可能小的失败样本(最短的失败向量),以帮助我们调试哪里出了问题。
在我们的例子中,我们希望实现如下代码:
#[quickcheck_macros::quickcheck]
fn valid_emails_are_parsed_successfully(valid_email: String) -> bool {
SubscriberEmail::parse(valid_email).is_ok()
}
不幸的是,如果我们要求输入字符串类型,我们将会得到各种各样的垃圾数据,从而导致验证失败。
我们如何定制生成程序?
实现 Arbitrary Trait
让我们回到前面的例子——quickcheck 是如何知道生成 Vec<u32> 的?一切都建立在 quickcheck 的 Arbitrary trait之上:
pub trait Arbitrary: Clone + 'static {
// Required method
fn arbitrary(g: &mut Gen) -> Self;
// Provided method
fn shrink(&self) -> Box<dyn Iterator<Item = Self>> { ... }
}
我们有两个方法:
- arbitrary:给定一个随机源 (g),返回该类型的一个实例;
- shrink:返回一个逐渐“缩小”的该类型实例序列,以帮助 quickcheck
找到最小的可能失败情况。
Vec<u32> 实现了 Arbitrary 接口,因此 quickcheck 知道如何生成随机的 u32 向量。
我们需要创建自己的类型,我们称之为 ValidEmailFixture,并为其实现 Arbitrary 接口。
如果你查看 Arbitrary 的特征定义,你会注意到 shrinking 是可选的:有一个默认的实现(使用 empty_shrinker),它会导致 quickcheck 输出遇到的第一个失败,而不会尝试使其变得更小或更优。因此,我们只需要为我们的 ValidEmailFixture 提供一个 Arbitrary::arbitrary 的实现。
让我们将 quickcheck 和 quickcheck-macros 都添加为开发依赖项:
cargo add quickcheck quickcheck-macros --dev
然后
//! src/domain/subscriber_email.rs
// [...]
#[cfg(test)]
mod tests {
use claim::assert_err;
use fake::locales::{self, Data};
use crate::domain::SubscriberEmail;
// Both `Clone` and `Debug are required by `quickcheck`
#[derive(Debug, Clone)]
struct ValidEmailFixture(pub String);
impl quickcheck::Arbitrary for ValidEmailFixture {
fn arbitrary(g: &mut quickcheck::Gen) -> Self {
let username = g
.choose(locales::EN::NAME_FIRST_NAME)
.unwrap()
.to_lowercase();
let domain = g.choose(&["com", "net", "org"]).unwrap();
let email = format!("{username}@example.{domain}");
Self(email)
}
}
// ...
}
这是一个令人惊叹的例子,它展现了通过在 Rust 生态系统中共享关键特性而获得的互操作性。
我们如何让 fake 和 quickcheck 完美地协同工作?
在 Arbitrary::arbitrary 中,我们以 g 作为输入,它是一个 G 类型的参数。
G 受特性边界 G: quickcheck::Gen 的约束,因此它必须实现 quickcheck 中的 Gen 特性,
其中 Gen 代表“生成器”。
注: 等等...你注意到了吗? 在新的 quickcheck crate 中 Gen不再是trait, 而是一个 struct, 前面这一段代码是我自己(译者)的解决方案, 并非原作, 解决方案来自 这个 GitHub issue
两个 crate 的维护者可能彼此了解,也可能不了解,但 rand-core 中一套社区认可的 trait 为我们提供了轻松的互操作性。太棒了!
现在您可以运行 cargo test domain 了——结果应该会是绿色,这再次证明了我们的邮箱验证机制 并没有过于死板。
如果您想查看生成的随机输入,请在测试中添加 dbg!(&valid_email.0);
语句,然后运行 cargo test valid_emails -- --nocapture ——数十个有效的邮箱地址
应该会弹出到您的终端中!
Payload 验证
如果您运行 cargo test,而不将运行的测试集限制在域内,您将看到我们的集成测试包含无效数据,仍然是红色的。
---- subscribe_returns_a_200_when_fields_are_present_but_invalid stdout ----
thread 'subscribe_returns_a_200_when_fields_are_present_but_invalid' panicked at
tests/health_check.rs:182:9:
assertion `left == right` failed: The API did not return a 400 OK when the paylo
ad was empty email.
left: 400
right: 200
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
subscribe_returns_a_200_when_fields_are_present_but_invalid
让我们将我们出色的 SubscriberEmail 集成到应用程序中,以便从我们的 /subscriptions 端点中的验证中受益。
我们需要从 NewSubscriber 开始:
//! src/domain/new_subscriber.rs
use crate::domain::{SubscriberEmail, SubscriberName};
pub struct NewSubscriber {
// We are not using `String` anymore!
pub email: SubscriberEmail,
pub name: SubscriberName,
}
如果你现在尝试编译这个项目,那可就糟了。
我们先从 cargo check 报告的第一个错误开始:
--> src/routes/subscriptions.rs:28:16
|
28 | email: form.0.email,
| ^^^^^^^^^^^^ expected `SubscriberEmail`, found `String`
|
它指的是我们的请求处理程序中的一行, subscribe:
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
let name = match SubscriberName::parse(form.0.name) {
Ok(name) => name,
Err(_) => return HttpResponse::BadRequest().finish(),
};
let new_subscriber = NewSubscriber {
email: form.0.email,
name,
};
match insert_subscriber(&pool, &new_subscriber).await {
Ok(_) => HttpResponse::Ok().finish(),
Err(_) => HttpResponse::InternalServerError().finish(),
}
}
我们需要模仿我们已经对 name 字段所做的事情: 首先我们解析 form.0.email, 然后我们将结果(如果成功)赋值给 NewSubscriber.email 。
//! src/routes/subscriptions.rs
// We added `SubscriberEmail`!
use crate::domain::{NewSubscriber, SubscriberEmail, SubscriberName};
// [...]
pub async fn subscribe(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
let name = match SubscriberName::parse(form.0.name) {
Ok(name) => name,
Err(_) => return HttpResponse::BadRequest().finish(),
};
let email = match SubscriberEmail::parse(form.0.email) {
Ok(email) => email,
Err(_) => return HttpResponse::BadRequest().finish(),
};
let new_subscriber = NewSubscriber {
email,
name,
};
// [...]
}
是时候处理第二个错误了
--> src/routes/subscriptions.rs:53:9
|
53 | new_subscriber.email,
| ^^^^^^^^^^^^^^
| |
| expected `&str`, found `SubscriberEmail`
| expected due to the type of this binding
error[E0277]: the trait bound `SubscriberEmail: sqlx::Encode<'_, Postgres>` is not satisfied
这是在我们的 insert_subscriber 函数中,我们执行 SQL INSERT 查询来存储新订阅者的详细信息:
//! src/routes/subscriptions.rs
// [...]
pub async fn insert_subscriber(pool: &PgPool, new_subscriber: &NewSubscriber) -> Result<(), sqlx::Error> {
sqlx::query!(
r#"
INSERT INTO subscriptions (id, email, name, subscribed_at)
VALUES ($1, $2, $3, $4)
"#,
Uuid::new_v4(),
new_subscriber.email,
new_subscriber.name.as_ref(),
Utc::now()
)
.execute(pool)
.await
.inspect_err(|e| {
tracing::error!("Failed to execute query: {:?}", e);
})?;
Ok(())
}
解决方案就在下面这行——我们只需要使用 AsRef<str> 的实现, 借用 SubscriberEmail 的内部字段作为字符串切片。
#[tracing::instrument(
name = "Saving new subscriber details in the database",
skip(new_subscriber, pool)
)]
pub async fn insert_subscriber(pool: &PgPool, new_subscriber: &NewSubscriber) -> Result<(), sqlx::Error> {
sqlx::query!(
r#"[...]"#,
Uuid::new_v4(),
new_subscriber.email.as_ref(),
new_subscriber.name.as_ref(),
Utc::now()
)
.execute(pool)
.await
.inspect_err(|e| {
tracing::error!("Failed to execute query: {:?}", e);
})?;
Ok(())
}
就这样了——现在可以编译了!
我们的集成测试怎么样?
cargo test
running 4 tests
test subscribe_returns_a_400_when_data_is_missing ... ok
test health_check_works ... ok
test subscribe_returns_a_200_when_fields_are_present_but_invalid ... ok
test subscribe_returns_a_200_for_valid_form_data ... ok
全部通过! 我们做到了!
使用 TryFrom 重构
在继续之前,我们先花几段时间来重构一下刚刚写的代码。我指的是我们的请求处理程序 subscribe:
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
let name = match SubscriberName::parse(form.0.name) {
Ok(name) => name,
Err(_) => return HttpResponse::BadRequest().finish(),
};
let email = match SubscriberEmail::parse(form.0.email) {
Ok(email) => email,
Err(_) => return HttpResponse::BadRequest().finish(),
};
let new_subscriber = NewSubscriber {
email,
name,
};
match insert_subscriber(&pool, &new_subscriber).await {
Ok(_) => HttpResponse::Ok().finish(),
Err(_) => HttpResponse::InternalServerError().finish(),
}
}
我们可以在 parse_subscriber 函数中提取前两个语句:
pub fn parse_subscriber(form: FormData) -> Result<NewSubscriber, String> {
let name = SubscriberName::parse(form.name)?;
let email = SubscriberEmail::parse(form.email)?;
Ok(NewSubscriber { email, name })
}
#[tracing::instrument(/*[...]*/)]
pub async fn subscribe(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
let new_subscriber = match parse_subscriber(form.into_inner()) {
Ok(subscriber) => subscriber,
Err(_) => return HttpResponse::BadRequest().finish(),
};
// [...]
}
重构使我们更加清晰地分离了关注点:
- parse_subscriber 负责将我们的数据格式(从 HTML 表单收集的 URL 解码数据)转换为我们的领域模型(NewSubscriber)
- subscribe 仍然负责生成对传入 HTTP 请求的 HTTP 响应。
Rust 标准库在其 std::convert 子模块中提供了一些处理转换的特性。AsRef 就是从这里来的!
那里有没有什么特性可以捕捉到我们试图用 parse_subscriber 做的事情?
AsRef 不太适合我们这里要处理的问题: 两种类型之间容易出错的转换, 它会消耗输入值。
我们需要看看 TryFrom:
pub trait TryFrom<T>: Sized {
type Error;
// Required method
fn try_from(value: T) -> Result<Self, Self::Error>;
}
将 T 替换为 FormData, 将 Self 替换为 NewSubscriber, 将 Self::Error 替换为 String ——这就是 parse_subscriber 函数的签名!
我们来试试看:
//! src/routes/subscriptions.rs
// [...]
impl TryFrom<FormData> for NewSubscriber {
type Error = String;
fn try_from(value: FormData) -> Result<Self, Self::Error> {
let name = SubscriberName::parse(value.name)?;
let email = SubscriberEmail::parse(value.email)?;
Ok(NewSubscriber { email, name })
}
}
#[tracing::instrument(/*[...]*/)]
pub async fn subscribe(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
let new_subscriber = match form.into_inner().try_into() {
Ok(subscriber) => subscriber,
Err(_) => return HttpResponse::BadRequest().finish(),
};
match insert_subscriber(&pool, &new_subscriber).await {
Ok(_) => HttpResponse::Ok().finish(),
Err(_) => HttpResponse::InternalServerError().finish(),
}
}
}
我们实现了 TryFrom,但却调用了 .try_into? 这到底是怎么回事?
标准库中还有另一个转换 trait,叫做 TryInto:
pub trait TryInto<T>: Sized {
type Error;
// Required method
fn try_into(self) -> Result<T, Self::Error>;
}
它的签名与 TryFrom 的签名相同——转换方向相反! 如果您提供 TryFrom 实现,您的类型将自动获得相应的 TryInto 实现,无需额外工作。
try_into 将 self 作为第一个参数,这使得我们可以执行 form.0.try_into() 而不是 NewSubscriber::try_from(form.0) ——如果您愿意,这完全取决于您的个人喜好。
总的来说,实现 TryFrom/TryInto 能给我们带来什么好处?
没什么特别的,也没有什么新功能——我们“只是”让我们的意图更清晰。
我们明确地说明了“这是一个类型转换!”。
这为什么重要?因为它能帮助别人!
当另一位熟悉 Rust 的开发人员进入我们的代码库时,他们会立即发现转换模式,因为我们使用的是他们已经熟悉的特性。
小结
验证 POST /subscriptions 有效负载中的电子邮件地址是否符合预期格式是件好事,但这还不够。
我们现在有一封语法上有效的电子邮件,但我们仍然不确定它是否存在: 真的有人使用这个电子邮件地址吗?它能被访问到吗? 我们一无所知,而且只有一种方法可以找到答案:发送一封真实的电子邮件。
确认电子邮件(以及如何编写 HTTP 客户端!)将是下一章的主题。
拒绝无效订阅者 第二部分
确认邮件
在上一章中,我们介绍了新订阅者电子邮件地址的验证——它们 必须符合电子邮件格式。
现在,我们拥有的电子邮件地址在语法上是有效的,但我们仍然不确定它们是否存在:
真的有人使用这些电子邮件地址吗?他们能联系到吗?
我们对此一无所知,只有一种方法可以找到答案:发送一封真正的确认电子邮件。
订阅者同意
你的蜘蛛感应现在应该开始运转了——在订阅用户生命周期的这个阶段,我们真的需要知道吗?难道我们不能等到下一期简报发布才能知道他们是否收到了我们的邮件吗?
如果我们唯一关心的是进行彻底的验证,我同意:我们应该等到下一期发布,而不是给我们的 POST /订阅端点增加更多复杂性。
不过,还有一件事我们关心,而且我们无法推迟:订阅者的同意。
电子邮件地址不是密码——如果你上网时间足够长,你的电子邮件地址很可能并不难获得。
某些类型的电子邮件地址(例如专业电子邮件地址)是完全公开的。
这为滥用提供了可能性。
恶意用户可能会开始订阅互联网上各种简报的电子邮件地址,从而让受害者的收件箱充斥着垃圾邮件。
相反,不正当的新闻通讯所有者可能会开始从网络上抓取电子邮件地址,并将其添加到其新闻通讯电子邮件列表中。
这就是为什么 POST /subscriptions 请求不足以表示“此人想接收我的新闻通讯内容!”。
例如,如果您与欧洲公民打交道,则法律要求获得用户的明确同意。
这就是为什么发送确认电子邮件已成为一种常见做法:在新闻通讯 HTML 表单中输入您的详细信息后,您将在收件箱中收到一封电子邮件,要求您确认是否确实想要订阅该新闻通讯。
这对我们来说非常有效——我们保护用户免受滥用,并在尝试向他们发送新闻通讯之前确认他们提供的电子邮件地址确实存在。
确认用户流程
让我们从用户的角度来看一下我们的确认流程。 他们会收到一封包含确认链接的电子邮件。 点击链接后,系统会自动将用户重定向到成功页面(“您现在订阅了我们的新闻通讯!太棒了!”)。从此以后,他们会在收件箱中收到所有新闻通讯。 后端是如何工作的? 我们会尽量简化流程——我们的版本不会在确认后执行重定向, 我们只会向浏览器返回 200 OK 状态码。 每次用户想要订阅我们的新闻通讯时,他们都会触发一个 POST /subscriptions 请求。 我们的请求处理程序将:
- 将用户的详细信息添加到我们数据库的
subscriptions表中,状态为pending_confirmation - 生成一个(唯一的)
subscription_token - 将
subscription_token存储在我们数据库的subscription_tokens表中,并根据用户的 ID 进行存储; - 向新订阅者发送一封电子邮件,其中包含结构为
https://<our-api-domain>/subscriptions/confirm的链接 - 返回 200 OK。
一旦用户点击链接,浏览器标签页就会打开,并向我们的 GET /subscriptions/confirm 端点发送 GET 请求。我们的请求处理程序将:
- 从查询参数中检索 subscription_token;
- 从 subscription_tokens 表中检索与 subscription_token 关联的订阅者 ID;
- 在 subscriptions 表中将订阅者状态从 pending_confirmation 更新为 active;
- 返回 200 OK。
还有其他一些可能的设计(例如,使用 JWT 代替唯一令牌), 并且我们还有一些特殊情况需要处理(例如,如果他们点击链接两次会发生什么?如果他们尝试订阅两次会发生什么?)——随着实施工作的进展,我们将在最合适的时间讨论这些问题。
实施策略
这里有很多工作要做,所以我们将工作分为三个概念块:
- 编写一个模块来发送电子邮件
- 调整现有
POST /subscriptions请求处理程序的逻辑以匹配新规范 - 从头编写
GET /subscriptions/confirm请求处理程序
让我们开始吧!
EmailClient - 我们的的电子邮件传递组件
怎么发一封邮件
你究竟是如何发送电子邮件的?
它是如何工作的?
你必须了解一下 SMTP。
它自互联网早期就已存在——第一个 RFC 可以追溯到 1982 年。
SMTP 之于电子邮件的作用就如同 HTTP 之于网页:它是一个应用级协议,确保不同的电子邮件服务器和客户端实现能够相互理解并交换消息。
现在,让我们明确一点——我们不会构建自己的私人电子邮件服务器,这会耗费太长时间,
而且我们不会从中获益太多。我们将利用第三方服务。
如今的电子邮件递送服务需要什么?我们需要通过 SMTP 来与它们沟通吗?
不一定。
SMTP 是一种专用协议:除非你以前使用过电子邮件,否则你不太可能有直接使用它的经验。学习新的协议需要时间,而且过程中难免会犯错——这就是为什么大多数提供商会提供两个接口: SMTP 和 REST API。
如果您熟悉电子邮件协议,或者需要一些非常规的配置,那么 建议您使用 SMTP 接口。否则,大多数开发人员使用 REST API 会更快(也更可靠)地上手。
您可能已经猜到了,这也是我们的目标——我们将编写一个 REST 客户端。
选择一个电子邮件 API
市面上的电子邮件 API 提供商不胜枚举,你很可能知道一些主流提供商的名字——AWS SES、SendGrid、MailGun、Mailchimp 和 Postmark。
我正在寻找一个足够简单的 API(例如,发送一封电子邮件有多简单?)、一个流畅的入门流程和一个免费计划,无需输入信用卡信息即可测试服务。
就这样,我选择了 Postmark。
注: 译者认为使用 SaaS 平台来支持自己的服务不是最佳实践, 他自己会用自建的 SMTP 服务来发邮件, crates.io 上有很多 crate 可以帮助我们解决 SMTP 问题
要完成接下来的部分,您必须注册 Postmark, 并在登录其门户后,授权单个发件人电子邮件。
完成后,我们就可以继续了!
免责声明:Postmark 没有付费让我在这里推广他们的服务。
电子邮件客户端接口
开发一个新功能通常有两种方法: 一种是自下而上,从实现细节开始,慢慢地向上推进;另一种是自上而下,先设计接口,然后再(在一定程度上)确定实现的工作原理。
在这种情况下,我们将选择第二种方法。
我们希望我们的电子邮件客户端拥有什么样的接口?
我们希望有某种 send_email 方法。目前我们只需要一次发送一封电子邮件——当我们开始处理新闻通讯问题时,我们会处理批量发送电子邮件的复杂性。
send_email 应该接受哪些参数?
我们肯定需要收件人的电子邮件地址、邮件主题和邮件内容。我们会要求提供 HTML 和纯文本版本的电子邮件内容——有些邮件客户端无法渲染 HTML,有些用户也明确禁用了 HTML 邮件。为了安全起见,我们发送两个版本。
那么发件人的电子邮件地址呢?
我们假设客户端实例发送的所有邮件都来自同一个地址——
因此我们不需要将其作为 send_email 的参数,它会作为客户端本身构造函数的参数之一。
我们还希望 send_email 是一个异步函数,因为我们将执行 I/O 操作来与远程服务器通信。
将所有内容组合在一起,我们得到的内容大致如下:
//! src/email_client.rs
use crate::domain::SubscriberEmail;
pub struct EmailClient {
sender: SubscriberEmail,
}
impl EmailClient {
pub async fn send_email(
&self,
recipient: SubscriberEmail,
subject: &str,
html_content: &str,
text_content: &str,
) -> Result<(), String> {
todo!()
}
}
//! src/lib.rs
// New entry!
pub mod email_client;
// [...]
还有一个未解决的问题——返回类型。我们草拟了一个 Result<(), String> 类,这相当于表达了“我稍后再考虑错误处理”的意思。
还有很多工作要做,但这只是一个开始——我们说过要从接口开始,而不是一次性搞定!
怎么使用 reqwest 写 REST 客户端
要与 REST API 通信,我们需要一个 HTTP 客户端。
Rust 生态系统中有一些不同的选择:同步 vs 异步、纯 Rust vs 绑定到底层原生库、与 tokio 或 async-std 绑定、固定 vs 高度可定制等等。
我们将选择 crates.io 上最受欢迎的选项:reqwest。 关于 reqwest,您有什么想说的吗?
- 它已经过广泛的测试(下载量约 850 万次)
- 它提供了一个主要的异步接口,并可以通过阻止功能标志启用同步接口
- 它依赖于 tokio 作为其异步执行器,与我们已经在使用的 actix-web 兼容
- 如果您选择使用 rustls 来支持 TLS 实现(使用 rustls-tls 功能标志而不是 default-tls),它不依赖于任何系统库,因此具有极高的可移植性。
如果您仔细观察,就会发现我们已经在使用 reqwest!
它是我们在集成测试中用来向 API 发起请求的 HTTP 客户端。让我们将它从开发依赖项提升为运行时依赖项:
#! Cargo.toml
[dependencies]
# [...]
# We need the `json` feature flag to serialize/deserialize JSON paylaods
reqwest = { version = "0.12.23", default-features = false, features = ["json", "rustls-tls"] }
[dev-dependencies]
# Remove `reqwest`'s entry from this table
reqwest::Client
使用 reqwest 时,主要处理的类型是 reqwest::Client - 它公开了我们向 REST API 执行请求所需的所有方法。
我们可以通过调用 Client::new 获取一个新的客户端实例,或者,如果需要调整默认配置,也可以使用 Client::builder。
我们暂时使用 Client::new。
让我们向 EmailClient 添加两个字段:
http_client, 用于存储Client实例base_url, 用于存储我们将要发送请求的 API 的 URL
//! src/email_client.rs
use reqwest::Client;
use crate::domain::SubscriberEmail;
pub struct EmailClient {
sender: SubscriberEmail,
base_url: String,
http_client: Client,
}
impl EmailClient {
pub fn new(base_url: String, sender: SubscriberEmail) -> Self {
Self {
http_client: Client::new(),
base_url,
sender,
}
}
// [...]
}
连接池
在对远程服务器上托管的 API 执行 HTTP 请求之前,我们需要建立连接。
事实证明,连接是一项相当昂贵的操作,如果使用 HTTPS 连接则更是如此:每次需要发起请求时都创建一个全新的连接会影响应用程序的性能,并可能导致所谓的“负载下套接字耗尽”问题。
为了缓解这个问题,大多数 HTTP 客户端都提供了连接池:在对远程服务器的第一个请求完成后,它们会保持连接打开(一段时间),并在我们需要向同一服务器发起另一个请求时重新使用它,从而避免了重新建立连接。
reqwest 也不例外——每次创建 Client 实例时,reqwest 都会在底层初始化一个连接池。
为了利用这个连接池,我们需要在多个请求中重用同一个 Client。
还需要指出的是, Client::clone 不会创建新的连接池——我们只是克隆一个指向底层连接池的指针。
怎么在 actix-web 中复用相同的 reqwest::Client
为了在 actix-web 中的多个请求中重复使用同一个 HTTP 客户端,我们需要在应用上下文中存储它的副本。 ——这样我们就可以使用提取器(例如 actix_web::web::Data)在请求处理程序中检索对客户端的引用。
如何实现呢?让我们看一下构建 HttpServer 的代码:
//! src/startup.rs
// [...]
pub fn run(
listener: TcpListener,
db_pool: PgPool,
) -> Result<Server, std::io::Error> {
let db_pool = web::Data::new(db_pool);
let server = HttpServer::new(move || {
App::new()
// Middlewares are added using the `wrap` method on `App`
.wrap(TracingLogger::default())
.route("/health_check", web::get().to(health_check))
.route("/subscriptions", web::post().to(subscribe))
.app_data(db_pool.clone())
})
.listen(listener)?
.run();
Ok(server)
}
我们有两个选择:
- 为
EmailClient派生Clonetrait,构建一次它的实例,然后在每次需要构建应用时将一个克隆传递给 app_data:
//! src/email_client.rs
#[derive(Debug)]
pub struct EmailClient {
sender: SubscriberEmail,
base_url: String,
http_client: Client,
}
// [...]
//! src/startup.rs
use crate::email_client::EmailClient;
// [...]
pub fn run(
listener: TcpListener,
db_pool: PgPool,
email_client: EmailClient,
) -> Result<Server, std::io::Error> {
let db_pool = web::Data::new(db_pool);
let server = HttpServer::new(move || {
App::new()
// Middlewares are added using the `wrap` method on `App`
.wrap(TracingLogger::default())
.route("/health_check", web::get().to(health_check))
.route("/subscriptions", web::post().to(subscribe))
.app_data(db_pool.clone())
.app_data(email_client.clone())
})
.listen(listener)?
.run();
Ok(server)
}
- 将
EmailClient包装在actix_web::web::Data(一个Arc指针) 中, 并在每次需要构建应用程序时将指针传递给 app_data——就像我们在 PgPool 中所做的那样:
//! src/startup.rs
use crate::email_client::EmailClient;
pub fn run(
listener: TcpListener,
db_pool: PgPool,
email_client: EmailClient,
) -> Result<Server, std::io::Error> {
let db_pool = web::Data::new(db_pool);
let email_client = web::Data::new(email_client);
let server = HttpServer::new(move || {
App::new()
// Middlewares are added using the `wrap` method on `App`
.wrap(TracingLogger::default())
.route("/health_check", web::get().to(health_check))
.route("/subscriptions", web::post().to(subscribe))
.app_data(db_pool.clone())
.app_data(email_client.clone())
})
.listen(listener)?
.run();
Ok(server)
}
哪种方法最好?
如果 EmailClient 只是 Client 实例的包装器,那么第一种方案会更可取——我们避免使用 Arc 两次包装连接池。
但事实并非如此: EmailClient 附加了两个数据字段 (base_url 和 sender)。
第一种实现会在每次创建 App 实例时分配新的内存来保存这些数据的副本,而第二种实现则会在所有 App 实例之间共享这些数据。
这就是我们使用第二种策略的原因。
但请注意: 我们为每个线程创建一个 App 实例——从全局来看,字符串分配 (或指针克隆) 的成本可以忽略不计。
我们在这里将这个决策过程作为一个练习,以了解其中的利弊——将来您可能需要做出类似的决策,届时两种方案的成本可能会有显著差异。
配置我们的 EmailClient
如果你运行 cargo check 你将会得到如下错误
error[E0061]: this function takes 3 arguments but 2 arguments were supplied
--> src/main.rs:24:5
|
24 | run(listener, connection_pool)?.await
| ^^^--------------------------- argument #3 of type `EmailClient` is mis
sing
|
让我们修复它!
main 函数现在有什么?
//! src/main.rs
// [...]
#[tokio::main]
async fn main() -> std::io::Result<()> {
// [...]
let configuration = get_configuration().expect("Failed to read config");
let connection_pool = PgPoolOptions::new()
.acquire_timeout(std::time::Duration::from_secs(2))
.connect_lazy_with(configuration.database.with_db());
let address = format!(
"{}:{}",
configuration.application.host, configuration.application.port
);
let listener = TcpListener::bind(address)?;
run(listener, connection_pool)?.await
}
我们正在使用通过 get_configuration 获取的配置中指定的值来构建应用程序的依赖项。
要构建 EmailClient 实例,我们需要获取要向其发送请求的 API 的基本 URL 以及发件人的电子邮件地址 - 让我们将它们添加到 Settings 结构体中:
//! src/configuration.rs
// [...]
use crate::domain::SubscriberEmail;
#[derive(serde::Deserialize)]
pub struct Settings {
pub database: DatabaseSettings,
pub application: ApplicationSettings,
pub email_client: EmailClientSettings,
}
#[derive(serde::Deserialize)]
pub struct EmailClientSettings {
pub base_url: String,
pub sender_email: String,
}
impl EmailClientSettings {
pub fn sender(&self) -> Result<SubscriberEmail, String> {
SubscriberEmail::parse(self.sender_email.clone())
}
}
然后我们需要在配置文件中为它们设置值:
#! configuration/base.yaml
application:
# [...]
database:
# [...]
email_client:
base_url: "localhost"
sender_email: "test@gmail.com"
#! configuration/production.yaml
application:
host: 0.0.0.0
database:
require_ssl: true
email_client:
# Value retrieved from Postmark's API documentation
base_url: "https://api.postmarkapp.com"
sender_email: "something@gmail.com"
我们现在可以在 main 中构建一个 EmailClient 实例并将其传递给 run 函数:
//! src/main.rs
// [...]
use zero2prod::email_client::EmailClient;
#[tokio::main]
async fn main() -> std::io::Result<()> {
let subscriber = get_subscriber("zero2prod", "info", std::io::stdout);
init_subscriber(subscriber);
let configuration = get_configuration().expect("Failed to read config");
let connection_pool = PgPoolOptions::new()
.acquire_timeout(std::time::Duration::from_secs(2))
.connect_lazy_with(configuration.database.with_db());
// Build an `EmailClient` using `configuration`
let sender_email = configuration.email_client.sender()
.expect("Invalid sender email address");
let email_client = EmailClient::new(
configuration.email_client.base_url,
sender_email,
);
let address = format!(
"{}:{}",
configuration.application.host, configuration.application.port
);
let listener = TcpListener::bind(address)?;
run(listener, connection_pool, email_client)?.await
}
cargo check 现在应该可以通过了,尽管有一些关于未使用变量的警告——我们很快就会处理它们。
我们的测试怎么样?
cargo check --all-targets 返回的错误与我们之前使用 cargo check 时看到的类似:
error[E0061]: this function takes 3 arguments but 2 arguments were supplied
--> tests/health_check.rs:48:18
|
48 | ...rver = zero2prod::run(listener, connection_pool.clone()).expect("Fail...
| ^^^^^^^^^^^^^^----------------------------------- argument #3 of
type `EmailClient` is missing
|
你说得对——这是代码重复的症状。我们会重构集成测试的初始化逻辑,但目前还不行。
让我们快速打个补丁,让它能编译通过:
//! tests/health_check.rs
// [...]
use zero2prod::email_client::EmailClient;
async fn spawn_app() -> TestApp {
// [...]
// Build a new email client
let sender_email = configuration.email_client.sender()
.expect("Invalid sender email address.");
let email_client = EmailClient::new(
configuration.email_client.base_url,
sender_email
);
let server = zero2prod::run(listener, connection_pool.clone(), email_client)
.expect("Failed to bind address");
let _ = tokio::spawn(server);
TestApp {
address,
db_pool: connection_pool,
}
}
cargo test 现在应该可以通过了
怎么测试一个 REST 客户端
我们已经完成了大部分设置步骤:我们绘制了 EmailClient 的接口,并使用新的配置类型 EmailClientSettings 将其与应用程序连接起来。
为了坚持我们的测试驱动开发方法,现在是时候编写测试了!
我们可以从集成测试开始: 修改 POST /订阅的测试,以确保端点符合我们的新要求。
不过,要让它们通过测试需要很长时间:除了发送电子邮件之外,我们还需要添加逻辑来生成并存储唯一的令牌。 让我们从小处着手:我们将单独测试 EmailClient 组件。
这将增强我们对它在作为一个单元进行测试时是否符合预期的信心,从而减少将其集成到更大的确认电子邮件流程中可能遇到的问题。
这也让我们有机会看看最终的界面是否符合人体工程学且易于测试。
我们实际上应该测试什么?
EmailClient::send_email 的主要目的是执行 HTTP 调用:: 我们如何知道
它是否发生了?我们如何检查正文和标头是否按预期填充?
我们需要拦截该 HTTP 请求——是时候启动一个模拟服务器了!
使用 wiremock 进行 HTTP 模拟
让我们在 src/email_client.rs 的底部添加一个新的测试模块,其中包含一个新测试的框架:
//! src/email_client.rs
// [...]
#[cfg(test)]
mod tests {
#[tokio::test]
async fn send_email_fires_a_request_to_base_url() {
todo!()
}
}
这不会立即编译 - 我们需要在 Cargo.toml 中向 tokio 添加两个 feature flags:
[dev-dependencies]
# [...]
tokio = { version = "1", features = ["rt", "macros"] }
我们对 Postmark 的了解还不够,无法断言我们应该在传出的 HTTP 请求中看到什么。
不过,正如测试名称所示,可以合理地预期会向服务器发送一个请求,地址是 EmailClient::base_url!
让我们将 wiremock 添加到我们的开发依赖项中:
cargo add wiremock --dev
使用 wiremock, 我们可以将 send_email_fires_a_request_to_base_url 写成如下形式:
//! src/email_client.rs
// [...]
#[cfg(test)]
mod tests {
use fake::{faker::{internet::en::SafeEmail, lorem::en::Sentence}, Fake};
use wiremock::{matchers::any, Mock, MockServer, ResponseTemplate};
use crate::{domain::SubscriberEmail, email_client::EmailClient};
#[tokio::test]
async fn send_email_fires_a_request_to_base_url() {
// Arrange
let mock_server = MockServer::start().await;
let sender = SubscriberEmail::parse(SafeEmail().fake()).unwrap();
let email_client = EmailClient::new(mock_server.uri(), sender);
Mock::given(any())
.respond_with(ResponseTemplate::new(200))
.expect(1)
.mount(&mock_server)
.await;
let subscriber_email = SubscriberEmail::parse(SafeEmail().fake()).unwrap();
let subject: String = Sentence(1..2).fake();
let content: String = Sentence(1..10).fake();
// Act
let _ = email_client
.send_email(subscriber_email, &subject, &content, &content)
.await;
// Assert
}
}
让我们一步一步分析一下正在发生的事情。
let mock_server = MockServer::start().await;
wiremock::MockServer
wiremock::MockServer 是一个功能齐全的 HTTP 服务器。
MockServer::start 会向操作系统请求一个随机可用端口,并在后台线程中启动服务器,准备监听传入的请求。
如何将电子邮件客户端指向模拟服务器?我们可以使用 MockServer::uri 方法获取模拟服务器的地址;然后将其作为 base_url 传递给 EmailClient::new: let email_client = EmailClient::new(mock_server.uri(), sender);
wiremock::Mock
开箱即用,wiremock::MockServer 会向所有传入请求返回 404 Not Found。
我们可以通过挂载 Mock 来指示模拟服务器执行不同的操作。
Mock::given(any())
.respond_with(ResponseTemplate::new(200))
.expect(1)
.mount(&mock_server)
.await;
当 wiremock::MockServer 收到请求时,它会遍历所有已挂载的模拟,检查请求是否符合它们的条件。
模拟的匹配条件使用 Mock::given 指定。
我们将 any() 传递给 Mock::Given,根据 wiremock 的文档,
匹配所有传入请求,无论其方法、路径、标头或正文如何。您可以使用它来验证请求是否已向服务器发出,而无需对其进行任何其他断言。
基本上,无论请求是什么,它总是匹配的——这正是我们想要的!
当传入的请求符合已挂载模拟的条件时,wiremock::MockServer 将按照 respond_with 中指定的内容返回响应。
我们传递了 ResponseTemplate::new(200) - 一个没有正文的 200 OK 响应。
wiremock::Mock 只有在挂载到 wiremock::Mockserver 后才会生效——这就是我们调用 Mock::mount 的原因。
测试的目的应该明确
然后我们实际调用了 EmailClient::send_email:
let subscriber_email = SubscriberEmail::parse(SafeEmail().fake()).unwrap();
let subject: String = Sentence(1..2).fake();
let content: String = Paragraph(1..10).fake();
// Act
let _ = email_client
.send_email(subscriber_email, &subject, &content, &content)
.await;
你会注意到,我们在这里严重依赖 fake: 我们为 send_email(以及上一节中的 sender)的所有输入生成随机数据。
我们本来可以直接硬编码一堆值,为什么我们要一路硬编码,把它们都变成随机的呢?
读者只需浏览一下测试代码,就应该能够轻松识别我们要测试的属性。
使用随机数据传达了一个特定的信息:不要关注这些输入,它们的值不会影响测试结果,这就是它们随机的原因!
相反,硬编码值应该总是让你犹豫:将 subscriber_email 设置为 marco@gmail.com 是否重要?如果我将其设置为其他值,测试应该通过吗?
在我们这样的测试中,答案显而易见。但在更复杂的设置中,答案通常并非如此。
模拟期望
测试的结尾看起来有点神秘:有一个 // Assert 注释……但后面没有断言。
让我们回到 Mock 设置那一行:
Mock::given(any())
.respond_with(ResponseTemplate::new(200))
.expect(1)
.mount(&mock_server)
.await;
.expect(1) 的作用是什么?
它为我们的模拟设置了一个期望: 我们告诉模拟服务器,在本次测试中,它应该接收恰好一个符合此模拟设置条件的请求。
我们也可以使用范围来设置期望——例如,expect(1..) 表示我们希望至少接收一个请求;expect(1..=3) 表示我们希望接收至少一个请求,但不超过三个请求,等等。
当 MockServer 超出范围时,会验证期望——确实,是在测试函数的末尾!
在关闭之前,MockServer 会迭代所有已挂载的模拟,并检查它们的期望是否已验证。如果验证步骤失败,则会触发 panic(并导致测试失败)。
让我们运行 cargo test:
---- email_client::tests::send_email_fires_a_request_to_base_url stdout ----
thread 'email_client::tests::send_email_fires_a_request_to_base_url' panicked at
src/email_client.rs:27:9:
not yet implemented
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
好的,我们甚至还没有结束测试,因为我们有一个占位符 todo!() 作为 send_e`mail 的主体。
让我们用一个虚拟的 Ok 来替换它:
//! src/email_client.rs
// [...]
impl EmailClient {
// [...]
pub async fn send_email(
&self,
recipient: SubscriberEmail,
subject: &str,
html_content: &str,
text_content: &str,
) -> Result<(), String> {
// No matter the input
Ok(())
}
}
如果我们再次运行 cargo test, 我们将看到 wiremock 的运行情况:
---- email_client::tests::send_email_fires_a_request_to_base_url stdout ----
thread 'email_client::tests::send_email_fires_a_request_to_base_url' panicked at
/home/cubewhy/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/wiremock-0.6
.5/src/mock_server/exposed_server.rs:367:17:
Verifications failed:
- Mock #0.
Expected range of matching incoming requests: == 1
Number of matched incoming requests: 0
The server did not receive any request.
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
email_client::tests::send_email_fires_a_request_to_base_url
服务器预期收到一个请求,但实际上没有收到,因此测试失败。
现在是时候完善 EmailClient::send_email 了。
EmailClient::send_email 的第一个草图
要实现 EmailClient::send_email, 我们需要查看 Postmark 的 API 文档。
让我们从他们的“发送单封邮件”用户指南开始。
他们的邮件发送示例如下:
curl "https://api.postmarkapp.com/email" \
-X POST \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-H "X-Postmark-Server-Token: server token" \
-d '{
"From": "sender@example.com",
"To": "receiver@example.com",
"Subject": "Postmark test",
"TextBody": "Hello dear Postmark user.",
"HtmlBody": "<html><body><strong>Hello</strong> dear Postmark user.</body></html>",
"MessageStream": "outbound"
}'
让我们分解一下 - 要发送电子邮件,我们需要:
- 向 /email 端点发送一个 POST 请求
- 一个 JSON 主体,其中包含与
send_email参数紧密映射的字段。我们需要谨慎使用字段名称,必须使用 Pascal-case - 一个授权标头
X-Postmark-Server-Token,其值设置为一个我们可以从其门户网站检索的秘密令牌
如果请求成功,我们会收到类似如下的返回信息:
HTTP/1.1 200 OK
Content-Type: application/json
{
"To": "receiver@example.com",
"SubmittedAt": "2021-01-12T07:25:01.4178645-05:00",
"MessageID": "0a129aee-e1cd-480d-b08d-4f48548ff48d",
"ErrorCode": 0,
"Message": "OK"
}
我们有足够的资源来实现happy path!
reqwest::Client::post
reqwest::Client 公开了一个 post 方法 - 它接受我们想要通过 POST 请求调用的 URL 作为参数,并返回一个 RequestBuilder。
RequestBuilder 为我们提供了一个流畅的 API,让我们可以逐步构建我们想要发送的其余请求。
让我们尝试一下:
//! src/email_client.rs
// [...]
impl EmailClient {
// [...]
pub async fn send_email(
&self,
recipient: SubscriberEmail,
subject: &str,
html_content: &str,
text_content: &str,
) -> Result<(), String> {
// You can do better using `reqwest::Url::join` if you change
// `base_url`'s type from `String' to `reqwest::Url`.
// I'll leave it as an exercise for the reader!
let url = format!("{}/email", self.base_url);
let builder = self.http_client.post(&url);
Ok(())
}
}
JSON Body
我们可以将请求 body 编码为结构体:
//! src/email_client.rs
// [...]
impl EmailClient {
// [...]
pub async fn send_email(
&self,
recipient: SubscriberEmail,
subject: &str,
html_content: &str,
text_content: &str,
) -> Result<(), String> {
let url = format!("{}/email", self.base_url);
let request_body = SendEmailRequest {
from: self.sender.as_ref().to_owned(),
to: recipient.as_ref().to_owned(),
subject: subject.to_owned(),
html_body: html_content.to_owned(),
text_body: text_content.to_owned(),
};
let builder = self.http_client.post(&url);
Ok(())
}
}
struct SendEmailRequest {
from: String,
to: String,
subject: String,
html_body: String,
text_body: String,
}
如果启用了 reqwest 的 json 功能标志(就像我们所做的那样), builder 将公开一个 json 方法,我们可以利用该方法将 request_body 设置为请求的 JSON 主体:
impl EmailClient {
// [...]
pub async fn send_email(
&self,
recipient: SubscriberEmail,
subject: &str,
html_content: &str,
text_content: &str,
) -> Result<(), String> {
let url = format!("{}/email", self.base_url);
let request_body = SendEmailRequest {
from: self.sender.as_ref().to_owned(),
to: recipient.as_ref().to_owned(),
subject: subject.to_owned(),
html_body: html_content.to_owned(),
text_body: text_content.to_owned(),
};
let builder = self.http_client.post(&url).json(&request_body);
Ok(())
}
}
就差一点了!
error[E0277]: the trait bound `SendEmailRequest: configuration::_::_serde::Seria
lize` is not satisfied
--> src/email_client.rs:38:56
|
38 | let builder = self.http_client.post(&url).json(&request_body);
| ---- ^^^^^^^^^^^^^ unsatisfied trait bound
让我们为 SendEmailRequest 派生 serde::Serialize 以使其可序列化:
//! src/email_client.rs
// [...]
#[derive(serde::Serialize)]
struct SendEmailRequest {
from: String,
to: String,
subject: String,
html_body: String,
text_body: String,
}
太棒了,编译通过了!
json 方法比简单的序列化更进一步:它还会将 Content-Type 标头设置为 application/json —— 与我们在示例中看到的一致!
鉴权令牌
快完成了——我们需要在请求中添加一个授权标头, X-Postmark-Server-Token。
就像发件人邮箱地址一样, 我们希望将令牌值作为字段存储在 EmailClient 中。
让我们修改 EmailClient::new 和 EmailClientSettings:
//! src/email_client.rs
use secrecy::SecretBox;
// [...]
pub struct EmailClient {
// [...]
// We don't want to log this by accident
authorization_token: SecretBox<String>,
}
impl EmailClient {
pub fn new(
base_url: String,
sender: SubscriberEmail,
authorization_token: SecretBox<String>,
) -> Self {
Self {
// [...]
authorization_token,
}
}
}
//! src/configuration.rs
// [...]
#[derive(serde::Deserialize)]
pub struct EmailClientSettings {
// [...]
// New (secret) configuration value!
pub authorization_token: SecretBox<String>,
}
然后我们可以让编译器告诉我们还需要修改什么:
//! src/email_client.rs
// [...]
#[cfg(test)]
mod tests {
use fake::{
faker::{internet::en::SafeEmail, lorem::en::Sentence}, Fake, Faker
};
use secrecy::SecretBox;
use wiremock::{Mock, MockServer, ResponseTemplate, matchers::any};
use crate::{domain::SubscriberEmail, email_client::EmailClient};
#[tokio::test]
async fn send_email_fires_a_request_to_base_url() {
// Arrange
let mock_server = MockServer::start().await;
let sender = SubscriberEmail::parse(SafeEmail().fake()).unwrap();
// New argument!
let email_client = EmailClient::new(
mock_server.uri(),
sender,
SecretBox::new(Faker.fake()),
);
// [...]
}
}
//! src/main.rs
// [...]
#[tokio::main]
async fn main() -> std::io::Result<()> {
// [...]
let configuration = get_configuration().expect("Failed to read config");
// [...]
let email_client = EmailClient::new(
configuration.email_client.base_url,
sender_email,
configuration.email_client.authorization_token,
);
// [...]
}
#! configuration/base.yml
# [...]
email_client:
base_url: "localhost"
sender_email: "test@gmail.com"
# New value!
# We are only setting the development value,
# we'll deal with the production token outside of version control
# (given that it's a sensitive secret!)
authorization_token: "my-secret-token"
我们现在可以在 send_email 中使用授权令牌:
//! src/email_client.rs
use secrecy::{ExposeSecret, SecretBox};
// [...]
impl EmailClient {
// [...]
pub async fn send_email(
&self,
recipient: SubscriberEmail,
subject: &str,
html_content: &str,
text_content: &str,
) -> Result<(), String> {
// [...]
let builder = self
.http_client
.post(&url)
.header(
"X-Postmark-Server-Token",
self.authorization_token.expose_secret(),
)
.json(&request_body);
Ok(())
}
}
它立即编译通过。
执行请求
我们已准备好所有材料 - 我们只需要立即发出请求!
我们可以使用 send 方法:
//! src/email_client.rs
// [...]
impl EmailClient {
pub async fn send_email(
&self,
recipient: SubscriberEmail,
subject: &str,
html_content: &str,
text_content: &str,
) -> Result<(), String> {
// [...]
self
.http_client
.post(&url)
.header(
"X-Postmark-Server-Token",
self.authorization_token.expose_secret(),
)
.json(&request_body)
.send()
.await?;
Ok(())
}
}
send 是异步的,因此我们需要等待它返回的 Future。
send 也是一个容易出错的操作——例如,我们可能无法与服务器建立连接。我们希望在 send 失败时返回一个错误——这就是为什么我们使用 ? 运算符。
然而,编译器并不满意:
error[E0277]: `?` couldn't convert the error to `std::string::String`
--> src/email_client.rs:52:19
|
43 | / self
44 | | .http_client
45 | | .post(&url)
46 | | .header(
... |
51 | | .send()
52 | | .await?;
| | -^ unsatisfied trait bound
| |__________________|
send 返回的错误变量类型为 reqwest::Error,而我们的 send_email 使用 String 作为错误类型。编译器查找了转换 (From trait 的实现), 但找不到,因此报错。
还记得吗,我们使用 String 作为错误变量主要是为了占位符——让我们将 send_email 的签名改为返回 Result<(), reqwest::Error>。
//! src/email_client.rs
// [...]
impl EmailClient {
// [...]
pub async fn send_email(
// [...]
) -> Result<(), reqwest::Error> {
// [...]
}
}
现在错误应该消失了!
cargo test 也应该通过: 恭喜!
注: 测试中的方法签名错误需要你自己修复, 本教程没有提及, 我相信你可以做到的
加强 happy path 测试
让我们再次看一下我们的“happy path”测试:
//! src/email_client.rs
// [...]
#[cfg(test)]
mod tests {
use fake::{
Fake, Faker,
faker::{internet::en::SafeEmail, lorem::en::Sentence},
};
use secrecy::SecretBox;
use wiremock::{Mock, MockServer, ResponseTemplate, matchers::any};
use crate::{domain::SubscriberEmail, email_client::EmailClient};
#[tokio::test]
async fn send_email_fires_a_request_to_base_url() {
// Arrange
let mock_server = MockServer::start().await;
let sender = SubscriberEmail::parse(SafeEmail().fake()).unwrap();
let email_client =
EmailClient::new(mock_server.uri(), sender, SecretBox::new(Faker.fake()));
Mock::given(any())
.respond_with(ResponseTemplate::new(200))
.expect(1)
.mount(&mock_server)
.await;
let subscriber_email = SubscriberEmail::parse(SafeEmail().fake()).unwrap();
let subject: String = Sentence(1..2).fake();
let content: String = Sentence(1..10).fake();
// Act
let _ = email_client
.send_email(subscriber_email, &subject, &content, &content)
.await;
// Assert
}
}
为了轻松上手 wiremock,我们从一些非常基础的操作开始——我们只是断言模拟服务器被调用了一次。接下来,让我们进一步完善它,检查发出的请求是否确实符合我们的预期。
Headers, Path 和 Method
any 并非 wiremock 提供的唯一开箱即用的匹配器:wiremock 的 matchers 模块中还有许多其他可用的匹配器。
我们可以使用 header_exists 来验证 X-Postmark-Server-Token 是否已在发送至服务器的请求中设置:
//! src/email_client.rs
// [...]
#[cfg(test)]
mod tests {
use fake::{
Fake, Faker,
faker::{internet::en::SafeEmail, lorem::en::Sentence},
};
use secrecy::SecretBox;
use wiremock::{matchers::{any, header_exists}, Mock, MockServer, ResponseTemplate};
use crate::{domain::SubscriberEmail, email_client::EmailClient};
#[tokio::test]
async fn send_email_fires_a_request_to_base_url() {
Mock::given(header_exists("X-Postmark-Server-Token"))
.respond_with(ResponseTemplate::new(200))
.expect(1)
.mount(&mock_server)
.await;
}
}
我们可以使用 and 方法将多个匹配器连接在一起。
让我们添加 header 来检查 Content-Type 是否设置为正确的值,添加 path 来在被调用的端点上进行断言,以及添加 method 来验证 HTTP 方法:
//! src/email_client.rs
// [...]
#[cfg(test)]
mod tests {
use wiremock::matchers::{header, header_exists, method, path}
#[tokio::test]
async fn send_email_fires_a_request_to_base_url() {
// [...]
Mock::given(header_exists("X-Postmark-Server-Token"))
.and(header("Content-Type", "application/json"))
.and(path("/email"))
.and(method("POST"))
.respond_with(ResponseTemplate::new(200))
.expect(1)
.mount(&mock_server)
.await;
// [...]
}
}
Body
到目前为止,一切顺利: cargo test 仍然通过。
那么请求体呢?
我们可以使用 body_json 来精确匹配请求体。
我们可能不需要那么深入——只要检查请求体是否为有效的 JSON 格式,并且包含 Postmark 示例中所示的字段名称集合就足够了。
目前没有现成的匹配器能满足我们的需求——我们需要自己实现!
wiremock 暴露了一个 Match trait——所有实现该 trait 的程序都可以在给定的匹配器中用作匹配器。
让我们把它存根掉:
//! src/email_client.rs
// [...]
#[cfg(test)]
mod tests {
// [...]
struct SendEmailBodyMatcher;
impl wiremock::Match for SendEmailBodyMatcher {
fn matches(&self, request: &wiremock::Request) -> bool {
unimplemented!();
}
}
// [...]
}
我们将传入的请求作为输入 request, 并需要返回一个布尔值作为输出:
如果模拟匹配,则返回 true; 否则返回 false。
我们需要将请求主体反序列化为 JSON——让我们将 serde_json 添加到我们的开发依赖项列表中:
cargo add serde_json --dev
现在我们可以编写 matches 的实现:
//! src/email_client.rs
// [...]
#[cfg(test)]
mod tests {
struct SendEmailBodyMatcher;
impl wiremock::Match for SendEmailBodyMatcher {
fn matches(&self, request: &wiremock::Request) -> bool {
// Try to parse the body as a JSON value
let result: Result<serde_json::Value, _> =
serde_json::from_slice(&request.body);
if let Ok(body) = result {
// Check that all the mandatory fields are populated
// without inspecting the field values
body.get("From").is_some()
&& body.get("To").is_some()
&& body.get("Subject").is_some()
&& body.get("HtmlBody").is_some()
&& body.get("TextBody").is_some()
} else {
// If parsing failed, do not match the request
false
}
}
}
#[tokio::test]
async fn send_email_fires_a_request_to_base_url() {
// [...]
Mock::given(header_exists("X-Postmark-Server-Token"))
.and(header("Content-Type", "application/json"))
.and(path("/email"))
.and(method("POST"))
// Use our custom matcher!
.and(SendEmailBodyMatcher)
.respond_with(ResponseTemplate::new(200))
.expect(1)
.mount(&mock_server)
.await;
// [...]
}
}
编译成功了!
但是我们的测试现在失败了...
---- email_client::tests::send_email_fires_a_request_to_base_url stdout ----
thread 'email_client::tests::send_email_fires_a_request_to_base_url' panicked at
/home/cubewhy/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/wiremock-0.6
.5/src/mock_server/exposed_server.rs:367:17:
Verifications failed:
- Mock #0.
Expected range of matching incoming requests: == 1
Number of matched incoming requests: 0
Received requests:
- Request #1
POST http://localhost/email
x-postmark-server-token: HjhDDhi05zX5gNM
content-type: application/json
accept: */*
host: 127.0.0.1:43849
content-length: 138
{"from":"joaquin@example.net","to":"weldon@example.com","subject":"fuga.","html_
body":"nam ut esse amet.","text_body":"nam ut esse amet."}
为什么会这样?
我们好像忘了大小写要求——字段名称必须使用 Pascal 大小写!
我们可以通过在 SendEmailRequest 上添加注解来轻松解决这个问题!
//! src/email_client.rs
// [...]
#[derive(serde::Serialize)]
#[serde(rename_all = "PascalCase")]
struct SendEmailRequest {
from: String,
to: String,
subject: String,
html_body: String,
text_body: String,
}
测试现在应该可以通过了。
在继续下一步之前,让我们将测试重命名为 send_email_sends_the_expected_request —— 这样可以更好地体现测试目的。
重构:避免不必要的内存分配
我们专注于让 send_email 正常工作——现在我们可以再次检查一下, 看看是否还有改进的空间。
让我们放大查看请求正文:
//! src/email_client.rs
// [...]
impl EmailClient {
pub fn new(
base_url: String,
sender: SubscriberEmail,
authorization_token: SecretBox<String>,
) -> Self {
Self {
http_client: Client::new(),
base_url,
sender,
authorization_token,
}
}
pub async fn send_email(
&self,
recipient: SubscriberEmail,
subject: &str,
html_content: &str,
text_content: &str,
) -> Result<(), reqwest::Error> {
// [...]
let request_body = SendEmailRequest {
from: self.sender.as_ref().to_owned(),
to: recipient.as_ref().to_owned(),
subject: subject.to_owned(),
html_body: html_content.to_owned(),
text_body: text_content.to_owned(),
};
// [...]
}
}
#[derive(serde::Serialize)]
#[serde(rename_all = "PascalCase")]
struct SendEmailRequest {
from: String,
to: String,
subject: String,
html_body: String,
text_body: String,
}
对于每个字段,我们都会分配一大堆新内存来存储克隆的字符串——这很浪费。更高效的方法是引用现有数据而不执行任何额外的分配。
我们可以通过重构 SendEmailRequest 来实现这一点:所有字段的类型都改为字符串切片 (&str),而不是字符串。
字符串切片只是一个指向他人拥有的内存缓冲区的指针。为了将引用存储在结构体中,我们需要添加一个生命周期参数: 它会跟踪这些引用的有效期——编译器的职责是确保引用的保留时间不超过它们指向的内存缓冲区!
我们开始吧!
//! src/email_client.rs
// [...]
impl EmailClient {
pub fn new(
base_url: String,
sender: SubscriberEmail,
authorization_token: SecretBox<String>,
) -> Self {
Self {
http_client: Client::new(),
base_url,
sender,
authorization_token,
}
}
pub async fn send_email(
&self,
recipient: SubscriberEmail,
subject: &str,
html_content: &str,
text_content: &str,
) -> Result<(), reqwest::Error> {
// [...]
let request_body = SendEmailRequest {
from: self.sender.as_ref(),
to: recipient.as_ref(),
subject: subject,
html_body: html_content,
text_body: text_content,
};
// [...]
}
}
#[derive(serde::Serialize)]
#[serde(rename_all = "PascalCase")]
// Lifetime parameters always start with an apostrophe, `'`
struct SendEmailRequest<'a> {
from: &'a str,
to: &'a str,
subject: &'a str,
html_body: &'a str,
text_body: &'a str,
}
就是这样,快速又轻松——Serde 为我们完成了所有繁重的工作,我们得到了更高性能的代码!
处理失败
我们已经很好地掌握了最佳路径——如果事情没有按预期进行,会发生什么?
我们将讨论两种情况:
- 不成功状态代码(例如 4xx、5xx 等)
- 响应缓慢
错误状态码
我们当前的 happy path 测试仅对 send_email 执行的副作用进行断言——我们实际上并没有检查它的返回值!
让我们确保如果服务器返回 200 OK,它就是 Ok(()):
//! src/email_client.rs
// [...]
#[cfg(test)]
mod tests {
// New happy-path test!
#[tokio::test]
async fn send_email_succeeds_if_the_server_returns_200() {
// Arrange
let mock_server = MockServer::start().await;
let sender = SubscriberEmail::parse(SafeEmail().fake()).unwrap();
let email_client = EmailClient::new(
mock_server.uri(),
sender,
SecretBox::new(Box::new(Faker.fake()))
);
let subscriber_email = SubscriberEmail::parse(SafeEmail().fake()).unwrap();
let subject: String = Sentence(1..2).fake();
let content: String = Paragraph(1..10).fake();
// We do not copy in all the matchers we have in the other test.
// The purpose of this test is not to assert on the request we
// are sending out!
// We add the bare minimum needed to trigger the path we want
// to test in `send_email`.
Mock::given(any())
.respond_with(ResponseTemplate::new(200))
.expect(1)
.mount(&mock_server)
.await;
// Act
let outcome = email_client
.send_email(subscriber_email, &subject, &content, &content)
.await;
// Assert
assert_ok!(outcome);
}
}
不出所料,测试通过了。
现在让我们看看相反的情况——如果服务器返回 500 Internal Server Error, 我们预期会出现 Err。
//! src/email_client.rs
// [...]
#[cfg(test)]
mod tests {
#[tokio::test]
async fn send_email_fails_of_the_server_returns_500() {
// Arrange
let mock_server = MockServer::start().await;
let sender = SubscriberEmail::parse(SafeEmail().fake()).unwrap();
let email_client = EmailClient::new(
mock_server.uri(),
sender,
SecretBox::new(Box::new(Faker.fake())),
);
let subscriber_email = SubscriberEmail::parse(SafeEmail().fake()).unwrap();
let subject: String = Sentence(1..2).fake();
let content: String = Paragraph(1..10).fake();
Mock::given(any())
// Not a 200 anymore!
.respond_with(ResponseTemplate::new(500))
.expect(1)
.mount(&mock_server)
.await;
// Act
let outcome = email_client
.send_email(subscriber_email, &subject, &content, &content)
.await;
// Assert
assert_err!(outcome);
}
}
我们这里还有一些工作要做:
test email_client::tests::send_email_fails_of_the_server_returns_500 ... FAILED
failures:
---- email_client::tests::send_email_fails_of_the_server_returns_500 stdout ----
thread 'email_client::tests::send_email_fails_of_the_server_returns_500' panicke
d at src/email_client.rs:195:9:
assertion failed, expected Err(..), got Ok(())
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
让我们再看看 send_email:
//! src/email_client.rs
// [...]
impl EmailClient {
// [...]
pub async fn send_email(
// [...]
) -> Result<(), reqwest::Error> {
let url = format!("{}/email", self.base_url);
let request_body = SendEmailRequest {
from: self.sender.as_ref(),
to: recipient.as_ref(),
subject: subject,
html_body: html_content,
text_body: text_content,
};
self.http_client
.post(&url)
.header(
"X-Postmark-Server-Token",
self.authorization_token.expose_secret(),
)
.json(&request_body)
.send()
.await?;
Ok(())
}
}
唯一可能返回错误的步骤是 send - 让我们检查 reqwest 的文档!
如果发送请求时出现错误、检测到重定向循环或重定向限制已用尽,则此方法失败。
基本上,只要从服务器收到有效响应, send 就会返回 Ok ——无论状态码是什么!
为了获得我们想要的行为,我们需要查看 reqwest::Response 中可用的方法——特别是 error_for_status:
如果服务器返回错误,则将响应转变为错误。
它似乎符合我们的需要,让我们尝试一下。
//! src/email_client.rs
// [...]
impl EmailClient {
// [...]
pub async fn send_email(
// [...]
) -> Result<(), reqwest::Error> {
// [...]
self.http_client
.post(&url)
.header(
"X-Postmark-Server-Token",
self.authorization_token.expose_secret(),
)
.json(&request_body)
.send()
.await?
.error_for_status()?;
Ok(())
}
}
太棒了,测试通过了!
超时
如果服务器返回 200 OK,但需要很长时间才能返回,会发生什么情况?
我们可以指示我们的模拟服务器等待一段可配置的时间后再发送响应。
让我们用一个新的集成测试稍微试验一下——如果服务器需要 3 分钟才能响应怎么办!?
//! src/email_client.rs
// [...]
#[cfg(test)]
mod tests {
// [...]
#[tokio::test]
async fn send_email_times_out_if_the_server_takes_too_long() {
// Arrange
let mock_server = MockServer::start().await;
let sender = SubscriberEmail::parse(SafeEmail().fake()).unwrap();
let email_client = EmailClient::new(
mock_server.uri(),
sender,
SecretBox::new(Box::new(Faker.fake())),
);
let subscriber_email = SubscriberEmail::parse(SafeEmail().fake()).unwrap();
let subject: String = Sentence(1..2).fake();
let content: String = Paragraph(1..10).fake();
let response = ResponseTemplate::new(200)
// 3 minutes!
.set_delay(std::time::Duration::from_secs(180));
Mock::given(any())
.respond_with(response)
.expect(1)
.mount(&mock_server)
.await;
// Act
let outcome = email_client
.send_email(subscriber_email, &subject, &content, &content)
.await;
// Assert
assert_err!(outcome);
}
}
过了一会儿,你应该会看到类似这样的内容:
test email_client::tests::send_email_times_out_if_the_server_takes_too_long has
been running for over 60 seconds
这远非理想情况:如果服务器开始出现问题,我们可能会开始积累多个“挂起”的请求。
我们并没有挂起服务器,所以连接处于繁忙状态:每次我们需要发送电子邮件时, 我们都必须打开一个新的连接。如果服务器恢复速度不够快,而我们又没有关闭任何打开的连接,最终可能会导致套接字耗尽/性能下降。
经验法则:每次执行 IO 操作时,务必设置超时!
如果服务器响应时间超过超时时间,我们就应该失败并返回错误。
选择合适的超时值通常更像是一门艺术而非科学,尤其是在涉及重试的情况下: 设置得太低,可能会使服务器不堪重负; 设置得太高,则可能会再次面临客户端性能下降的风险。
尽管如此,设置一个保守的超时阈值总比没有好。
reqwest 提供了两种选择: 我们可以在客户端本身添加一个默认超时时间,该时间适用于所有发出的请求;或者,我们可以为每个请求指定一个超时时间。
我们来设置一个客户端范围的超时时间: 我们将在 EmailClient::new 中设置它。
//! src/email_client.rs
// [...]
impl EmailClient {
pub fn new(
base_url: String,
sender: SubscriberEmail,
authorization_token: SecretBox<String>,
) -> Self {
let http_client = Client::builder()
.timeout(std::time::Duration::from_secs(10))
.build()
.unwrap();
Self {
http_client,
base_url,
sender,
authorization_token,
}
}
}
// [...]
如果我们再次运行测试,它应该会通过(10秒后)。
重构:测试辅助函数
四个 EmailClient 测试中有很多重复的代码,让我们从一组测试助手中提取出其中的共同点。
//! src/email_client.rs
// [...]
#[cfg(test)]
mod tests {
// [...]
/// Generate a ranodm email subject
fn subject() -> String {
Sentence(1..2).fake()
}
/// Generate a random email content
fn content() -> String {
Paragraph(1..10).fake()
}
/// Generate a ranadom subscriber email
fn email() -> SubscriberEmail {
SubscriberEmail::parse(SafeEmail().fake()).unwrap()
}
/// Get a test instance of `EmailClient`.
fn email_client(base_url: String) -> EmailClient {
EmailClient::new(base_url, email(), SecretBox::new(Box::new(Faker.fake())))
}
// [...]
}
让我们在 send_email_sends_the_expected_request 中使用它们:
//! src/email_client.rs
// [...]
#[cfg(test)]
mod tests {
// [...]
#[tokio::test]
async fn send_email_sends_the_expected_request() {
// Arrange
let mock_server = MockServer::start().await;
let email_client = email_client(mock_server.uri());
Mock::given(header_exists("X-Postmark-Server-Token"))
.and(header("Content-Type", "application/json"))
.and(path("/email"))
.and(method("POST"))
.and(SendEmailBodyMatcher)
.respond_with(ResponseTemplate::new(200))
.expect(1)
.mount(&mock_server)
.await;
let subscriber_email = SubscriberEmail::parse(SafeEmail().fake()).unwrap();
let subject: String = Sentence(1..2).fake();
let content: String = Sentence(1..10).fake();
// Act
let _ = email_client
.send_email(subscriber_email, &subject, &content, &content)
.await;
// Assert
}
}
视觉干扰更少——测试的目的才是核心。
继续重构其他三个!
注: 我相信你知道怎么重构另外三个测试了, 所以这里没有列出详细的代码。
重构: 让测试失败的快一点
我们的 HTTP 客户端的超时时间目前硬编码为 10 秒
//! src/email_client.rs
// [...]
impl EmailClient {
pub fn new(
base_url: String,
sender: SubscriberEmail,
authorization_token: SecretBox<String>,
) -> Self {
let http_client = Client::builder()
.timeout(std::time::Duration::from_secs(10))
// [...]
}
// [...]
}
这意味着我们的超时测试大约需要 10 秒才会失败——这是一个很长的时间,尤其是如果你在每次小改动后都要运行测试的话。
让我们将超时阈值设置为可配置,以保持测试套件的响应速度。
//! src/email_client.rs
// [...]
impl EmailClient {
pub fn new(
base_url: String,
sender: SubscriberEmail,
authorization_token: SecretBox<String>,
// New argument!
timeout: std::time::Duration,
) -> Self {
let http_client = Client::builder()
.timeout(timeout)
// [...]
}
}
//! src/configuration.rs
// [...]
#[derive(serde::Deserialize)]
pub struct EmailClientSettings {
// [...]
// New configuration value!
pub timeout_milliseconds: u64,
}
impl EmailClientSettings {
// [...]
pub fn timeout(&self) -> std::time::Duration {
std::time::Duration::from_millis(self.timeout_milliseconds)
}
}
//! src/main.rs
// [...]
#[tokio::main]
async fn main() -> std::io::Result<()> {
// [...]
let sender_email = configuration.email_client.sender()
.expect("Invalid sender email address");
let timeout = configuration.email_client.timeout();
let email_client = EmailClient::new(
configuration.email_client.base_url,
sender_email,
configuration.email_client.authorization_token,
timeout,
);
// [...]
}
#! configuration/base.yaml
# [...]
email_client:
# [...]
timeout_milliseconds: 10000
项目应该可以编译了。
不过我们仍然需要编辑测试!
//! src/email_client.rs
// [...]
#[cfg(test)]
mod tests {
// [...]
fn email_client(base_url: String) -> EmailClient {
EmailClient::new(
base_url,
email(),
SecretBox::new(Box::new(Faker.fake())),
// Much lower than 10s!
std::time::Duration::from_millis(200),
)
}
}
//! tests/health_check.rs
// [...]
async fn spawn_app() -> TestApp {
// [...]
let sender_email = configuration
.email_client
.sender()
.expect("Invalid sender email address.");
let timeout = configuration.email_client.timeout();
let email_client = EmailClient::new(
configuration.email_client.base_url,
sender_email,
SecretBox::new(Box::new(Faker.fake())),
timeout,
);
// [...]
}
所有测试都应该成功——并且整个测试套件的总执行时间应该缩短到一秒以内。
可维护测试套件的框架和原则
我们花了不少功夫,现在终于为 Postmark 的 API 打造了一个相当不错的 REST 客户端。
EmailClient 只是我们确认邮件流程的第一个组成部分:我们还没有找到一种方法来生成唯一的确认链接,然后我们必须将其嵌入到发出的确认邮件的正文中。
这两项任务都需要再等一段时间。
我们一直采用测试驱动的方法来编写本书中的所有新功能。
虽然这种策略效果很好,但我们并没有投入大量时间重构测试代码。
因此,我们的测试文件夹目前有点混乱。
在继续下一步之前,我们将重构集成测试套件,以应对应用程序复杂性和测试数量的增长。
我们为什么要写测试
编写测试是否合理利用了开发人员的时间?
好的测试套件首先是一种风险缓解措施。
自动化测试可以降低现有代码库变更带来的风险——大多数回归测试和错误都会被捕获在持续集成流水线中,而不会影响到用户。因此,团队能够更快地迭代并更频繁地发布。
测试也充当文档的作用。
深入研究未知代码库时,测试套件通常是最佳起点——它向您展示了代码的预期行为,以及哪些场景被认为足够相关,需要进行专门的测试。
如果您想让您的项目更受新贡献者的欢迎,“编写测试套件!”绝对应该列在您的待办事项清单上。
好的测试通常还会带来其他积极的副作用——模块化和解耦。这些副作用很难量化,因为作为一个行业,我们尚未就“好代码”的具体样貌达成一致。
为什么我们不写测试
尽管投入时间和精力编写优秀的测试套件的理由令人信服,但现实情况却并非如此。
首先,开发社区并非一直相信测试的价值。
在整个测试驱动开发学科的发展史上,我们都能找到不少例子,但直到1999年《极限编程》(XP) 一书的出版,这项实践才进入主流讨论!
范式转变并非一朝一夕之功——测试驱动方法花了数年时间才在行业内获得认可,成为“最佳实践”。
如果说测试驱动开发已经赢得了开发人员的青睐,那么与管理层的斗争往往仍在继续。
好的测试能够构建技术杠杆,但编写测试需要时间。当截止日期迫在眉睫时,测试往往是第一个被牺牲的。
因此,你找到的大多数资料要么是测试的介绍,要么是如何向利益相关者推介其价值的指南。
关于大规模测试的内容很少——如果你坚持照本宣科,继续编写测试,当代码库增长到数万行,包含数百个测试用例时,会发生什么?
测试代码仍然是代码
所有测试套件都以同样的方式开始:一个空文件,一个充满可能性的世界。
你进入文件,添加第一个测试。很简单,搞定。
然后是第二个。轰!
第三个。你只需要从第一个代码中复制几行,就完成了。
第四个……
一段时间后,测试覆盖率开始下降:新代码的测试不如你在项目初期编写的代码那么彻底。你是否开始怀疑测试的价值了?
绝对没有,测试很棒!
然而,随着项目的推进,你编写的测试越来越少。
这是因为摩擦——随着代码库的演变,编写新的测试变得越来越繁琐。
测试代码仍然是代码
它必须是模块化的、结构良好的、文档齐全的。它需要维护。
如果我们不积极投入精力维护测试套件的健康状况,它就会随着时间的推移而腐烂。
覆盖率下降,很快我们就会发现应用程序代码中的关键路径从未被自动化测试执行过。
你需要定期回顾一下你的测试套件,从整体上审视它。
是时候审视一下我们的测试套件了,不是吗?
我们的测试套件
我们所有的集成测试都位于一个文件 tests/health_check.rs 中:
//! tests/health_check.rs
// [...]
//! tests/health_check.rs
// Ensure that the `tracing` stack is only initialised once using `once_cell`
static TRACING: Lazy<()> = Lazy::new(|| {
// [...]
});
pub struct TestApp {
pub address: String,
pub db_pool: PgPool,
}
async fn spawn_app() -> TestApp {
// [...]
}
pub async fn configure_database(config: &DatabaseSettings) -> PgPool {
// [...]
}
#[tokio::test]
async fn health_check_works() {
// [...]
}
#[tokio::test]
async fn subscribe_returns_a_200_for_valid_form_data() {
// [...]
}
#[tokio::test]
async fn subscribe_returns_a_400_when_data_is_missing() {
// [...]
}
#[tokio::test]
async fn subscribe_returns_a_200_when_fields_are_present_but_invalid() {
// [...]
}
测试发现
只有一个测试用于处理我们的健康检查端点 - health_check_works。
其他三个测试用于探测我们的 POST /subscriptions 端点,而其余代码则用于处理共享的设置步骤(spawn_app、TestApp、configure_database 和 TRACING)。
为什么我们将所有内容都放在 tests/health_check.rs 中?
因为这样很方便!
设置函数已经存在 - 在同一个文件中添加另一个测试用例比弄清楚如何在多个测试模块之间正确共享代码更容易。
我们此次重构的主要目标是可发现性:
- 给定一个应用程序端点,应该能够在
tests文件夹中轻松找到相应的集成测试 - 编写测试时,应该能够轻松找到相关的测试辅助函数
我们将重点介绍文件夹结构,但这绝对不是测试发现的唯一工具。
测试覆盖率工具通常可以告诉您哪些测试触发了特定应用程序代码行的执行。
您可以依靠覆盖率标记等技术在测试和应用程序代码之间建立明显的联系。
与往常一样,随着测试套件复杂度的增加,多管齐下的方法可能会为您带来最佳效果。
一个测试文件, 一个 Crate
在开始移动之前,让我们先了解一些关于 Rust 集成测试的知识。
tests 文件夹比较特殊——Cargo 知道去里面查找集成测试。
tests 文件夹下的每个文件都会被编译成一个独立的 crate。
我们可以通过运行 cargo build --tests 命令,然后在 target/debug/deps 目录下查找来验证这一点:
# Build test code, without running tests
cargo build --tests
# Find all files with a name starting with `health_check`
ls target/debug/deps | grep health_check
health_check-3b9db97bf61f8d77
health_check-3b9db97bf61f8d77.d
health_check-e064e6b2bbe87e3b.d
libhealth_check-e064e6b2bbe87e3b.rmeta
您的机器上的尾部哈希值可能会有所不同,但应该有两个以 health_check-* 开头的条目。
如果您尝试运行它会发生什么?
running 4 tests
test health_check_works ... ok
test subscribe_returns_a_400_when_fields_are_present_but_invalid ... ok
test subscribe_returns_a_400_when_data_is_missing ... ok
test subscribe_returns_a_200_for_valid_form_data ... ok
test result: ok. 4 passed; finished in 0.44s
没错,它运行我们的集成测试!
如果我们测试了五个 *.rs 文件,我们会在 target/debug/deps 中找到五个可执行文件。
共享测试 Helper 方法
如果每个集成测试文件都是独立的可执行文件,那么我们如何共享测试辅助函数呢?
第一个选项是定义一个独立的模块,例如 tests/helpers.rs 。
您可以在 helper.rs 中添加常用函数(或在其中定义其他子模块),然后在测试文件 (例如 tests/health_check.rs) 中引用这些辅助函数,如下所示:
//! tests/health_check.rs
// [...]
mod helpers;
// [...]
helpers 被捆绑在 health_check 测试可执行文件中,并作为子模块,我们可以访问它在测试用例中公开的函数。
这种方法一开始效果不错,但最终会导致恼人的“函数从未使用”警告。
问题在于, helpers 被捆绑为子模块,而不是作为第三方 crate 调用: cargo 会单独编译每个测试可执行文件,如果某个测试文件中的 helpers 中的一个或多个公共函数从未被调用,则会发出警告。随着测试套件的增长,这种情况必然会发生——并非所有测试文件都会使用所有辅助方法。
第二种方案充分利用了 tests 下每个文件都是独立可执行文件这一特点——我们可以创建作用域为单个测试可执行文件的子模块!
让我们在 tests 下创建一个 api 文件夹,其中包含一个 main.rs 文件:
tests/
api/
main.rs
health_check.rs
首先,我们要明确一点:我们构建 API 的方式与构建二进制 crate 的方式完全相同。它没有那么多魔法——它建立在你编写应用程序代码时构建的模块系统知识之上。
如果你运行 cargo build --tests,你应该能够发现
Running target/debug/deps/api-0a1bfb817843fdcf
running 0 tests
test result: ok. 0 passed; finished in 0.00s
在输出中 - cargo 将 api 编译为测试可执行文件,并查找测试用例。
无需在 main.rs 中定义 main 函数 - Rust 测试框架会在后台为我们添加一个。
我们现在可以在 main.rs 中添加子模块:
//! tests/api/main.rs
mod helpers;
mod health_check;
mod subscriptions;
添加三个空文件: tests/api/helpers.rs、tests/api/health_check.rs 和 tests/api/subscriptions.rs。
现在是时候删除 tests/health_check.rs 并重新分发其内容了:
//! tests/api/helpers.rs
use fake::{Fake, Faker};
use once_cell::sync::Lazy;
use secrecy::SecretBox;
use sqlx::Executor;
use std::net::TcpListener;
use sqlx::{Connection, PgConnection, PgPool};
use uuid::Uuid;
use zero2prod::{
configuration::{DatabaseSettings, get_configuration},
email_client::EmailClient,
telemetry::{get_subscriber, init_subscriber},
};
// Ensure that the `tracing` stack is only initialised once using `once_cell`
static TRACING: Lazy<()> = Lazy::new(|| {
/// [...]
});
pub struct TestApp {
pub address: String,
pub db_pool: PgPool,
}
pub async fn spawn_app() -> TestApp {
// [...]
}
pub async fn configure_database(config: &DatabaseSettings) -> PgPool {
// [...]
}
//! tests/api/health_check.rs
use crate::helpers::spawn_app;
#[tokio::test]
async fn health_check_works() {
// [...]
}
//! tests/api/subscriptions.rs
use crate::helpers::spawn_app;
#[tokio::test]
async fn subscribe_returns_a_200_for_valid_form_data() {
// [...]
}
#[tokio::test]
async fn subscribe_returns_a_400_when_data_is_missing() {
// [...]
}
#[tokio::test]
async fn subscribe_returns_a_200_when_fields_are_present_but_invalid() {
// [...]
}
cargo test 应该会成功,并且不会出现任何警告。
恭喜,您已将测试套件分解为更小、更易于管理的模块!
新的结构有一些积极的副作用: 它是递归的。
如果 tests/api/subscriptions.rs 变得过于庞大,我们可以将其转换为一个模块,其中 tests/api/subscriptions/helpers.rs 包含特定于订阅的测试帮助程序以及一个或多个专注于特定流程或关注点的测试文件; - 我们的帮助程序函数的实现细节被封装了。
事实证明,我们的测试只需要了解 spawn_app 和 TestApp - 无需暴露 configure_database 或 TRACING,我们可以将这些复杂性隐藏在帮助程序模块中 - 我们只有一个测试二进制文件。
如果您有一个采用扁平文件结构的大型测试套件,那么每次运行 cargo test 时,您很快就会构建数十个可执行文件。虽然每个可执行文件都是并行编译的,但链接阶段却是完全顺序执行的!将所有测试用例打包成一个可执行文件可以减少在 CI 中编译测试套件的时间。
如果您正在运行 Linux,您可能会看到类似这样的错误
thread 'actix-rt:worker' panicked at
'Can not create Runtime: Os { code: 24, kind: Other, message: "Too many open files" }',
重构后运行 cargo test 时。
这是由于操作系统对每个进程打开的文件描述符(包括套接字)的最大数量进行了限制——考虑到我们现在将所有测试都作为单个二进制文件的一部分运行,我们可能会超出这个限制。该限制通常设置为 1024,但您可以使用 ulimit -n X (例如 ulimit -n 10000) 来提高该限制以解决此问题。
共享 Startup 逻辑
现在我们已经重新设计了测试套件的布局,是时候深入研究测试逻辑本身了。
我们将从 spawn_app 开始:
//! tests/api/helpers.rs
// [...]
pub struct TestApp {
pub address: String,
pub db_pool: PgPool,
}
pub async fn spawn_app() -> TestApp {
// The first time `initialize` is invoked the code in `TRACING` is executed.
// All other invocations will instead skip execution.
Lazy::force(&TRACING);
let listener = TcpListener::bind("127.0.0.1:0").expect("Faield to bind random port");
// We retrieve the port assigned to us by the OS
let port = listener.local_addr().unwrap().port();
let address = format!("http://127.0.0.1:{}", port);
let mut configuration = get_configuration().expect("");
configuration.database.database_name = Uuid::new_v4().to_string();
let connection_pool = configure_database(&configuration.database).await;
// Build a new email client
let sender_email = configuration
.email_client
.sender()
.expect("Invalid sender email address.");
let timeout = configuration.email_client.timeout();
let email_client = EmailClient::new(
configuration.email_client.base_url,
sender_email,
SecretBox::new(Box::new(Faker.fake())),
timeout,
);
let server = zero2prod::run(listener, connection_pool.clone(), email_client)
.expect("Failed to bind address");
let _ = tokio::spawn(server);
TestApp {
address,
db_pool: connection_pool,
}
}
// [...]
这里的大部分代码与我们在 main 入口点中发现的代码极为相似:
//! src/main.rs
#[tokio::main]
async fn main() -> std::io::Result<()> {
let subscriber = get_subscriber("zero2prod", "info", std::io::stdout);
init_subscriber(subscriber);
let configuration = get_configuration().expect("Failed to read config");
let connection_pool = PgPoolOptions::new()
.acquire_timeout(std::time::Duration::from_secs(2))
.connect_lazy_with(configuration.database.with_db());
let sender_email = configuration.email_client.sender()
.expect("Invalid sender email address");
let timeout = configuration.email_client.timeout();
let email_client = EmailClient::new(
configuration.email_client.base_url,
sender_email,
configuration.email_client.authorization_token,
timeout,
);
let address = format!(
"{}:{}",
configuration.application.host, configuration.application.port
);
let listener = TcpListener::bind(address)?;
run(listener, connection_pool, email_client)?.await
}
每次添加依赖项或修改服务器构造函数时,我们至少有两个地方需要修改——最近我们只是敷衍地修改了 EmailClient。这有点烦人。
更重要的是,我们应用程序代码中的启动逻辑从未经过测试。
随着代码库的演变,它们可能会开始出现细微的差异,导致测试代码与生产环境中的行为有所不同。
我们将首先从主函数中提取逻辑,然后找出在测试代码中利用相同代码路径所需的钩子。
提取 Startup 代码
从结构角度来看,我们的启动逻辑是一个函数, 它以“设置”作为输入,并返回一个应用程序实例作为输出。
因此,我们的主函数应该如下所示:
//! src/main.rs
#[tokio::main]
async fn main() -> std::io::Result<()> {
let subscriber = get_subscriber("zero2prod", "info", std::io::stdout);
init_subscriber(subscriber);
let configuration = get_configuration().expect("Failed to read config");
let server = build(configuration).await?;
server.await?;
Ok(())
}
我们首先执行一些二进制特定的逻辑(例如遥测初始化),然后从支持的源(文件 + 环境变量)构建一组配置值,并使用它来启动一个应用程序。线性的。
然后我们定义这个 build 函数:
//! src/startup.rs
// [...]
use crate::configuration::Settings;
use sqlx::postgres::PgPoolOptions;
pub async fn build(configuration: Settings) -> Result<Server, std::io::Error> {
let connection_pool = PgPoolOptions::new()
.acquire_timeout(std::time::Duration::from_secs(2))
.connect_lazy_with(configuration.database.with_db());
// Build an `EmailClient` using `configuration`
let sender_email = configuration
.email_client
.sender()
.expect("Invalid sender email address");
let timeout = configuration.email_client.timeout();
let email_client = EmailClient::new(
configuration.email_client.base_url,
sender_email,
configuration.email_client.authorization_token,
timeout,
);
let address = format!(
"{}:{}",
configuration.application.host, configuration.application.port
);
let listener = TcpListener::bind(address)?;
run(listener, connection_pool, email_client)
}
没什么特别的——我们只是移动了之前主函数里的代码。现在就让它更易于测试吧!
在我们的启动逻辑中测试钩子
让我们再次看一下 spawn_app 函数:
//! tests/api/helpers.rs
// [...]
use zero2prod::startup::build;
// [...]
pub async fn spawn_app() -> TestApp {
// The first time `initialize` is invoked the code in `TRACING` is executed.
// All other invocations will instead skip execution.
Lazy::force(&TRACING);
let listener = TcpListener::bind("127.0.0.1:0").expect("Faield to bind random port");
// We retrieve the port assigned to us by the OS
let port = listener.local_addr().unwrap().port();
let address = format!("http://127.0.0.1:{}", port);
let mut configuration = get_configuration().expect("");
configuration.database.database_name = Uuid::new_v4().to_string();
let connection_pool = configure_database(&configuration.database).await;
// Build a new email client
let sender_email = configuration
.email_client
.sender()
.expect("Invalid sender email address.");
let timeout = configuration.email_client.timeout();
let email_client = EmailClient::new(
configuration.email_client.base_url,
sender_email,
SecretBox::new(Box::new(Faker.fake())),
timeout,
);
let server = zero2prod::run(listener, connection_pool.clone(), email_client)
.expect("Failed to bind address");
let _ = tokio::spawn(server);
TestApp {
address,
db_pool: connection_pool,
}
}
概括来说,我们有以下几个阶段:
- 执行特定于测试的设置(例如,初始化跟踪订阅者);
- 随机化配置以确保测试不会相互干扰(例如,为每个测试用例使用不同的逻辑数据库);
- 初始化外部资源(例如,创建和迁移数据库!);
- 构建应用程序;
- 将应用程序作为后台任务启动,并返回一组与其交互的资源。
我们可以直接把构建过程放在那里就完事了吗?
当然不行,但让我们尝试看看它有哪些不足之处:
//! tests/api/helpers.rs
// [...]
pub async fn spawn_app() -> TestApp {
Lazy::force(&TRACING);
// Randomise configuration to ensure test isolation
let mut configuration = {
let mut c = get_configuration().expect("Failed to read configuration.");
c.database.database_name = Uuid::new_v4().to_string();
c.application_port = 0;
c
};
// Create and migrate the database
let connection_pool = configure_database(&configuration.database).await;
// Launch the application as a background task
let server = build(configuration).await.expect("Failed to build application.");
let _ = tokio::spawn(server);
TestApp {
// How do we get these?
address: todo!(),
db_pool: todo!()
}
}
它几乎成功了——但最终却出了问题: 我们无法检索操作系统分配给应用程序的随机地址,而且我们也不知道如何构建一个连接到数据库的连接池,而这个连接池需要对影响持久状态的副作用执行断言。
我们先来处理连接池: 我们可以将构建过程中的初始化逻辑提取到一个独立的函数中,并调用它两次。
//! src/startup.rs
// [...]
// We are taking a reference now!
pub async fn build(configuration: &Settings) -> Result<Server, std::io::Error> {
let connection_pool = get_connection_pool(&configuration.database);
// [...]
}
pub fn get_connection_pool(configuration: &DatabaseSettings) -> PgPool {
PgPoolOptions::new()
.acquire_timeout(std::time::Duration::from_secs(2))
.connect_lazy_with(configuration.with_db())
}
//! tests/api/helpers.rs
// [...]
pub async fn spawn_app() -> TestApp {
Lazy::force(&TRACING);
// Randomise configuration to ensure test isolation
let configuration = {
let mut c = get_configuration().expect("Failed to read configuration") ;
c.database.database_name = Uuid::new_v4().to_string();
c.application.port = 0;
c
};
// Create and migrate the database
configure_database(&configuration.database).await;
// Launch the application as a background task
let server = build(&configuration).await.expect("Failed to build application") ;
let _ = tokio::spawn(server);
TestApp {
address: todo!(),
db_pool: get_connection_pool(&configuration.database),
}
}
您必须在 src/configuration.rs 中的所有结构体中添加 #[derive(Clone)] 才能使编译器正常运行,但数据库连接池已经完成了。
我们如何获取应用程序地址呢?
actix_web::dev::Server 是 build 返回的类型,它不允许我们检索应用程序端口。
注: 你还需要将 SecretBox 修改为 SecretString 来满足 Clone trait 的要求, 使用 SecretString::from(String) 创建 SecretString
我们需要在您的应用程序代码中做一些准备工作——我们将把 actix web::dev::Server 包装成一个新的类型,以保存我们想要的信息。
//! src/startup.rs
// [...]
// A new type to hold the newly built server and its port
pub struct Application {
port: u16,
server: Server,
}
impl Application {
// We have converted the `build` function into a constructor for
// `Application`.
pub async fn build(configuration: Settings) -> Result<Self, std::io::Error> {
let connection_pool = get_connection_pool(&configuration.database);
let sender_email = configuration
.email_client
.sender()
.expect("Invalid sender email address.");
let email_client = EmailClient::new(
configuration.email_client.base_url,
sender_email,
configuration.email_client.authorization_token,
std::time::Duration::from_secs(10),
);
let address = format!(
"{}:{}",
configuration.application.host,
configuration.application.port
);
let listener = TcpListener::bind(&address)?;
let port = listener.local_addr()?.port();
let server = run(listener, connection_pool, email_client)?;
Ok(Self {
port,
server
})
}
pub fn port(&self) -> u16 {
self.port
}
// A more expressive name that makes it clear that
// this function only returns when the application is stopped.
pub async fn run_until_stopped(self) -> Result<(), std::io::Error> {
self.server.await
}
}
//! tests/api/helpers.rs
// [...]
// New import!
use zero2prod::startup::Application;
pub async fn spawn_app() -> TestApp {
Lazy::force(&TRACING);
// Randomise configuration to ensure test isolation
let configuration = {
let mut c = get_configuration().expect("Failed to read configuration") ;
c.database.database_name = Uuid::new_v4().to_string();
c.application.port = 0;
c
};
// Create and migrate the database
configure_database(&configuration.database).await;
let application = Application::build(configuration.clone())
.await
.expect("Failed to build application.");
// Get the port before spawning the application
let address = format!("http://127.0.0.1:{}", application.port());
let _ = tokio::spawn(application.run_until_stopped());
TestApp {
address,
db_pool: get_connection_pool(&configuration.database),
}
}
//! src/main.rs
// New import!
use zero2prod::startup::Application;
async fn main() -> std::io::Result<()> {
// [...]
let application = Application::build(configuration).await?;
application.run_until_stopped().await?;
Ok(())
}
完成了 - 如果您想再次检查,请运行 cargo test !
构建一个 API 客户端
我们所有的集成测试都是黑盒测试:我们在每个测试开始时启动应用程序,并使用 HTTP 客户端 (例如 reqwest) 与其交互。
在编写测试时,我们最终必然会为 API 实现一个客户端。
这太棒了!
这给了我们一个绝佳的机会来体验作为用户与 API 交互的感觉。
我们只需要注意不要将客户端逻辑分散到整个测试套件中——当 API 发生变化时,我们不想为了从端点路径中删除一个尾随的 s 而进行数十次测试。
让我们来看看我们的订阅测试:
//! tests/api/subscriptions.rs
use crate::helpers::spawn_app;
#[tokio::test]
async fn subscribe_returns_a_200_for_valid_form_data() {
// Arrange
let app = spawn_app().await;
let app_address = app.address.as_str();
let client = reqwest::Client::new();
// Act
let body = "name=le%20guin&email=ursula_le_guin%40gmail.com";
let response = client
.post(&format!("{}/subscriptions", &app_address))
.header("Content-Type", "application/x-www-form-urlencoded")
.body(body)
.send()
.await
.expect("Failed to execute request.");
// Assert
assert_eq!(200, response.status().as_u16());
let saved = sqlx::query!("SELECT email, name FROM subscriptions",)
.fetch_one(&app.db_pool)
.await
.expect("Failed to fetch saved subscription.");
assert_eq!(saved.email, "ursula_le_guin@gmail.com");
assert_eq!(saved.name, "le guin");
}
#[tokio::test]
async fn subscribe_returns_a_400_when_data_is_missing() {
// Arrange
let app = spawn_app().await;
let app_address = app.address.as_str();
let client = reqwest::Client::new();
let test_cases = vec![
("name=le%20guin", "missing the email"),
("email=ursula_le_guin%40gmail.com", "missing the name"),
("", "missing both name and email"),
];
for (invalid_body, error_message) in test_cases {
// Act
let response = client
.post(&format!("{}/subscriptions", &app_address))
.header("Content-Type", "application/x-www-form-urlencoded")
.body(invalid_body)
.send()
.await
.expect("Failed to execute request.");
// Assert
assert_eq!(
400,
response.status().as_u16(),
// Additional customised error message on test failure
"The API did not fail with 400 Bad Request when the payload was {}.",
error_message
);
}
}
#[tokio::test]
async fn subscribe_returns_a_200_when_fields_are_present_but_invalid() {
// Arrange
let app = spawn_app().await;
let client = reqwest::Client::new();
let test_cases = vec![
("name=&email=ursula_le_guin%40gmail.com", "empty name"),
("name=Ursula&email=", "empty email"),
("name=Ursula&email=definitely-not-an-email", "invalid email"),
];
for (body, description) in test_cases {
// Act
let response = client
.post(&format!("{}/subscriptions", &app.address))
.header("Content-Type", "application/x-www-form-urlencoded")
.body(body)
.send()
.await
.expect("Failed to execute request.");
// Assert
assert_eq!(
400,
response.status().as_u16(),
"The API did not return a 400 OK when the payload was {}.",
description
);
}
}
每个测试中都有相同的调用代码——我们应该将其提取出来,并向 TestApp 结构体中添加一个辅助方法:
//! tests/api/helpers.rs
// [...]
pub struct TestApp {
// [...]
}
impl TestApp {
pub async fn post_subscriptions(&self, body: String) -> reqwest::Response {
reqwest::Client::new()
.post(&format!("{}/subscriptions", &self.address))
.header("Content-Type", "application/x-www-form-urlencoded")
.body(body)
.send()
.await
.expect("Failed to execute request.")
}
}
//! tests/api/subscriptions.rs
use crate::helpers::spawn_app;
#[tokio::test]
async fn subscribe_returns_a_200_for_valid_form_data() {
// Arrange
// [...]
let response = app.post_subscriptions(body.into()).await;
// Assert
// [...]
}
#[tokio::test]
async fn subscribe_returns_a_400_when_data_is_missing() {
// Arrange
// [...]
for (invalid_body, error_message) in test_cases {
// Act
let response = app.post_subscriptions(invalid_body.into()).await;
// Assert
// [...]
}
}
#[tokio::test]
async fn subscribe_returns_a_200_when_fields_are_present_but_invalid() {
// Arrange
// [...]
for (body, description) in test_cases {
// Act
let response = app.post_subscriptions(body.into()).await;
// Assert
// [...]
}
}
我们可以为健康检查端点添加另一个方法,但它只会使用一次——目前没有必要。
小结
我们最初开发了一个单文件测试套件,最终构建了一个模块化测试套件和一套强大的辅助工具。
就像应用程序代码一样,测试代码也永无止境: 随着项目的发展,我们必须持续改进,但我们已经奠定了坚实的基础,能够持续前进,不失去动力。
现在,我们已准备好处理发送确认电子邮件所需的剩余功能。
短暂回顾
现在是时候回到我们在本章开头起草的计划了;
- 编写一个模块来发送电子邮件
- 调整现有 POST /subscriptions 请求处理程序的逻辑以适应新的需求
- 从头编写一个 GET /subscriptions/confirm 请求处理程序
第一项已完成,接下来该处理剩下的两项了。
我们之前已经画好了这两个处理程序的工作原理图:
POST /subscriptions 将:
- • 将订阅者详细信息添加到数据库的 subscriptions 表中,状态等于 pending_confirmation
- • 生成一个(唯一的)subscription_token
- • 将 subscription_token 存储在数据库中,并与 subscription_tokens 表中的订阅者 ID 对应
- • 向新订阅者发送一封电子邮件,其中包含结构为
https://<our-api-domain>/subscriptions/confirm?token=<subscription_token>的链接 - • 返回 200 OK
一旦订阅者点击该链接,浏览器标签页将打开,并向我们的 GET /subscriptions/confirm 端点发送 GET 请求。请求处理程序将:
- 从查询参数中检索 subscription_token
- 从 subscription_tokens 表中检索与 subscription_token 关联的订阅者 ID
- 在 subscriptions 表中将订阅者状态从 pending_confirmation 更新为 active
- 返回 200 OK
这让我们对应用程序在实现完成后的工作方式有了相当精确的了解。
但这对我们弄清楚如何实现目标并没有多大帮助。
我们应该从哪里开始?
我们应该立即处理 /subscriptions 的变更吗?
我们应该先处理 /subscriptions/confirm 吗?
我们需要找到一条可以零停机时间上线的实现路线。
零停机部署
可靠性
在第五章中,我们将应用程序部署到了一家公有云提供商。
它已经上线:我们目前还不会发送新闻简报,但用户可以在我们解决这个问题的同时订阅。
一旦应用程序开始服务于生产流量,我们就需要确保它的可靠性。
“可靠性”在不同的语境下有不同的含义。例如,如果您销售的是数据存储解决方案,它就不应该丢失(或损坏!)客户的数据。
在商业环境中,应用程序的可靠性定义通常会被编码在服务水平协议 (SLA) 中。
SLA 是一项合同义务:您保证一定的可靠性,并承诺在服务未能达到预期时向客户进行补偿(通常以折扣或积分的形式)。
例如,如果您销售的是 API 访问权限,通常会包含一些与可用性相关的内容,例如API 应该能够成功响应至少 99.99% 的格式正确的传入请求,这通常被称为“四个九的可用性”。
换句话说(假设传入请求随时间均匀分布),您一年内最多只能承受 52 分钟的停机时间。实现四个九的可用性非常困难。 构建高可用性解决方案没有灵丹妙药:它需要从应用层一直到基础设施层的努力。
但有一点是肯定的:如果您想要运营高可用性服务,您应该掌握 零停机部署——用户应该能够在新版本应用程序部署到生产环境之前、期间和之后使用该服务。
如果您正在实施持续部署,这一点就更为重要: 您不能每天发布多次,因为每次发布都会触发一次小规模的中断。
部署策略
简单部署
在深入探讨零停机部署之前,我们先来看看“简单”的方法。 我们服务的 A 版本正在生产环境中运行,现在我们想要推出 B 版本:
- 我们关闭集群中所有 A 版本的实例
- 我们启动运行 B 版本的应用程序的新实例
- 我们开始使用 B 版本处理流量
集群中没有应用程序可以处理用户流量,这种情况持续一段时间——我们正经历停机!
为了做得更好,我们需要仔细研究我们的基础设施是如何设置的。
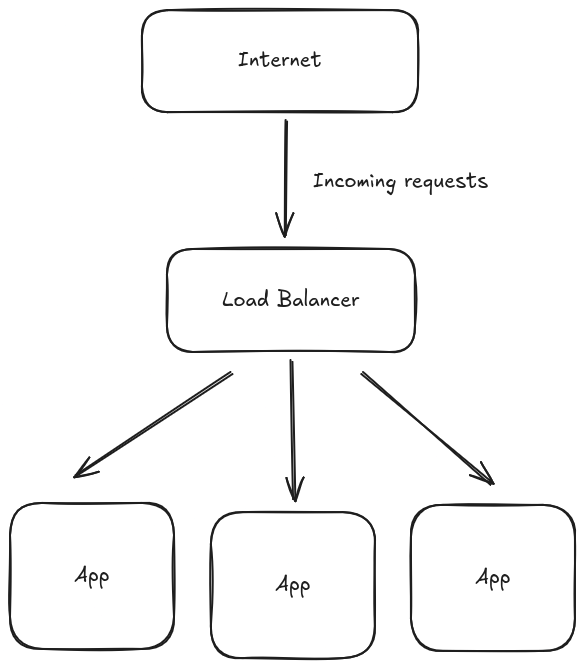
Load Balancers
我们的应用程序在负载均衡器后运行多个副本。
每个应用程序副本都作为后端注册到负载均衡器。
每当有人向我们的 API 发送请求时,都会访问我们的负载均衡器,然后负载均衡器负责选择一个可用的后端来处理传入的请求。
负载均衡器通常支持动态添加(和删除)后端。
这实现了一些有趣的模式。
水平扩展
当流量激增时,我们可以通过启动更多应用程序副本(即水平扩展)来增加容量。
这有助于分散负载,直到单个实例的预期工作量变得可控。
我们将在本书后面讨论指标和自动扩展时再次讨论这个主题。
可用性检测
我们可以让负载均衡器密切关注已注册后端的健康状况。
简单来说,健康检查可以分为:
- 被动 - 负载均衡器查看每个后端的状态码/延迟分布,以确定它们是否健康
- 主动 - 负载均衡器配置为按计划向每个后端发送健康检查请求。如果后端在足够长的时间内未能返回成功状态码,则会被标记为不健康并被移除
这是在云原生环境中实现自我修复的关键功能: 平台可以检测应用程序是否运行异常,并自动将其从可用后端列表中移除,以减轻或消除对用户的影响。
滚动更新部署
我们可以利用负载均衡器来执行零停机部署。
我们首先启动应用程序 B 版本的一个副本。
当应用程序准备好处理流量时(例如,一些健康检查请求已成功),我们将其注册为负载均衡器的后端。
我们现在有四个应用程序副本:3 个运行版本 A,1 个运行版本 B。这四个副本都在提供实时流量。
如果一切正常,我们会关闭其中一个运行版本 A 的副本。
我们遵循相同的流程替换所有运行版本 A 的副本,直到所有注册的后端都运行版本 B。
这种部署策略称为滚动更新:我们同时运行应用程序的新旧版本,并同时使用它们来处理实时流量。
在整个过程中,我们始终拥有三个或更多健康的后端:用户应该不会遇到任何服务降级(假设版本 B 没有错误)。
Digital Ocean App Platform
我们的应用程序运行在 Digital Ocean 应用平台上。 他们的文档宣称提供开箱即用的零停机部署,但却没有提供实现细节。
一些实验证实,他们确实依赖于滚动更新部署策略。
滚动更新并非实现零停机部署的唯一策略——蓝绿部署和金丝雀部署也是基于相同底层原则的流行变体。
请根据您的平台提供的功能和需求,为您的应用程序选择最合适的解决方案。
译者注: 另外一个可能的方案是 Kubernetes.
数据库迁移
状态保存在应用程序之外
负载均衡依赖于一个强有力的假设: 无论使用哪个后端来处理传入的请求,结果都是相同的。
我们在第 3 章中已经讨论过这一点: 为了确保在易出错的环境中实现高可用性,云原生应用程序是无状态的——它们将所有持久化问题委托给外部系统(例如数据库)。
这就是负载均衡有效的原因: 所有后端都与同一个数据库通信,以查询和操作相同的状态。
可以将数据库视为一个巨大的全局变量。我们应用程序的所有副本都会持续访问和修改它。
状态是很难把握的。
部署和迁移
在滚动更新部署期间,应用程序的新旧版本同时处理实时流量。 从另一个角度来看:应用程序的新旧版本同时使用同一个数据库。
为了避免停机,我们需要一个两个版本都能理解的数据库模式。 这对于我们的大多数部署来说都不是问题,但当我们需要改进数据库模式时,就会造成严重的制约。
让我们回到我们最初要做的工作:确认邮件。
为了推进我们确定的实施策略,我们需要按如下方式改进数据库模式:
- 添加一个新表 subscription_tokens;
- 在现有的 subscriptions 表中添加一个新的必填列 status。
让我们回顾一下可能的情况,以便确信我们不可能一次性部署所有确认邮件而不会导致停机。
我们可以先迁移数据库,然后再部署新版本。
这意味着当前版本需要在迁移后的数据库上运行一段时间:我们当前的 POST /subscriptions 实现无法获取 status 字段,它会尝试在未填充 status 字段的情况下向 subscriptions 中插入新行。由于 status 字段被限制为 NOT NULL(即强制),所有插入操作都会失败——在新版本应用程序部署完成之前,我们将无法接受新的订阅者。
这很糟糕。
我们可以先部署新版本,然后再迁移数据库。
结果却截然相反:新版本的应用程序正在旧数据库架构上运行。
当调用 POST /subscriptions 时,它会尝试向 subscriptions 中插入一行 status 字段不存在的行——所有插入操作都会失败,在数据库迁移完成之前,我们将无法接受新的订阅者。
这又一次很糟糕。
多步骤迁移
一次大范围的发布并不能解决问题——我们需要分阶段、分步骤地实现目标。
这种模式与我们在测试驱动开发中看到的有些相似:我们不会同时修改代码和测试——两者中需要有一个保持不变,而另一个则进行修改。
这同样适用于数据库迁移和部署:如果我们想要改进数据库架构,就不能同时更改应用程序的行为。
可以将其视为数据库重构:我们奠定基础是为了构建我们以后需要的行为。
新的必填 Column
让我们首先查看 status column。
第一步: 添加为可选
我们首先要确保应用程序代码稳定。
在数据库端,我们生成一个新的迁移脚本:
sqlx migrate add add_status_to_subscriptions
Creating migrations/20250828120711_add_status_to_subscriptions.sql
我们现在可以编辑迁移脚本,将状态作为可选列添加到订阅中:
ALTER TABLE subscriptions ADD COLUMN status TEXT NULL;
针对本地数据库运行迁移 (SKIP_DOCKER=true ./scripts/init_db.sh): 现在我们可以运行测试套件,以确保代码即使在新的数据库架构下也能正常工作。
测试应该会通过: 继续迁移生产数据库。
步骤 2:开始使用新 Column
状态现已存在: 我们可以开始使用它了!
确切地说,我们可以开始写入状态:每次插入新订阅者时,我们都会将状态设置为已确认。
我们只需要将插入查询从
//! src/routes/subscriptions.rs
// [...]
pub async fn insert_subscriber(pool: &PgPool, new_subscriber: &NewSubscriber) -> Result<(), sqlx::Error> {
sqlx::query!(
r#"
INSERT INTO subscriptions (id, email, name, subscribed_at)
VALUES ($1, $2, $3, $4)
"#,
// [...]
)
// [...]
}
改为
pub async fn insert_subscriber(pool: &PgPool, new_subscriber: &NewSubscriber) -> Result<(), sqlx::Error> {
sqlx::query!(
r#"
INSERT INTO subscriptions (id, email, name, subscribed_at, status)
VALUES ($1, $2, $3, $4, 'confirmed')
"#,
// [...]
)
// [...]
}
测试应该通过 - 将新版本的应用程序部署到生产中。
第三步: 回填并标记为 NOT NULL
最新版本的应用程序确保所有新订阅者的状态信息都会被填充。
为了将状态标记为“非空”,我们只需回填历史记录的值即可:然后我们就可以随意修改该列了。
让我们生成一个新的迁移脚本:
sqlx migrate add make_status_not_null_in_subscriptions
SQL 迁移应该看起来是这样的
-- We wrap the whole migration in a transaction to make sure
-- it succeeds or fails atomically. We will discuss SQL transactions
-- in more details towards the end of this chapter!
-- `sqlx` does not do it automatically for us.
BEGIN;
-- Backfill `status` for historical entries
UPDATE subscriptions
SET status = 'confirmed'
WHERE status IS NULL;
-- Make `status` mandatory
ALTER TABLE subscriptions ALTER COLUMN status SET NOT NULL;
COMMIT;
我们可以迁移本地数据库,运行测试套件,然后部署生产数据库。
我们成功了,我们将 status 添加为新的必填列!
一个新表
那么 subscription_tokens 呢? 我们也需要三个步骤吗?
不,其实简单得多:我们在迁移中添加新表,但应用程序会一直忽略它。
然后,我们可以部署一个新版本的应用程序,并使用它启用确认电子邮件。
让我们生成一个新的迁移脚本:
sqlx migrate add create_subscription_tokens_table
Creating migrations/20250828122145_create_subscription_tokens_table.sql
这次迁移与我们为添加 subscriptions 而编写的第一个迁移类似:
-- Create Subscription Tokens Table
CREATE TABLE subscription_tokens(
subscription_token TEXT NOT NULL,
subscriber_id uuid NOT NULL
REFERENCES subscriptions (id),
PRIMARY KEY (subscription_token)
);
请注意这里的细节: subscription_tokens 中的subscriber_id 列是外键。
subscription_tokens 中的每一行都必须在subscriptions 中存在一行,其id字段的值与subscriber_id 相同,否则插入操作会失败。这可以保证所有令牌都附加到合法的订阅者。
再次迁移生产数据库 - 大功告成!
发送确认邮件
虽然花了一段时间,但基础工作已经完成:我们的生产数据库已经准备好支持我们想要构建的新功能——确认邮件。
现在该专注于应用程序代码了。
我们将以适当的测试驱动方式构建整个功能: 在紧密的“红-绿-重构”循环中,循序渐进地推进。
做好准备!
静态电子邮件
我们将从简单的开始:测试 POST /subscriptions 是否正在发送电子邮件。
在此阶段,我们不会查看电子邮件的正文,特别是,我们不会检查其中是否包含确认链接。
静态电子邮件 - Red 测试
要编写此测试,我们需要增强 TestApp。
它目前包含我们的应用程序以及数据库连接池的句柄:
//! tests/api/helpers.rs
// [...]
pub struct TestApp {
pub address: String,
pub db_pool: PgPool,
}
我们需要启动一个模拟服务器来代替 Postmark 的 API 并拦截外发请求,就像我们构建电子邮件客户端时所做的那样。
让我们相应地编辑 spawn_app :
//! tests/api/helpers.rs
pub struct TestApp {
pub address: String,
pub db_pool: PgPool,
// New field!
pub email_server: MockServer,
}
pub async fn spawn_app() -> TestApp {
// [...]
// Launch a mock server to stand in for Postmark's API
let email_server = MockServer::start().await;
// Randomise configuration to ensure test isolation
let configuration = {
let mut c = get_configuration().expect("Failed to read configuration") ;
c.database.database_name = Uuid::new_v4().to_string();
c.application.port = 0;
c.email_client.base_url = email_server.uri();
c
};
// [...]
TestApp {
address,
db_pool: get_connection_pool(&configuration.database),
email_server
}
}
现在我们可以编写新的测试用例:
//! tests/api/subscriptions.rs
// New imports
use wiremock::matchers::{method, path};
use wiremock::{Mock, ResponseTemplate};
#[tokio::test]
async fn subscribe_sends_a_confirmation_email_for_valid_data() {
// Arrange
let app = spawn_app().await;
let body = "name=le%20guin&email=ursula_le_guin%40gmail.com";
Mock::given(path("/email"))
.and(method("POST"))
.respond_with(ResponseTemplate::new(200))
.expect(1)
.mount(&app.email_server)
.await;
// Act
app.post_subscriptions(body.into()).await;
// Assert
// Mock asserts on drop
}
正如预期的那样,测试失败:
failures:
---- subscriptions::subscribe_sends_a_confirmation_email_for_valid_data stdout -
---
thread 'subscriptions::subscribe_sends_a_confirmation_email_for_valid_data' pani
cked at /home/cubewhy/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/wirem
ock-0.6.5/src/mock_server/exposed_server.rs:367:17:
Verifications failed:
- Mock #0.
Expected range of matching incoming requests: == 1
Number of matched incoming requests: 0
The server did not receive any request.
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
请注意,如果发生故障, wiremock 会提供详细的故障原因分析:我们预期会收到一个请求,但实际上什么也没收到。
让我们来解决这个问题。
静态电子邮件 - Green 测试
我们的处理程序现在看起来像这样:
//! src/routes/subscriptions.rs
// [...]
#[tracing::instrument(/*[...]*/)]
pub async fn subscribe(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
let new_subscriber = match form.into_inner().try_into() {
Ok(subscriber) => subscriber,
Err(_) => return HttpResponse::BadRequest().finish(),
};
match insert_subscriber(&pool, &new_subscriber).await {
Ok(_) => HttpResponse::Ok().finish(),
Err(_) => HttpResponse::InternalServerError().finish(),
}
}
要发送电子邮件,我们需要获取 EmailClient 的实例。
作为编写模块时所做的工作之一,我们还将其注册到了应用程序上下文中:
//! src/startup.rs
// [...]
pub fn run(
listener: TcpListener,
db_pool: PgPool,
email_client: EmailClient,
) -> Result<Server, std::io::Error> {
// [...]
let server = HttpServer::new(move || {
App::new()
// Middlewares are added using the `wrap` method on `App`
.wrap(TracingLogger::default())
// [...]
// here!
.app_data(email_client.clone())
})
.listen(listener)?
.run();
Ok(server)
}
因此,我们可以使用 web::Data 在我们的处理程序中访问它,就像我们对 pool 所做的那样:
//! src/routes/subscriptions.rs
// New import!
use crate::email_client::EmailClient;
// [...]
#[tracing::instrument(
name = "Adding a new subscriber",
skip(form, pool, email_client),
fields(
subscriber_email = %form.email,
subscriber_name = %form.name,
)
)]
pub async fn subscribe(
form: web::Form<FormData>,
pool: web::Data<PgPool>,
// Get the email client from the app context
email_client: web::Data<EmailClient>,
) -> HttpResponse {
let new_subscriber = match form.into_inner().try_into() {
Ok(subscriber) => subscriber,
Err(_) => return HttpResponse::BadRequest().finish(),
};
if insert_subscriber(&pool, &new_subscriber).await.is_err() {
return HttpResponse::InternalServerError().finish();
}
// Send a (useless) email to the new subscriber
// We are ignoring email delivery errors for now.
if email_client
.send_email(
new_subscriber.email,
"Welcome",
"Welcome to our newsletter!",
"Welcome to our newsletter!",
)
.await
.is_err()
{
return HttpResponse::InternalServerError().finish();
}
HttpResponse::Ok().finish()
}
subscribe_sends_a_confirmation_email_for_valid_data 现已通过,但 subscribe_returns_a_200_for_valid_f 失败:
thread 'subscriptions::subscribe_returns_a_200_for_valid_form_data' panicked at tests/api/subscriptions.rs:15:5:
assertion `left == right` failed
left: 200
right: 500
它正在尝试发送电子邮件,但由于我们没有在该测试中设置模拟,因此失败了。让我们修复它:
//! tests/api/subscriptions.rs
// [...]
async fn subscribe_returns_a_200_for_valid_form_data() {
// Arrange
let app = spawn_app().await;
let body = "name=le%20guin&email=ursula_le_guin%40gmail.com";
// New section!
Mock::given(path("/email"))
.and(method("POST"))
.respond_with(ResponseTemplate::new(200))
.mount(&app.email_server)
.await;
// Act
let response = app.post_subscriptions(body.into()).await;
// Assert
assert_eq!(200, response.status().as_u16());
// [...]
}
一切顺利,测试通过了。
目前没有太多需要重构的地方,我们继续吧。
静态确认链接
让我们稍微提高一点标准 --我们将扫描电子邮件的正文以检索确认链接。
静态确认链接 - Red 测试
我们(目前)并不关心链接是动态的还是实际有意义的——我们 只想确保正文中有一些看起来像链接的内容。
我们还应该在纯文本和 HTML 版本的邮件正文中使用相同的链接。
如何获取 wiremock::MockServer 拦截的请求正文?
我们可以使用它的 received_requests 方法——只要启用了请求记录(默认设置),它就会返回一个包含服务器拦截的所有请求的向量。
//! tests/api/subscriptions.rs
// [...]
#[tokio::test]
async fn subscribe_sends_a_confirmation_email_with_a_link() {
// Arrange
let app = spawn_app().await;
let body = "name=le%20guin&email=ursula_le_guin%40gmail.com";
Mock::given(path("/email"))
.and(method("POST"))
.respond_with(ResponseTemplate::new(200))
// We are not setting an expectation here anymore
// The test is focused on another aspect of the app
// behaviour.
.mount(&app.email_server)
.await;
// Act
app.post_subscriptions(body.into()).await;
// Assert
// Get the first intercepted request
let email_request = &app.email_server.received_requests().await.unwrap()[0];
// Parse the body as JSON, start from raw bytes
let body: serde_json::Value = serde_json::from_slice(&email_request.body).unwrap();
}
现在我们需要从中提取链接。
最明显的方法是使用正则表达式。不过,我们必须面对现实:正则表达式本身就很复杂,而且需要一段时间才能正确使用。
再次,我们可以利用 Rust 生态系统的成果——让我们将 linkify 添加为开发依赖项:
cargo add linkify --dev
我们可以使用 linkify 扫描文本并返回提取的链接的迭代器。
//! tests/api/subscriptions.rs
// [...]
async fn subscribe_sends_a_confirmation_email_with_a_link() {
// [...]
let body: serde_json::Value = serde_json::from_slice(&email_request.body).unwrap();
// Extract the link from one of the request fields.
let get_link = |s: &str| {
let links: Vec<_> = linkify::LinkFinder::new()
.links(s)
.filter(|l| *l.kind() == linkify::LinkKind::Url)
.collect();
assert_eq!(links.len(), 1);
links[0].as_str().to_owned()
};
let html_link = get_link(&body["HtmlBody"].as_str().unwrap());
let text_link = get_link(&body["TextBody"].as_str().unwrap());
// The two links should be identical
assert_eq!(html_link, text_link);
}
如果我们运行测试套件,我们应该看到新的测试用例失败:
thread 'subscriptions::subscribe_sends_a_confirmation_email_with_a_link' panicke
d at tests/api/subscriptions.rs:133:9:
assertion `left == right` failed
left: 0
right: 1
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
静态确认链接 - Green 测试
我们需要再次调整请求处理程序以满足新的测试用例:
//! src/route/subscriptions.rs
// [...]
pub async fn subscribe(
form: web::Form<FormData>,
pool: web::Data<PgPool>,
// Get the email client from the app context
email_client: web::Data<EmailClient>,
) -> HttpResponse {
// [...]
let confirmation_link = "https://my-api.com/subscriptions/confirm";
// Send a (useless) email to the new subscriber
// We are ignoring email delivery errors for now.
if email_client
.send_email(
new_subscriber.email,
"Welcome",
&format!("Welcome to our newsletter!<br />\
Click <a href=\"{confirmation_link}\">here</a> to confirm your subscription."),
&format!("Welcome to our newsletter!\nVisit {confirmation_link} to confirm your subscription."),
)
.await
.is_err()
{
return HttpResponse::InternalServerError().finish();
}
HttpResponse::Ok().finish()
}
测试应该立即通过。
静态确认链接 - 重构
我们的请求处理程序有点忙——现在有很多代码在处理我们的确认电子邮件。
让我们将其提取到一个单独的函数中:
//! src/routes/subscriptions.rs
// [...]
#[tracing::instrument(/*[...]*/)]
pub async fn subscribe(
form: web::Form<FormData>,
pool: web::Data<PgPool>,
// Get the email client from the app context
email_client: web::Data<EmailClient>,
) -> HttpResponse {
let new_subscriber = match form.into_inner().try_into() {
Ok(subscriber) => subscriber,
Err(_) => return HttpResponse::BadRequest().finish(),
};
if insert_subscriber(&pool, &new_subscriber).await.is_err() {
return HttpResponse::InternalServerError().finish();
}
if send_confirmation_email(&email_client, new_subscriber)
.await
.is_err()
{
return HttpResponse::InternalServerError().finish();
}
HttpResponse::Ok().finish()
}
#[tracing::instrument(
name = "Send a confirmation email to a new subscriber",
skip(email_client, new_subscriber)
)]
pub async fn send_confirmation_email(
email_client: &EmailClient,
new_subscriber: NewSubscriber,
) -> Result<(), reqwest::Error> {
let confirmation_link = "https://my-api.com/subscriptions/confirm";
let html_body = format!(
"Welcome to our newsletter!<br />\
Click <a href=\"{confirmation_link}\">here</a> to confirm your subscription."
);
let plain_body = format!(
"Welcome to our newsletter!\nVisit {confirmation_link} to confirm your subscription."
);
email_client
.send_email(new_subscriber.email, "Welcome", &html_body, &plain_body)
.await
}
subscribe 再次关注整体流程,而不必担心任何步骤的细节。
待确认
现在让我们来看看新订阅者的状态。
我们目前在 POST /subscriptions 中将其状态设置为“已确认”,但在他们点击确认链接之前,它应该是“待确认”。
是时候修复这个问题了。
待确认 - Red 测试
我们可以先重新看一下我们的第一个“快乐路径”测试:
//! tests/api/subscriptions.rs
// [...]
#[tokio::test]
async fn subscribe_returns_a_200_for_valid_form_data() {
// Arrange
let app = spawn_app().await;
let body = "name=le%20guin&email=ursula_le_guin%40gmail.com";
// New section!
Mock::given(path("/email"))
.and(method("POST"))
.respond_with(ResponseTemplate::new(200))
.mount(&app.email_server)
.await;
// Act
let response = app.post_subscriptions(body.into()).await;
// Assert
assert_eq!(200, response.status().as_u16());
let saved = sqlx::query!("SELECT email, name FROM subscriptions",)
.fetch_one(&app.db_pool)
.await
.expect("Failed to fetch saved subscription.");
assert_eq!(saved.email, "ursula_le_guin@gmail.com");
assert_eq!(saved.name, "le guin");
}
这个名字有点夸张——它的作用是检查状态码,并根据数据库中存储的状态执行一些断言。
让我们把它拆分成两个独立的测试用例:
//! tests/api/subscriptions.rs
// [...]
#[tokio::test]
async fn subscribe_returns_a_200_for_valid_form_data() {
// Arrange
let app = spawn_app().await;
let body = "name=le%20guin&email=ursula_le_guin%40gmail.com";
// New section!
Mock::given(path("/email"))
.and(method("POST"))
.respond_with(ResponseTemplate::new(200))
.mount(&app.email_server)
.await;
// Act
let response = app.post_subscriptions(body.into()).await;
// Assert
assert_eq!(200, response.status().as_u16());
}
#[tokio::test]
async fn subscribe_persists_the_new_subscriber() {
// Arrange
let app = spawn_app().await;
let body = "name=le%20guin&email=ursula_le_guin%40gmail.com";
// New section!
Mock::given(path("/email"))
.and(method("POST"))
.respond_with(ResponseTemplate::new(200))
.mount(&app.email_server)
.await;
// Act
app.post_subscriptions(body.into()).await;
// Assert
let saved = sqlx::query!("SELECT email, name FROM subscriptions",)
.fetch_one(&app.db_pool)
.await
.expect("Failed to fetch saved subscription.");
assert_eq!(saved.email, "ursula_le_guin@gmail.com");
assert_eq!(saved.name, "le guin");
}
我们现在可以修改第二个测试用例来检查状态。
//! tests/api/subscriptions.rs
// [...]
#[tokio::test]
async fn subscribe_persists_the_new_subscriber() {
// [...]
// Assert
let saved = sqlx::query!("SELECT email, name, status FROM subscriptions",)
.fetch_one(&app.db_pool)
.await
.expect("Failed to fetch saved subscription.");
assert_eq!(saved.email, "ursula_le_guin@gmail.com");
assert_eq!(saved.name, "le guin");
assert_eq!(saved.status, "pending_confirmation");
}
注: 如果你找不到 status 字段, 请仔细检查 query! 语句中输入的查询语句是否与示例中的相同。
测试如预期失败:
thread 'subscriptions::subscribe_persists_the_new_subscriber' panicked at tests/api/subscriptions.rs:52:5:
assertion `left == right` failed
left: "confirmed"
right: "pending_confirmation"
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
待确认 - Green 测试
我们可以通过再次通过插入查询将其变为绿色:
//! src/routes/subscriptions.rs
// [...]
pub async fn insert_subscriber(
pool: &PgPool,
new_subscriber: &NewSubscriber,
) -> Result<(), sqlx::Error> {
sqlx::query!(
r#"
INSERT INTO subscriptions (id, email, name, subscribed_at, status)
VALUES ($1, $2, $3, $4, 'confirmed')
"#,
// [...]
)
// [...]
}
我们需要将 confirmed 修改为 pending_confirmation
//! src/routes/subscriptions.rs
pub async fn insert_subscriber(
pool: &PgPool,
new_subscriber: &NewSubscriber,
) -> Result<(), sqlx::Error> {
sqlx::query!(
r#"
INSERT INTO subscriptions (id, email, name, subscribed_at, status)
VALUES ($1, $2, $3, $4, 'pending_confirmation')
"#,
Uuid::new_v4(),
new_subscriber.email.as_ref(),
new_subscriber.name.as_ref(),
Utc::now()
)
// [...]
}
现在测试应该通过了
GET /subscriptions/confirm 的骨架
我们已经完成了 POST /subscriptions 的大部分基础工作——是时候将注意力转移到旅程的另一半,GET /subscriptions/confirm。
我们想要构建端点的框架——我们需要在 src/startup.rs 中注册针对路径的处理程序,并拒绝没有必需查询参数 (subscription_token) 的传入请求。
这将使我们能够构建令人满意的路径,而无需一次性编写大量代码——循序渐进!
confirm 的骨架 - Red 测试
让我们在测试项目中添加一个新模块,用于托管所有处理确认回调的测试用例。
//! tests/api/main.rs
// [...]
mod subscriptions_confirm;
//! tests/api/subscriptions_confirm.rs
use crate::helpers::spawn_app;
#[tokio::test]
async fn confirmations_without_token_are_rejected_with_a_400() {
// Arrange
let app = spawn_app().await;
// Act
let response = reqwest::get(&format!("{}/subscriptions/confirm", app.address))
.await
.unwrap();
// Assert
assert_eq!(response.status().as_u16(), 400);
}
由于我们还没有处理程序,因此正如预期的那样失败了:
thread 'subscriptions_confirm::confirmations_without_token_are_rejected_with_a_400' panicked at tests/api/subscriptions_confirm.rs:14:5:
assertion `left == right` failed
left: 404
right: 400
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
confirm 的骨架 - Green 测试
让我们从一个虚拟处理程序开始,无论传入的请求是什么,它都会返回 200 OK:
//! src/routes.rs
// [...]
mod subscriptions_confirm;
pub use subscriptions_confirm::*;
//! src/routes/subscriptions_confirm.rs
use actix_web::HttpResponse;
#[tracing::instrument(
name = "Confirm a pending subscriber"
)]
pub async fn confirm() -> HttpResponse {
HttpResponse::Ok().finish()
}
//! src/startup.rs
// [...]
use crate::routes::confirm;
pub fn run(
listener: TcpListener,
db_pool: PgPool,
email_client: EmailClient,
) -> Result<Server, std::io::Error> {
// [...]
let server = HttpServer::new(move || {
App::new()
// [...]
.route("/subscriptions/confirm", web::get().to(confirm))
.app_data(db_pool.clone())
// [...]
})
// [...]
}
现在运行 cargo test 时我们应该会得到不同的错误:
thread 'subscriptions_confirm::confirmations_without_token_are_rejected_with_a_400' panicked at tests/api/subscriptions_confirm.rs:14:5:
assertion `left == right` failed
left: 200
right: 400
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
成功了!
是时候把 200 OK 变成 400 Bad Request 了。
我们要确保有一个 subscription_token 查询参数:我们可以依赖另一个
actix-web 的提取器——Query。
//! src/routes/subscriptions_confirm.rs
use actix_web::{web, HttpResponse};
#[derive(serde::Deserialize)]
pub struct Parameters {
subscription_token: String,
}
#[tracing::instrument(
name = "Confirm a pending subscriber",
skip(_parameters)
)]
pub async fn confirm(_parameters: web::Query<Parameters>) -> HttpResponse {
HttpResponse::Ok().finish()
}
参数结构体定义了我们期望在传入请求中看到的所有查询参数。
它需要实现 serde::Deserialize 接口,以便 actix-web 能够根据传入的请求路径构建它。只需添加一个 web::Query<Parameter> 类型的函数参数来确认,指示 actix-web 仅在提取成功时调用处理程序。如果提取失败,则会自动向调用者返回 400 Bad Request 错误。
我们的测试现在应该可以通过了。
连接到点
现在我们有了 GET /subscriptions/confirm 处理程序,我们可以尝试执行完整的旅程!
连接到点 - Red 测试
我们将像用户一样操作:我们将调用 POST /subscriptions 方法,从发出的电子邮件请求中提取
确认链接(使用我们已经构建的 linkify 机制),然后调用该方法确认订阅,并期望返回 200 OK。
我们暂时不会从数据库中检查状态,因为这将是我们最后的收尾工作。
我们来记录一下:
//! tests/api/subscriptions_confirm.rs
// [...]
use reqwest::Url;
use wiremock::{matchers::{method, path}, Mock, ResponseTemplate};
#[tokio::test]
async fn the_link_returned_by_subscribe_returns_a_200_if_called() {
// Arrange
let app = spawn_app().await;
let body = "name=le%20guin&email=ursula_le_guin%40gmail.com";
Mock::given(path("/email"))
.and(method("POST"))
.respond_with(ResponseTemplate::new(200))
.mount(&app.email_server)
.await;
app.post_subscriptions(body.into()).await;
let email_request = &app.email_server.received_requests().await.unwrap()[0];
let body: serde_json::Value = serde_json::from_slice(&email_request.body).unwrap();
// Extract the link from one of the request fields
let get_link = |s: &str| {
let links: Vec<_> = linkify::LinkFinder::new()
.links(s)
.filter(|l| *l.kind() == linkify::LinkKind::Url)
.collect();
assert_eq!(links.len(), 1);
links[0].as_str().to_owned()
};
let raw_confirmation_link = get_link(&body["HtmlBody"].as_str().unwrap());
let confirmation_link = Url::parse(&raw_confirmation_link).unwrap();
// Let's make sure we don't call random APIs on the web
assert_eq!(confirmation_link.host_str().unwrap(), "127.0.0.1");
// Act
let response = reqwest::get(confirmation_link)
.await
.unwrap();
// Assert
assert_eq!(response.status().as_u16(), 200);
}
这里存在相当多的代码重复,但我们会适时处理。
我们现在的首要任务是确保测试顺利通过。
连接到点 - Green 测试
我们先来处理一下 URL 问题。
目前,它被硬编码在
//! src/routes/subscriptions.rs
// [...]
pub async fn send_confirmation_email(
email_client: &EmailClient,
new_subscriber: NewSubscriber,
) -> Result<(), reqwest::Error> {
let confirmation_link = "https://my-api.com/subscriptions/confirm";
// [...]
}
域名和协议会根据应用程序运行的环境而有所不同:测试环境为 http://127.0.0.1, 而生产环境中运行的应用程序则需要正确的 DNS 记录,并且使用 HTTPS 协议。
最简单的正确方法是将域名作为配置值传入。
让我们在 ApplicationSettings 中添加一个新字段:
//! src/configurations.rs
// [...]
#[derive(serde::Deserialize, Clone)]
pub struct ApplicationSettings {
#[serde(deserialize_with = "deserialize_number_from_string")]
pub port: u16,
pub host: String,
pub base_url: String,
}
# configuration/local.yaml
application:
base_url: "http://127.0.0.1"
#! spec.yaml
# [...]
services:
- name: zero2prod
# [...]
envs:
# We use DO's APP_URL to inject the dynamically
# provisioned base url as an environment variable
- key: APP_APPLICATION__BASE_URL
scope: RUN_TIME
value: ${APP_URL}
# [...]
# [...]
每次修改 spec.yaml 时,请务必将更改应用到 DigitalOcean; 通过 doctl apps list --format ID 获取您的应用标识符,然后运行 doctl apps update $APP_ID --spec spec.yaml .
现在我们需要在应用上下文中注册该值——你应该已经熟悉这个过程了:
//! src/startup.rs
// [...]
impl Application {
// We have converted the `build` function into a constructor for
// `Application`.
pub async fn build(configuration: Settings) -> Result<Self, std::io::Error> {
// [...]
let server = run(
listener,
connection_pool,
email_client,
// New parameter!
configuration.application.base_url,
)?;
Ok(Self { port, server })
}
// [...]
}
// We need to define a wrapper type in order to retrieve the URL
// in the `subscribe` handler.
// Retrieval from the context, in actix-web, is type-based: using
// a raw `String` would expose us to conflicts.
#[derive(Clone)]
pub struct ApplicationBaseUrl(pub String);
pub fn run(
// [...]
// New parameter!
base_url: String,
) -> Result<Server, std::io::Error> {
// [...]
let base_url = web::Data::new(ApplicationBaseUrl(base_url));
let server = HttpServer::new(move || {
App::new()
// [...]
.app_data(base_url.clone())
})
// [...]
}
我们现在可以在请求处理程序中访问它:
//! src/routres/subscriptions.rs
// [...]
#[tracing::instrument(
name = "Adding a new subscriber",
skip(form, pool, email_client, base_url),
fields(
subscriber_email = %form.email,
subscriber_name = %form.name,
)
)]
pub async fn subscribe(
form: web::Form<FormData>,
pool: web::Data<PgPool>,
// Get the email client from the app context
email_client: web::Data<EmailClient>,
// New parameter!
base_url: web::Data<ApplicationBaseUrl>,
) -> HttpResponse {
// [...]
// Pass the applicaiton url
if send_confirmation_email(
&email_client,
new_subscriber,
&base_url.0
)
.await
.is_err()
{
return HttpResponse::InternalServerError().finish();
}
HttpResponse::Ok().finish()
}
#[tracing::instrument(
name = "Send a confirmation email to a new subscriber",
skip(email_client, new_subscriber, base_url)
)]
pub async fn send_confirmation_email(
email_client: &EmailClient,
new_subscriber: NewSubscriber,
// New parameter!
base_url: &str,
) -> Result<(), reqwest::Error> {
let confirmation_link = format!("https://{base_url}/subscriptions/confirm");
// [...]
}
让我们再次运行测试:
thread 'subscriptions_confirm::the_link_returned_by_subscribe_returns_a_200_if_c
alled' panicked at tests/api/subscriptions_confirm.rs:55:10:
called `Result::unwrap()` on an `Err` value: reqwest::Error { kind: Request, url
: "http://127.0.0.1/subscriptions/confirm", source: hyper_util::client::legacy::
Error(Connect, ConnectError("tcp connect error", 127.0.0.1:80, Os { code: 111, k
ind: ConnectionRefused, message: "Connection refused" })) }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
test subscriptions_confirm::the_link_returned_by_subscribe_returns_a_200_if_call
ed ... FAILED
主机名正确,但测试中的 reqwest::Client 无法建立连接。到底出了什么问题?
仔细观察,你会发现 port: None ——我们发送请求到 http://127.0.0.1/subscriptions/confirm, 而没有指定测试服务器监听的端口。
这里棘手的地方在于事件的顺序:我们在启动服务器之前就传入了 application_url 配置值, 因此我们不知道它会监听哪个端口(因为端口号是随机分配的,取值为 0!)。
对于生产环境的工作负载来说,这不算什么问题,因为 DNS 域名就足够了——我们只需在测试中解决这个问题即可。
让我们将应用程序端口存储在 TestApp 中它自己的字段中:
//! tests/api/helpers.rs
// [...]
pub struct TestApp {
// [...]
// New field!
pub port: u16,
}
pub async fn spawn_app() -> TestApp {
/// [...]
let application = Application::build(configuration.clone())
.await
.expect("Failed to build application.");
let application_port = application.port();
// Get the port before spawning the application
let address = format!("http://127.0.0.1:{}", application_port);
let _ = tokio::spawn(application.run_until_stopped());
TestApp {
address,
port: application_port,
db_pool: get_connection_pool(&configuration.database),
email_server
}
}
然后我们可以在测试逻辑中使用它来编辑确认链接:
//! tests/api/subscriptions_confirm.rs
// [...]
async fn the_link_returned_by_subscribe_returns_a_200_if_called() {
// [...]
let mut confirmation_link = Url::parse(&raw_confirmation_link).unwrap();
// Let's rewrite the URL to inclkude the port
confirmation_link.set_port(Some(app.port)).unwrap();
// Let's make sure we don't call random APIs on the web
assert_eq!(confirmation_link.host_str().unwrap(), "127.0.0.1");
// Act
let response = reqwest::get(confirmation_link)
.await
.unwrap();
// Assert
assert_eq!(response.status().as_u16(), 200);
}
虽然不是最漂亮的,但能完成任务。
让我们再次运行测试:
thread 'subscriptions_confirm::the_link_returned_by_subscribe_returns_a_200_if_c
alled' panicked at tests/api/subscriptions_confirm.rs:59:5:
assertion `left == right` failed
left: 400
right: 200
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
我们收到了 400 Bad Request 错误代码,因为我们的确认链接没有附加订阅令牌 查询参数。
我们暂时通过硬编码来解决这个问题:
//! src/routes/subscriptions.rs
// [...]
pub async fn send_confirmation_email(
email_client: &EmailClient,
new_subscriber: NewSubscriber,
base_url: &str,
) -> Result<(), reqwest::Error> {
let confirmation_link = format!("{base_url}/subscriptions/confirm?subscription_token=mytoken");
// [...]
}
现在测试可以通过了!
连接到点 - 重构
从外发邮件请求中提取两个确认链接的逻辑在我们的两个测试中重复出现——随着我们完善此功能的剩余部分,我们可能会添加更多依赖该逻辑的测试。将其提取到其自身的辅助函数中是合理的。
//! tests/api/helpers.rs
// [...]
/// Confirmation links embedded in the request to the email API.
pub struct ConfirmationLinks {
pub html: reqwest::Url,
pub plain_text: reqwest::Url,
}
impl TestApp {
// [...]
/// Extract the confirmation links embedded in the request to the email API.
pub fn get_confirmation_links(&self, email_request: &wiremock::Request) -> ConfirmationLinks {
let body: serde_json::Value = serde_json::from_slice(&email_request.body).unwrap();
// Extract the link from one of the request fields.
let get_link = |s: &str| {
let links: Vec<_> = linkify::LinkFinder::new()
.links(s)
.filter(|l| *l.kind() == linkify::LinkKind::Url)
.collect();
assert_eq!(links.len(), 1);
let raw_link = links[0].as_str().to_owned();
let mut confirmation_link = reqwest::Url::parse(&raw_link).unwrap();
// Let's make sure we don't call random APIs on the web
assert_eq!(confirmation_link.host_str().unwrap(), "127.0.0.1");
confirmation_link.set_port(Some(self.port)).unwrap();
confirmation_link
};
let html = get_link(&body["HtmlBody"].as_str().unwrap());
let plain_text = get_link(&body["TextBody"].as_str().unwrap());
ConfirmationLinks { html, plain_text }
}
}
我们将其作为 TestApp 上的一个方法添加,以便访问应用程序端口,我们需要将其注入到链接中。
它也可以是一个自由函数,同时接受 wiremock::Request 和 TestApp (或 u16) 作为参数——这完全取决于个人喜好。
现在我们可以大大简化这两个测试用例了:
//! tests/api/subscriptions.rs
// [...]
#[tokio::test]
async fn subscribe_sends_a_confirmation_email_with_a_link() {
// Arrange
let app = spawn_app().await;
let body = "name=le%20guin&email=ursula_le_guin%40gmail.com";
Mock::given(path("/email"))
.and(method("POST"))
.respond_with(ResponseTemplate::new(200))
// We are not setting an expectation here anymore
// The test is focused on another aspect of the app
// behaviour.
.mount(&app.email_server)
.await;
// Act
app.post_subscriptions(body.into()).await;
// Assert
// Get the first intercepted request
let email_request = &app.email_server.received_requests().await.unwrap()[0];
let confirmation_links = app.get_confirmation_links(&email_request);
// The two links should be identical
assert_eq!(confirmation_links.html, confirmation_links.plain_text);
}
//! tests/api/subscriptions_confirm.rs
// [...]
#[tokio::test]
async fn the_link_returned_by_subscribe_returns_a_200_if_called() {
// Arrange
let app = spawn_app().await;
let body = "name=le%20guin&email=ursula_le_guin%40gmail.com";
Mock::given(path("/email"))
.and(method("POST"))
.respond_with(ResponseTemplate::new(200))
.mount(&app.email_server)
.await;
app.post_subscriptions(body.into()).await;
let email_request = &app.email_server.received_requests().await.unwrap()[0];
let confirmation_links = app.get_confirmation_links(&email_request);
// Act
let response = reqwest::get(confirmation_links.html)
.await
.unwrap();
// Assert
assert_eq!(response.status().as_u16(), 200);
}
现在这两个测试用例的意图已经更加清晰了。
订阅令牌
我们已经准备好解决这个棘手的问题:我们需要开始生成订阅令牌。
订阅令牌 - Red 测试
我们将在刚刚完成的工作基础上添加一个新的测试用例: 我们不再根据返回的状态码进行断言,而是检查存储在数据库中的订阅者的状态。
//! tests/api/subscriptions_confirm.rs
// [...]
#[tokio::test]
async fn clicking_on_the_confirmation_link_confirms_a_subscriber() {
// Arrange
let app = spawn_app().await;
let body = "name=le%20guin&email=ursula_le_guin%40gmail.com";
Mock::given(path("/email"))
.and(method("POST"))
.respond_with(ResponseTemplate::new(200))
.mount(&app.email_server)
.await;
app.post_subscriptions(body.into()).await;
let email_request = &app.email_server.received_requests().await.unwrap()[0];
let confirmation_links = app.get_confirmation_links(&email_request);
// Act
reqwest::get(confirmation_links.html)
.await
.unwrap()
.error_for_status()
.unwrap();
// Assert
let saved = sqlx::query!("SELECT email, name, status FROM subscriptions",)
.fetch_one(&app.db_pool)
.await
.expect("Failed to fetch subscriptions.");
assert_eq!(saved.email, "ursula_le_guin@gmail.com");
assert_eq!(saved.name, "le guin");
assert_eq!(saved.status, "confirmed");
}
正如预期的那样,测试失败:
thread 'subscriptions_confirm::clicking_on_the_confirmation_link_confirms_a_subs
criber' panicked at tests/api/subscriptions_confirm.rs:77:5:
assertion `left == right` failed
left: "pending_confirmation"
right: "confirmed"
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
订阅令牌 - Green 测试
为了使之前的测试用例通过,我们在确认链接中硬编码了一个订阅令牌:
//! src/routes/subscriptions.rs
// [...]
pub async fn send_confirmation_email(/*[...]*/) -> Result<(), reqwest::Error> {
let confirmation_link = format!(
"{}/subscriptions/confirm?subscription_token=mytoken",
base_url
);
// [...]
}
让我们重构 send_confirmation_email 函数, 将 token 作为参数——这样可以更轻松地在上游添加生成逻辑。
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(
form: web::Form<FormData>,
pool: web::Data<PgPool>,
// Get the email client from the app context
email_client: web::Data<EmailClient>,
base_url: web::Data<ApplicationBaseUrl>,
) -> HttpResponse {
// [...]
if send_confirmation_email(
&email_client,
new_subscriber,
&base_url.0,
// New parameter!
"mytoken"
)
.await
.is_err()
{
return HttpResponse::InternalServerError().finish();
}
// [...]
}
pub async fn send_confirmation_email(
email_client: &EmailClient,
new_subscriber: NewSubscriber,
base_url: &str,
// New parameter!
subscription_token: &str,
) -> Result<(), reqwest::Error> {
let confirmation_link =
format!("{base_url}/subscriptions/confirm?subscription_token={subscription_token}");
// [...]
}
我们的订阅令牌并非密码:它们是一次性的,并且不授予访问受保护信息的权限。我们需要它们足够难以猜测,同时牢记,最坏的情况是,不受欢迎的新闻通讯订阅信息出现在某人的收件箱中。
考虑到我们的要求,使用加密安全的伪随机数生成器就足够了——如果你喜欢晦涩的缩写词,可以使用 CSPRNG。
每次我们需要生成订阅令牌时,我们都可以采样一个足够长的字母数字字符序列。
为了实现这一点,我们需要添加 rand 作为依赖项:
cargo add rand --features=std_rng
//! src/routes/subscriptions.rs
use rand::distributions::Alphanumeric;
use rand::Rng;
// [...]
/// Generate a random 25-characters-long acse-sensitive subscription token.
fn generate_subscription_token() -> String {
let mut rng = rand::rng();
std::iter::repeat_with(|| rng.sample(Alphanumeric))
.map(char::from)
.take(25)
.collect()
}
使用 25 个字符,我们大约可以得到 10^45 个可能的令牌——这对于我们的用例来说应该足够了。
为了在 GET /subscriptions/confirm 中检查令牌是否有效,我们需要使用 POST /subscriptions 将新生成的令牌存储在数据库中。
为此,我们添加了一个表 subscription_tokens, 它包含两列: subscription_token 和 subscription_id。
我们目前在 insert_subscriber 中生成订阅者标识符,但从未将其返回给调用者:
pub async fn insert_subscriber(
pool: &PgPool,
new_subscriber: &NewSubscriber,
) -> Result<(), sqlx::Error> {
sqlx::query!(
r#"[...]"#,
// The subscriber id, never returned or bound to a variable
Uuid::new_v4(),
// [...]
)
// [...]
}
让我们重构 insert_subscriber 来返回id:
pub async fn insert_subscriber(
pool: &PgPool,
new_subscriber: &NewSubscriber,
) -> Result<Uuid, sqlx::Error> {
let subscriber_id = Uuid::new_v4();
sqlx::query!(
r#"[...]"#,
subscriber_id,
// [...]
)
// [...]
Ok(subscriber_id)
}
现在我们可以把所有内容联系在一起:
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(
// [...]
) -> HttpResponse {
// [...]
let Ok(subscriber_id) = insert_subscriber(&pool, &new_subscriber).await else {
return HttpResponse::InternalServerError().finish();
};
let subscription_token = generate_subscription_token();
if store_token(&pool, subscriber_id, &subscription_token)
.await
.is_err()
{
return HttpResponse::InternalServerError().finish();
}
// Pass the applicaiton url
if send_confirmation_email(
&email_client,
new_subscriber,
&base_url.0,
&subscription_token,
)
.await
.is_err()
{
return HttpResponse::InternalServerError().finish();
}
HttpResponse::Ok().finish()
}
#[tracing::instrument(
name = "Store subscription toke in the database",
skip(subscription_token, pool)
)]
pub async fn store_token(
pool: &PgPool,
subscriber_id: Uuid,
subscription_token: &str,
) -> Result<(), sqlx::Error> {
sqlx::query!(
r#"INSERT INTO subscription_tokens (subscription_token, subscriber_id)
VALUES ($1, $2)"#,
subscription_token,
subscriber_id
)
.execute(pool)
.await
.inspect_err(|e| {
tracing::error!("Failed to execute query: {e:?}");
})?;
Ok(())
}
我们已经完成了 POST /subscriptions, 让我们转到 GET /subscription/confirm:
//! src/routes/subscriptions_confirm.rs
use actix_web::{web, HttpResponse};
#[derive(serde::Deserialize)]
pub struct Parameters {
subscription_token: String,
}
#[tracing::instrument(
name = "Confirm a pending subscriber",
skip(_parameters)
)]
pub async fn confirm(_parameters: web::Query<Parameters>) -> HttpResponse {
HttpResponse::Ok().finish()
}
我们需要:
- 获取数据库池的引用
- 检索与令牌关联的订阅者 ID(如果存在)
- 将订阅者状态更改为已确认
这些我们之前都做过——让我们开始吧!
//! src/routes/subscriptions_confirm.rs
use actix_web::{HttpResponse, web};
use sqlx::PgPool;
use uuid::Uuid;
#[derive(serde::Deserialize)]
pub struct Parameters {
subscription_token: String,
}
#[tracing::instrument(name = "Confirm a pending subscriber", skip(parameters, pool))]
pub async fn confirm(parameters: web::Query<Parameters>, pool: web::Data<PgPool>) -> HttpResponse {
let id = match get_subscriber_id_from_token(&pool, ¶meters.subscription_token).await {
Ok(id) => id,
Err(_) => return HttpResponse::InternalServerError().finish(),
};
match id {
// Non-existing token!
None => HttpResponse::Unauthorized().finish(),
Some(subscriber_id) => {
if confirm_subscriber(&pool, subscriber_id).await.is_err() {
return HttpResponse::InternalServerError().finish();
}
HttpResponse::Ok().finish()
}
}
}
#[tracing::instrument(name = "Mark subscriber as confirmed", skip(subscriber_id, pool))]
pub async fn confirm_subscriber(pool: &PgPool, subscriber_id: Uuid) -> Result<(), sqlx::Error> {
sqlx::query!(
r#"UPDATE subscriptions SET status = 'confirmed' WHERE id = $1"#,
subscriber_id
)
.execute(pool)
.await
.inspect_err(|e| {
tracing::error!("Failed to execute query: {e:?}");
})?;
Ok(())
}
#[tracing::instrument(name = "Get subscriber_id from token", skip(subscription_token, pool))]
pub async fn get_subscriber_id_from_token(
pool: &PgPool,
subscription_token: &str,
) -> Result<Option<Uuid>, sqlx::Error> {
let result = sqlx::query!(
r#"SELECT subscriber_id FROM subscription_tokens WHERE subscription_token = $1"#,
subscription_token
)
.fetch_optional(pool)
.await
.inspect_err(|e| {
tracing::error!("Failed to execute query: {e:?}");
})?;
Ok(result.map(|r| r.subscriber_id))
}
这够了吗? 我们遗漏了什么吗?
只有一个方法可以找到答案。
cargo test
test result: ok. 10 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; fin
ished in 0.47s
哦,是的! 有效!
数据库事务
全部还是什么都没有
但现在就宣布胜利还为时过早。
我们的 POST /subscriptions 处理程序变得越来越复杂——我们现在对 Postgres 数据库执行两个 INSERT 查询:一个用于存储新订阅者的详细信息,另一个用于存储
新生成的订阅令牌。
如果应用程序在这两个操作之间崩溃会发生什么?
第一个查询可能成功完成,但第二个查询可能永远不会执行。
调用 POST /subscriptions 后,我们的数据库可能处于三种状态:
- 已持久化新订阅者及其令牌
- 已持久化新订阅者,但没有令牌
- 未持久化任何内容。
查询越多,就越难以推断数据库可能的最终状态。
关系数据库(以及其他一些数据库)提供了一种缓解此问题的机制:事务。
事务是一种将相关操作组合成单个工作单元的方法。
数据库保证事务中的所有操作都会同时成功或失败: 数据库永远不会处于只有事务中部分查询的影响可见的状态。
回到我们的例子,如果我们将两个 INSERT 查询包装在一个事务中,现在有两种可能的最终状态:
- 新的订阅者及其令牌已被持久化
- 没有任何内容被持久化
处理起来更容易。
Postgres 中的事务
要在 Postgres 中启动事务,请使用 BEGIN 语句。BEGIN 之后的所有查询都属于该事务。
然后,使用 COMMIT 语句完成事务。
实际上,我们已经在一个迁移脚本中使用了事务!
BEGIN;
-- Backfill `status` for historical entries
UPDATE subscriptions
SET status = 'confirmed'
WHERE status IS NULL;
-- Make `status` mandatory
ALTER TABLE subscriptions ALTER COLUMN status SET NOT NULL;
COMMIT;
如果事务中的任何查询失败,数据库就会回滚:所有先前查询执行的更改都将被还原,操作将中止。
您也可以使用 ROLLBACK 语句显式触发回滚。
事务是一个深奥的主题:它们不仅提供了一种将多个语句转换为全有或全无操作的方法,还能隐藏未提交更改对可能同时针对同一张表运行的其他查询的影响。
随着需求的变化,您通常需要显式选择事务的隔离级别,
以便微调数据库为您的操作提供的并发保证。随着系统规模和复杂性的增长,掌握各种与并发相关的问题(例如脏读、幻读等)变得越来越重要。
如果您想了解更多关于这些主题的信息,我强烈推荐《设计数据密集型应用程序》。
sqlx 中的事务
回到代码:我们如何在 sqlx 中利用事务?
您无需手动编写 BEGIN 语句:事务对于关系数据库的使用至关重要, 因此 sqlx 提供了专用 API。
通过在连接池中调用 begin, 我们可以从连接池中获取一个连接并启动一个事务:
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(
form: web::Form<FormData>,
pool: web::Data<PgPool>,
// Get the email client from the app context
email_client: web::Data<EmailClient>,
base_url: web::Data<ApplicationBaseUrl>,
) -> HttpResponse {
let new_subscriber = /*[...]*/;
let mut transaction = match pool.begin().await {
Ok(transaction) => transaction,
Err(_) => return HttpResponse::InternalServerError().finish(),
};
}
如果成功, begin 将返回一个 Transaction 结构体。
对 Transaction 的可变引用实现了 sqlx 的 Executor 特性,因此可以用于
运行查询。所有使用 Transaction 作为执行器运行的查询都会成为该事务的一部分。
让我们将事务传递给 insert_subscriber 和 store_token 而不是 pool:
//! src/routes/subscriptions.rs
pub async fn subscribe(
form: web::Form<FormData>,
pool: web::Data<PgPool>,
// Get the email client from the app context
email_client: web::Data<EmailClient>,
base_url: web::Data<ApplicationBaseUrl>,
) -> HttpResponse {
// [...]
let mut transaction = match pool.begin().await {
Ok(transaction) => transaction,
Err(_) => return HttpResponse::InternalServerError().finish(),
};
let Ok(subscriber_id) = insert_subscriber(&mut *transaction, &new_subscriber).await else {
return HttpResponse::InternalServerError().finish();
};
let subscription_token = generate_subscription_token();
if store_token(&mut *transaction, subscriber_id, &subscription_token)
.await
.is_err()
{
return HttpResponse::InternalServerError().finish();
}
// [...]
}
#[tracing::instrument(
name = "Store subscription toke in the database",
skip(subscription_token, transaction)
)]
pub async fn store_token(
transaction: &mut PgConnection,
subscriber_id: Uuid,
subscription_token: &str,
) -> Result<(), sqlx::Error> {
sqlx::query!(
r#"[...]"#,
subscription_token,
subscriber_id
)
.execute(transaction)
.await
// [...]
}
#[tracing::instrument(
name = "Saving new subscriber details in the database",
skip(new_subscriber, transaction)
)]
pub async fn insert_subscriber(
transaction: &mut PgConnection,
new_subscriber: &NewSubscriber,
) -> Result<Uuid, sqlx::Error> {
// [...]
sqlx::query!(
r#"[...]"#,
subscriber_id,
new_subscriber.email.as_ref(),
new_subscriber.name.as_ref(),
Utc::now()
)
.execute(transaction)
.await
// [...]
}
如果你现在运行 cargo test,你会发现一些有趣的事情:我们的一些测试失败了!
为什么会这样?
正如我们讨论过的,事务要么提交,要么回滚。
Transaction 公开了两个专用方法:Transaction::commit 用于持久化更改,以及 Transaction::rollback 用于中止整个操作。
我们并没有调用这两个方法——在这种情况下会发生什么?
我们可以查看 sqlx 的源代码来更好地理解。
特别是 Transaction 的 Drop 实现:
impl<'c, DB> Drop for Transaction<'c, DB>
where
DB: Database,
{
fn drop(&mut self) {
if self.open {
// starts a rollback operation
// what this does depends on the database but generally this means we queue a rollback
// operation that will happen on the next asynchronous invocation of the underlying
// connection (including if the connection is returned to a pool)
DB::TransactionManager::start_rollback(&mut self.connection);
}
}
}
self.open 是一个内部布尔值,附加到用于启动事务并运行附加查询的连接上。
使用 begin 创建事务时,该值会被设置为 true, 直到调用 rollback 或 commit 为止:
impl<'c, DB> Transaction<'c, DB>
where
DB: Database,
{
#[doc(hidden)]
pub fn begin(
conn: impl Into<MaybePoolConnection<'c, DB>>,
statement: Option<Cow<'static, str>>,
) -> BoxFuture<'c, Result<Self, Error>> {
let mut conn = conn.into();
Box::pin(async move {
DB::TransactionManager::begin(&mut conn, statement).await?;
Ok(Self {
connection: conn,
open: true,
})
})
}
/// Commits this transaction or savepoint.
pub async fn commit(mut self) -> Result<(), Error> {
DB::TransactionManager::commit(&mut self.connection).await?;
self.open = false;
Ok(())
}
/// Aborts this transaction or savepoint.
pub async fn rollback(mut self) -> Result<(), Error> {
DB::TransactionManager::rollback(&mut self.connection).await?;
self.open = false;
Ok(())
}
}
换句话说:如果在 Transaction 对象超出范围(即调用 Drop 函数)之前未调用提交或回滚函数,则回滚命令会排队等待,一旦有机会就会执行。
这就是我们的测试失败的原因: 我们使用了事务,但并未显式提交更改。当连接返回到池中时,在请求处理程序的末尾,所有更改都会回滚,这不符合我们的测试预期。
我们可以通过在 subscribe 中添加一行代码来解决这个问题:
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(
form: web::Form<FormData>,
pool: web::Data<PgPool>,
// Get the email client from the app context
email_client: web::Data<EmailClient>,
base_url: web::Data<ApplicationBaseUrl>,
) -> HttpResponse {
// [...]
let mut transaction = match pool.begin().await {
Ok(transaction) => transaction,
Err(_) => return HttpResponse::InternalServerError().finish(),
};
let Ok(subscriber_id) = insert_subscriber(&mut *transaction, &new_subscriber).await else {
return HttpResponse::InternalServerError().finish();
};
let subscription_token = generate_subscription_token();
if store_token(&mut *transaction, subscriber_id, &subscription_token)
.await
.is_err()
{
return HttpResponse::InternalServerError().finish();
}
if transaction.commit().await.is_err() {
return HttpResponse::InternalServerError().finish();
}
// [...]
}
测试套件应该再次通过。
继续部署应用程序: 看到功能在实时环境中运行,会带来全新的满足感!
小结
本章是一段漫长的旅程,但您也已经取得了长足的进步!
从测试套件开始,我们的应用程序框架已开始成型。功能也在不断完善:我们现在拥有一个功能齐全的订阅流程,并附带了一封正式的确认邮件。
更重要的是: 我们正在逐渐适应编写 Rust 代码的节奏。 本章的最后是一段漫长的结对编程练习,我们取得了显著的进展,而没有引入太多新概念。
现在正是您独立探索的好时机:改进我们目前构建的内容!
有很多机会:
- 如果用户尝试订阅两次会发生什么? 确保他们收到两封确认邮件
- 如果用户点击两次确认链接会发生什么?
- 如果订阅令牌格式正确但不存在会发生什么?
- 添加对传入令牌的验证,我们目前将原始用户输入直接传递给查询(感谢 sqlx 保护我们免受 SQL 注入攻击 <3)
- 使用合适的模板解决方案来设计我们的电子邮件(例如 tera)
- 任何你能想到的!
需要刻意练习才能精通。
错误处理
为了发送确认邮件,我们必须将多个操作拼凑在一起:验证用户输入、发送电子邮件、各种数据库查询。
它们都有一个共同点:它们可能会失败。
在第六章中,我们讨论了 Rust 中错误处理的构建块——Result 和 ? 运算符。
我们留下了许多未解答的问题: 错误如何融入我们应用程序的更广泛架构中? 一个好的错误是什么样的? 错误是为谁设计的?我们应该使用库吗? 哪一个?
本章将重点深入分析 Rust 中的错误处理模式。
错误的目的是什么的
让我们以一个例子开始:
//! src/routes/subscriptions.rs
// [...]
pub async fn store_token(
transaction: &mut PgConnection,
subscriber_id: Uuid,
subscription_token: &str,
) -> Result<(), sqlx::Error> {
sqlx::query!(
r#"INSERT INTO subscription_tokens (subscription_token, subscriber_id)
VALUES ($1, $2)"#,
subscription_token,
subscriber_id
)
.execute(transaction)
.await
.inspect_err(|e| {
tracing::error!("Failed to execute query: {e:?}");
})?;
Ok(())
}
我们正在尝试在 subscription_tokens 表中插入一行,以便存储新生成的令牌(根据 subscription_id 进行存储)。
执行操作可能存在错误: 我们在与数据库通信时可能会遇到网络问题,我们尝试插入的行可能违反了某些表约束(例如主键的唯一性),等等。
内部错误
使调用者能够做出反应
如果发生故障, execute 的调用者很可能希望得到通知——他们需要做出相应的反应,例如重试查询或使用 ? 将故障传递到上游,就像我们的例子一样。
Rust 利用类型系统来传达操作可能无法成功: execute 的返回类型是 Result, 一个枚举。
pub enum Result<Success, Error> {
Ok(Success),
Err(Error)
}
不需要通用的 Error 类型——我们只需检查 execute 是否返回了 Err 变量即可, 例如
let outcome = sqlx::query!(/*[...]*/)
.execute(transaction)
.await;
if outcome == ResultSignal::Error {
// Do something if it failed
}
如果只有一种故障模式,这种方法是可行的。事实上,操作可能以多种方式失败,我们可能需要根据具体情况采取不同的应对措施。
让我们看一下 sqlx::Error 的框架,它是执行的错误类型:
//! sqlx-core/src/error.rs
pub enum Error {
Configuration(#[source] BoxDynError),
InvalidArgument(String),
Database(#[source] Box<dyn DatabaseError>),
Io(#[from] io::Error),
Tls(#[source] BoxDynError),
Protocol(String),
RowNotFound,
TypeNotFound { type_name: String },
ColumnIndexOutOfBounds { index: usize, len: usize },
ColumnNotFound(String),
ColumnDecode {
index: String,
#[source]
source: BoxDynError,
},
Encode(#[source] BoxDynError),
Decode(#[source] BoxDynError),
AnyDriverError(#[source] BoxDynError),
PoolTimedOut,
PoolClosed,
WorkerCrashed,
Migrate(#[source] Box<crate::migrate::MigrateError>),
InvalidSavePointStatement,
BeginFailed,
}
列表很丰富,不是吗?
sqlx::Error 实现为枚举,允许用户匹配返回的错误,并根据底层故障模式采取不同的行为。例如,您可能希望重试 PoolTimedOut, 而您可能会放弃 ColumnNotFound。
帮助操作员排除故障
如果操作只有一种故障模式,我们是否应该只使用 () 作为错误类型?
Err(()) 可能足以让调用者决定该做什么——例如,向用户返回 500 内部服务器错误。
但控制流并非应用程序中错误的唯一用途。
我们希望错误能够包含足够的上下文信息,以便为运维人员(例如开发人员)生成包含足够详细信息的报告,以便他们进行故障排除。
我们所说的报告是什么意思?
在像我们这样的后端 API 中,它通常是一个日志事件。 在 CLI 中,它可能是使用 --verbose 标志时显示在终端中的错误消息。
实现细节可能有所不同,但目的保持不变:帮助人们理解哪里出了问题。
这正是我们在初始代码片段中所做的:
//! src/routes/subscriptions.rs
// [...]
pub async fn store_token(
transaction: &mut PgConnection,
subscriber_id: Uuid,
subscription_token: &str,
) -> Result<(), sqlx::Error> {
sqlx::query!(/*[...]*/)
.execute(transaction)
.await
.inspect_err(|e| {
tracing::error!("Failed to execute query: {e:?}");
})?;
// [...]
}
如果查询失败,我们会捕获错误并发出日志事件。然后,我们可以在调查数据库问题时检查错误日志。
边缘错误
帮助用户排除故障
到目前为止,我们专注于 API 的内部机制——函数调用其他函数,以及操作符在发生问题后试图理清头绪。
那么用户呢?
与操作员一样,用户也希望 API 在遇到故障模式时发出信号。
当 store_token 失败时,我们的 API 用户会看到什么?
我们可以通过查看请求处理程序来找到答案:
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(
form: web::Form<FormData>,
pool: web::Data<PgPool>,
// Get the email client from the app context
email_client: web::Data<EmailClient>,
base_url: web::Data<ApplicationBaseUrl>,
) -> HttpResponse {
// [...]
if store_token(&mut *transaction, subscriber_id, &subscription_token)
.await
.is_err()
{
return HttpResponse::InternalServerError().finish();
}
// [...]
}
他们收到一个没有正文的 HTTP 响应,并带有 500 内部服务器错误状态码。
该状态码的作用与 store_token 中的错误类型相同:它是一条机器可解析的信息,调用者(例如浏览器)可以使用它来确定下一步的操作(例如,假设是暂时性故障,则重试请求)。
浏览器背后的人呢? 我们告诉他们什么?
没什么,响应正文是空的。
这实际上是一个很好的实现: 用户不应该关心他们所调用 API 的内部结构——他们没有相关的心理模型,也无法确定失败的原因。
那是操作员的工作范围。
我们特意省略了这些细节。
在其他情况下,我们需要向人类用户传达额外的信息。让我们看看对同一端点的输入验证:
//! src/routes/subscriptions.rs
#[derive(serde::Deserialize)]
pub struct FormData {
email: String,
name: String,
}
impl TryFrom<FormData> for NewSubscriber {
type Error = String;
fn try_from(value: FormData) -> Result<Self, Self::Error> {
let name = SubscriberName::parse(value.name)?;
let email = SubscriberEmail::parse(value.email)?;
Ok(NewSubscriber { email, name })
}
}
我们收到了用户提交的表单中附加的电子邮件地址和姓名数据。
这两个字段都需要经过额外的验证——SubscriberName::parse 和 SubscriberEmail::parse 。这两个方法容易出错——它们会返回一个字符串作为错误类型,来解释出错的原因:
//! src/domain/subscriber_email.rs
// [...]
impl SubscriberEmail {
pub fn parse(s: String) -> Result<Self, String> {
if validator::ValidateEmail::validate_email(&s) {
Ok(Self(s))
} else {
Err(format!("{s} is not a valid subscriber email."))
}
}
}
我必须承认, 这并不是最有用的错误消息 :我们只是告诉用户他们输入的电子邮件地址有误, 但却没有帮助他们确定错误原因。
说到底, 这根本无关紧要: 我们并没有将任何此类信息作为 API 响应的一部分发送给用户——他们收到的是一个没有正文的 400 Bad Request 错误代码。
//! src/routes/subscription.rs
// [...]
pub async fn subscribe(
form: web::Form<FormData>,
pool: web::Data<PgPool>,
// Get the email client from the app context
email_client: web::Data<EmailClient>,
base_url: web::Data<ApplicationBaseUrl>,
) -> HttpResponse {
let new_subscriber = match form.into_inner().try_into() {
Ok(subscriber) => subscriber,
Err(_) => return HttpResponse::BadRequest().finish(),
};
// [...]
}
这是一个严重的错误: 用户被蒙在鼓里,无法按要求调整自己的行为。
小结
让我们总结一下迄今为止的发现。
错误主要有两个用途:
- 控制流(即确定下一步操作);
- 报告(例如,事后调查哪里出了问题)。我们还可以根据错误的位置来区分错误:
- 内部(即应用程序内某个函数调用另一个函数);
- 边缘(即我们未能完成的 API 请求)。
控制流是脚本化的:所有决定下一步操作所需的信息都必须能够被机器访问。
我们使用类型(例如枚举变量)、方法和字段来表示内部错误。
我们依靠状态码来处理边缘错误。
而错误报告主要供人类使用。
内容必须根据受众进行调整。
操作员可以访问系统内部——应该为他们提供尽可能多的关于故障模式的上下文信息。
用户位于应用程序的边界之外: 应该只向他们提供调整其行为所需的信息量(例如,在必要时修复格式错误的输入)。
我们可以使用一个2x2的表格来可视化这个心智模型,其中位置为列,目的为行:
| Internal | At the edge | |
|---|---|---|
| 控制流报告 | 类型, 方法 , 字段, 日志/跟踪 | 状态码和body |
我们将用本章的剩余部分来改进表格中每个单元格的错误处理策略。
操作员错误报告
让我们从操作符的错误报告开始。
我们现在的错误日志记录做得好吗?
让我们编写一个快速测试来找出答案:
//! tests/api/subscriptions.rs
// [...]
#[tokio::test]
async fn subscribe_fails_if_there_is_a_fatal_database_error() {
// Arrange
let app = spawn_app().await;
let body = "name=le%20guin&email=ursula_le_guin%40gmail.com";
// Sabotage the database
sqlx::query!("ALTER TABLE subscription_tokens DROP COLUMN subscription_token;",)
.execute(&app.db_pool)
.await
.unwrap();
// Act
let response = app.post_subscriptions(body.into()).await;
// Assert
assert_eq!(response.status().as_u16(), 500);
}
测试立即通过 - 让我们看看应用程序发出的日志
export RUST_LOG="sqlx=error,info"
export TEST_LOG=enabled
cargo t subscribe_fails_if_there_is_a_fatal_database_error | bunyan
[2025-08-30T09:18:10.900Z] INFO: test/75405 on qby-workspace: starting 20 worke
rs (line=310,target=actix_server::builder)
file: /home/cubewhy/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/act
ix-server-2.6.0/src/builder.rs
[2025-08-30T09:18:10.900Z] INFO: test/75405 on qby-workspace: Tokio runtime fou
nd; starting in existing Tokio runtime (line=192,target=actix_server::server)
file: /home/cubewhy/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/act
ix-server-2.6.0/src/server.rs
[2025-08-30T09:18:10.900Z] INFO: test/75405 on qby-workspace: starting service:
"actix-web-service-127.0.0.1:37105", workers: 20, listening on: 127.0.0.1:37105
(line=197,target=actix_server::server)
file: /home/cubewhy/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/act
ix-server-2.6.0/src/server.rs
[2025-08-30T09:18:10.945Z] INFO: test/75405 on qby-workspace: [HTTP REQUEST - S
TART] (http.client_ip=127.0.0.1,http.flavor=1.1,http.host=127.0.0.1:37105,http.m
ethod=POST,http.route=/subscriptions,http.scheme=http,http.target=/subscriptions
,http.user_agent="",line=41,otel.kind=server,otel.name="POST /subscriptions",req
uest_id=7fca956f-0fe2-46b2-8128-905edb39b79f,target=tracing_actix_web::root_span
_builder)
file: /home/cubewhy/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/tra
cing-actix-web-0.7.19/src/root_span_builder.rs
[2025-08-30T09:18:10.945Z] INFO: test/75405 on qby-workspace: [ADDING A NEW SUB
SCRIBER - START] (file=src/routes/subscriptions.rs,http.client_ip=127.0.0.1,http
.flavor=1.1,http.host=127.0.0.1:37105,http.method=POST,http.route=/subscriptions
,http.scheme=http,http.target=/subscriptions,http.user_agent="",line=40,otel.kin
d=server,otel.name="POST /subscriptions",request_id=7fca956f-0fe2-46b2-8128-905e
db39b79f,subscriber_email=ursula_le_guin@gmail.com,subscriber_name="le guin",tar
get=zero2prod::routes::subscriptions)
[2025-08-30T09:18:10.983Z] INFO: test/75405 on qby-workspace: [SAVING NEW SUBSC
RIBER DETAILS IN THE DATABASE - START] (file=src/routes/subscriptions.rs,http.cl
ient_ip=127.0.0.1,http.flavor=1.1,http.host=127.0.0.1:37105,http.method=POST,htt
p.route=/subscriptions,http.scheme=http,http.target=/subscriptions,http.user_age
nt="",line=142,otel.kind=server,otel.name="POST /subscriptions",request_id=7fca9
56f-0fe2-46b2-8128-905edb39b79f,subscriber_email=ursula_le_guin@gmail.com,subscr
iber_name="le guin",target=zero2prod::routes::subscriptions)
[2025-08-30T09:18:10.984Z] INFO: test/75405 on qby-workspace: [SAVING NEW SUBSC
RIBER DETAILS IN THE DATABASE - END] (elapsed_milliseconds=0,file=src/routes/sub
scriptions.rs,http.client_ip=127.0.0.1,http.flavor=1.1,http.host=127.0.0.1:37105
,http.method=POST,http.route=/subscriptions,http.scheme=http,http.target=/subscr
iptions,http.user_agent="",line=142,otel.kind=server,otel.name="POST /subscripti
ons",request_id=7fca956f-0fe2-46b2-8128-905edb39b79f,subscriber_email=ursula_le_
guin@gmail.com,subscriber_name="le guin",target=zero2prod::routes::subscriptions
)
[2025-08-30T09:18:10.984Z] INFO: test/75405 on qby-workspace: [STORE SUBSCRIPTI
ON TOKE IN THE DATABASE - START] (file=src/routes/subscriptions.rs,http.client_i
p=127.0.0.1,http.flavor=1.1,http.host=127.0.0.1:37105,http.method=POST,http.rout
e=/subscriptions,http.scheme=http,http.target=/subscriptions,http.user_agent="",
line=93,otel.kind=server,otel.name="POST /subscriptions",request_id=7fca956f-0fe
2-46b2-8128-905edb39b79f,subscriber_email=ursula_le_guin@gmail.com,subscriber_id
=cc96b7d3-40cf-4355-b856-13415718c380,subscriber_name="le guin",target=zero2prod
::routes::subscriptions)
[2025-08-30T09:18:10.985Z] ERROR: test/75405 on qby-workspace: [STORE SUBSCRIPTI
ON TOKE IN THE DATABASE - EVENT] Failed to execute query: Database(PgDatabaseErr
or { severity: Error, code: "42703", message: "column \"subscription_token\" of
relation \"subscription_tokens\" does not exist", detail: None, hint: None, posi
tion: Some(Original(34)), where: None, schema: None, table: None, column: None,
data_type: None, constraint: None, file: Some("parse_target.c"), line: Some(1065
), routine: Some("checkInsertTargets") }) (file=src/routes/subscriptions.rs,http
.client_ip=127.0.0.1,http.flavor=1.1,http.host=127.0.0.1:37105,http.method=POST,
http.route=/subscriptions,http.scheme=http,http.target=/subscriptions,http.user_
agent="",line=111,otel.kind=server,otel.name="POST /subscriptions",request_id=7f
ca956f-0fe2-46b2-8128-905edb39b79f,subscriber_email=ursula_le_guin@gmail.com,sub
scriber_id=cc96b7d3-40cf-4355-b856-13415718c380,subscriber_name="le guin",target
=zero2prod::routes::subscriptions)
[2025-08-30T09:18:10.985Z] INFO: test/75405 on qby-workspace: [STORE SUBSCRIPTI
ON TOKE IN THE DATABASE - END] (elapsed_milliseconds=0,file=src/routes/subscript
ions.rs,http.client_ip=127.0.0.1,http.flavor=1.1,http.host=127.0.0.1:37105,http.
method=POST,http.route=/subscriptions,http.scheme=http,http.target=/subscription
s,http.user_agent="",line=93,otel.kind=server,otel.name="POST /subscriptions",re
quest_id=7fca956f-0fe2-46b2-8128-905edb39b79f,subscriber_email=ursula_le_guin@gm
ail.com,subscriber_id=cc96b7d3-40cf-4355-b856-13415718c380,subscriber_name="le g
uin",target=zero2prod::routes::subscriptions)
[2025-08-30T09:18:10.985Z] INFO: test/75405 on qby-workspace: [ADDING A NEW SUB
SCRIBER - END] (elapsed_milliseconds=39,file=src/routes/subscriptions.rs,http.cl
ient_ip=127.0.0.1,http.flavor=1.1,http.host=127.0.0.1:37105,http.method=POST,htt
p.route=/subscriptions,http.scheme=http,http.target=/subscriptions,http.user_age
nt="",line=40,otel.kind=server,otel.name="POST /subscriptions",request_id=7fca95
6f-0fe2-46b2-8128-905edb39b79f,subscriber_email=ursula_le_guin@gmail.com,subscri
ber_name="le guin",target=zero2prod::routes::subscriptions)
[2025-08-30T09:18:10.985Z] INFO: test/75405 on qby-workspace: [HTTP REQUEST - E
ND] (elapsed_milliseconds=40,http.client_ip=127.0.0.1,http.flavor=1.1,http.host=
127.0.0.1:37105,http.method=POST,http.route=/subscriptions,http.scheme=http,http
.status_code=500,http.target=/subscriptions,http.user_agent="",line=41,otel.kind
=server,otel.name="POST /subscriptions",otel.status_code=OK,request_id=7fca956f-
0fe2-46b2-8128-905edb39b79f,target=tracing_actix_web::root_span_builder)
没有任何可操作的信息。记录 "Oops! Something went wrong!" 也同样有用。
我们需要继续查找,直到找到最后剩下的错误日志:
[2025-08-30T09:18:10.985Z] ERROR: test/75405 on qby-workspace: [STORE SUBSCRIPTI
ON TOKE IN THE DATABASE - EVENT] Failed to execute query: Database(PgDatabaseErr
or { severity: Error, code: "42703", message: "column \"subscription_token\" of
relation \"subscription_tokens\" does not exist", detail: None, hint: None, posi
tion: Some(Original(34)), where: None, schema: None, table: None, column: None,
data_type: None, constraint: None, file: Some("parse_target.c"), line: Some(1065
), routine: Some("checkInsertTargets") }) (file=src/routes/subscriptions.rs,http
.client_ip=127.0.0.1,http.flavor=1.1,http.host=127.0.0.1:37105,http.method=POST,
http.route=/subscriptions,http.scheme=http,http.target=/subscriptions,http.user_
agent="",line=111,otel.kind=server,otel.name="POST /subscriptions",request_id=7f
ca956f-0fe2-46b2-8128-905edb39b79f,subscriber_email=ursula_le_guin@gmail.com,sub
scriber_id=cc96b7d3-40cf-4355-b856-13415718c380,subscriber_name="le guin",target
=zero2prod::routes::subscriptions)
当我们尝试与数据库通信时出现了问题——我们原本期望在 subscription_tokens 表中看到 subscription_token 列, 但不知何故, 它并没有出现。
这其实很有用!
但这是否是导致 500 错误的原因呢?
仅凭查看日志很难判断——开发人员必须克隆代码库,检查日志行的来源,并确保它确实是问题的原因。
这可以做到,但需要时间: 如果 [HTTP REQUEST - END] 日志记录在 exception.details 和 exception.message 中报告一些关于根本原因的有用信息,那就容易多了。
跟踪错误根本原因
要理解为什么 tracing_actix_web 的日志记录如此糟糕,我们需要(再次)检查我们的请求处理程序和 store_token:
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(
form: web::Form<FormData>,
pool: web::Data<PgPool>,
// Get the email client from the app context
email_client: web::Data<EmailClient>,
base_url: web::Data<ApplicationBaseUrl>,
) -> HttpResponse {
// [...]
if store_token(&mut *transaction, subscriber_id, &subscription_token)
.await
.is_err()
{
return HttpResponse::InternalServerError().finish();
}
// [...]
}
pub async fn store_token(
transaction: &mut PgConnection,
subscriber_id: Uuid,
subscription_token: &str,
) -> Result<(), sqlx::Error> {
sqlx::query!(/*[...]*/)
.execute(transaction)
.await
.inspect_err(|e| {
tracing::error!("Failed to execute query: {e:?}");
})?;
Ok(())
}
我们发现的有用错误日志确实是由 tracing::error 调用发出的——错误消息包含由 execute 返回的 sqlx::Error 。
我们使用 ? 运算符向上传播错误,但错误链在 subscribe 中中断——我们丢弃了从 store_token 收到的错误,并构建了一个裸露的 500 响应。
HttpResponse::InternalServerError().finish() 是 actix_web 和
tracing_actix_web::TracingLogger 在即将发出各自的日志记录时唯一能够访问的对象。
该错误不包含任何关于根本原因的上下文,因此日志记录同样毫无用处。
该如何修复它?
我们需要开始利用 actix_web 公开的错误处理机制,特别是
actix_web::Error。根据文档:
actix_web::Error用于以方便的方式通过 actix_web 传输来自std::error的错误。
这听起来正是我们想要的。那么,我们如何构建 actix_web::Error 的实例呢?
文档中提到:
可以通过使用
into()将错误转换为创建actix_web::Error。
有点间接,但我们可以弄清楚。
浏览文档中列出的实现,我们唯一可以使用的 From/Into 实现, 似乎是这个:
/// Build an `actix_web::Error` from any error that implements `ResponseError`
impl<T: ResponseError + 'static> From<T> for Error {
fn from(err: T) -> Error {
Error {
cause: Box::new(err),
}
}
}
ResponseError 是 actix_web 暴露的 trait
pub trait ResponseError: Debug + Display {
// Provided methods
fn status_code(&self) -> StatusCode { ... }
fn error_response(&self) -> HttpResponse<BoxBody> { ... }
}
我们只需要针对错误代码实现它!
actix_web 为这两个方法提供了默认实现, 返回 500 内部服务器错误——这正是我们需要的。因此,只需编写:
//! src/routes/subscriptions.rs
use actix_webL::ResponseError;
// [...]
impl ResponseError for sqlx::Error {}
编译器报错了
error[E0117]: only traits defined in the current crate can be implemented for ty
pes defined outside of the crate
我们刚刚碰到了 Rust 的孤儿规则:禁止为外部类型实现外部特征,其中“foreign”代表“来自另一个 crate”。
此限制旨在保持一致性:想象一下,如果你添加了一个依赖项,它定义了自己的 sqlx::Error 的 ResponseError 实现——当调用特征方法时,编译器应该使用哪一个?
抛开孤儿规则不谈,为 sqlx::Error 实现 ResponseError 仍然是一个错误。
我们希望在尝试持久化订阅者令牌时遇到 sqlx::Error 时返回 500 内部服务器错误。
在其他情况下,我们可能希望以不同的方式处理 sqlx::Error。
我们应该遵循编译器的建议:定义一个新类型来包装 sqlx::Error。
//! src/routes/subscriptions.rs
// [...]
pub async fn store_token(/*[...]*/) -> /*Using the new error type! */ Result<(), StoreTokenError> {
sqlx::query!(
r#"INSERT INTO subscription_tokens (subscription_token, subscriber_id)
VALUES ($1, $2)"#,
subscription_token,
subscriber_id
)
.execute(transaction)
.await
.map_err(|e| {
// [...]
// Wrapping the underlying error
StoreTokenError(e)
})?;
Ok(())
}
// A new error type, wrapping a sqlx::Error
pub struct StoreTokenError(sqlx::Error);
impl ResponseError for StoreTokenError {}
它不起作用,但原因不同:
error[E0277]: `StoreTokenError` doesn't implement `std::fmt::Display`
--> src/routes/subscriptions.rs:118:24
|
118 | impl ResponseError for StoreTokenError {}
| ^^^^^^^^^^^^^^^ the trait `std::fmt::Display` is no
t implemented for `StoreTokenError`
|
StoreTokenError 缺少两个 trait 实现: Debug 和 Display。
这两个 trait 都与格式化有关,但它们的用途不同。
Debug 应该返回面向程序员的表示,尽可能忠实于底层类型结构,以便于调试(顾名思义)。几乎所有公共类型都应该实现 Debug。
而 Display 应该返回面向用户的底层类型表示。大多数类型没有实现 Display,并且无法通过 #[derive(Display)] 属性自动实现。
处理错误时,我们可以这样理解这两个 trait:Debug 返回尽可能多的信息,而 Display 则提供我们遇到的失败的简要描述,并提供必要的上下文。
让我们试试 StoreTokenError:
//! src/routes/subscriptions.rs
// [...]
#[derive(Debug)]
pub struct StoreTokenError(sqlx::Error);
impl ResponseError for StoreTokenError {}
impl std::fmt::Display for StoreTokenError {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
write!(
f,
"A database error was encountered while trying to store a subscription token."
)
}
}
编译通过了!
现在我们可以在请求处理程序中利用它了:
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(
form: web::Form<FormData>,
pool: web::Data<PgPool>,
// Get the email client from the app context
email_client: web::Data<EmailClient>,
base_url: web::Data<ApplicationBaseUrl>,
) -> Result<HttpResponse, actix_web::Error> {
// [...]
// You will have to wrap (early) returns in `Ok(...)` as well!
// The `?` operator transarently invokes the `Into` trait
// on your behalf - we don't need an explicit `map_err` anymore.
store_token(/*[...]*/).await?;
// [...]
}
让我们再次查看日志:
# sqlx logs are a bit spammy, cutting them out to reduce noise
export RUST_LOG="sqlx=error,info"
export TEST_LOG=enabled
cargo t subscribe_fails_if_there_is_a_fatal_database_error | bunyan
exception.details: StoreTokenError(Database(PgDatabaseError { severity: Erro
r, code: "42703", message: "column \"subscription_token\" of relation \"subscrip
tion_tokens\" does not exist", detail: None, hint: None, position: Some(Original
(34)), where: None, schema: None, table: None, column: None, data_type: None, co
nstraint: None, file: Some("parse_target.c"), line: Some(1065), routine: Some("c
heckInsertTargets") }))
好多了!
请求处理结束时发出的日志记录现在包含导致应用程序向用户返回 500 内部服务器错误的详细和简要描述。
查看此日志记录足以准确了解与此请求相关的所有信息。
Error Trait
到目前为止,我们遵循了编译器的建议,并尝试满足 actix-web 在错误处理方面施加的限制。
让我们回过头来看看更大的图景: 在 Rust 中,错误应该是什么样的(不考虑 actix-web 的具体细节)?
Rust 的标准库有一个专用的 trait, Error。
pub trait Error: Debug + Display {
/// Thw lower-level source of this error, if any.
fn source(&self) -> Option<&(dyn Error + 'static)> {
None
}
}
它需要实现 Debug 和 Display 接口,就像 ResponseError 一样。
它还允许我们实现一个 source 方法,该方法返回错误的根本原因(如果有)。
为我们的错误类型实现 Error trait 的意义何在?
Result 不需要它——任何类型都可以用作错误变体。
pub enum Result<T, E> {
/// Contains the success value
Ok(T),
/// Contains the error value
Err(E),
}
Error trait 首先是一种在语义上将我们的类型标记为错误的方法。它可以帮助代码库的读者立即发现其用途。
它也是 Rust 社区标准化良好错误的最低要求的一种方式:
- 它应该提供不同的表示形式(调试和显示),以适应不同的受众
- 应该能够查看错误的根本原因(如果有)(来源)
此列表仍在不断更新 - 例如,有一个不稳定的回溯方法。
错误处理是 Rust 社区中一个活跃的研究领域 - 如果您有兴趣了解接下来的发展,我强烈建议您关注 Rust 错误处理工作组。
通过提供所有可选方法的良好实现,我们可以充分利用错误处理生态系统 - 这些函数已被设计为通用地处理错误。我们将在接下来的几个部分中编写一个!
Trait 对象
在开始实现 source 之前,让我们仔细看看它的
返回值 - Option<&(dyn Error + 'static)>。
dyn Error 是一个 trait 对象 - 除了它实现了 Error trait 之外,我们对这个类型一无所知。
trait 对象,就像泛型类型参数一样,是 Rust 中实现多态性的一种方法:调用同一接口的不同实现。泛型类型在编译时解析(静态调度),而 trait 对象会产生运行时开销(动态调度)。
为什么标准库会返回 trait 对象?
它为开发人员提供了一种访问当前错误的根本原因的方法,同时保持其不透明。
它不会泄露任何关于根本原因类型的信息 - 您只能访问Error trait 公开的方法: 不同的表示形式(Debug、Display),以及使用 source 在错误链中更深入一层的机会。
Error::source
让我们为 StoreTokenError 实现 Error :
//! src/routes/subscriptions.rs
// [...]
impl std::error::Error for StoreTokenError {
fn source(&self) -> Option<&(dyn std::error::Error + 'static)> {
// The compiler transparently casts `&sqlx::Error` into a `&dyn Error`
Some(&self.0)
}
}
在编写需要处理各种错误的代码时,source 非常有用:它提供了一种结构化的方式来导航错误链,而无需了解您正在处理的具体错误类型。
如果我们查看日志记录, StoreTokenError 和 sqlx::Error 之间的因果关系在某种程度上是隐含的——我们推断其中一个是另一个的原因,因为它是另一个的一部分。
[2025-08-31T10:37:05.575Z] ERROR: test/12563 on qby-workspace: [HTTP REQUEST - E
VENT] Error encountered while processing the incoming HTTP request: StoreTokenEr
ror(Database(PgDatabaseError { severity: Error, code: "42703", message: "column
\"subscription_token\" of relation \"subscription_tokens\" does not exist", deta
il: None, hint: None, position: Some(Original(34)), where: None, schema: None, t
able: None, column: None, data_type: None, constraint: None, file: Some("parse_t
arget.c"), line: Some(1065), routine: Some("checkInsertTargets") })) (http.clien
t_ip=127.0.0.1,http.flavor=1.1,http.host=127.0.0.1:41991,http.method=POST,http.r
oute=/subscriptions,http.scheme=http,http.status_code=500,http.target=/subscript
ions,http.user_agent="",line=258,otel.kind=server,otel.name="POST /subscriptions
",otel.status_code=ERROR,request_id=9f312468-2353-43a4-b0be-61c85fdea6d8,target=
tracing_actix_web::middleware)
让我们来看一下更明确的事情:
//! src/routes/subscriptions.rs
// Notice that we have removed `#[derive(Debug)]`
pub struct StoreTokenError(sqlx::Error);
impl std::fmt::Debug for StoreTokenError {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
write!(f, "{}\nCaused by: \n\t{}", self, self.0)
}
}
日志记录现在已经没有什么可想象的了:
exception.details: A database error was encountered while trying to store a
subscription token.
Caused by:
error returned from database: column "subscription_token" of relation "s
ubscription_tokens" does not exist
exception.details 更易于阅读,并且仍然传达了我们之前提到的所有相关信息。
使用 source, 我们可以编写一个函数,为任何实现 Error 的类型提供类似的表示:
//! src/routes/subscriptions.rs
// [...]
fn error_chain_fmt(
e: &impl std::error::Error,
f: &mut std::fmt::Formatter<'_>,
) -> std::fmt::Result {
writeln!(f, "{}\n", e)?;
let mut current = e.source();
while let Some(cause) = current {
writeln!(f, "Caused by:\n\t{cause}")?;
current = cause.source();
}
Ok(())
}
它会遍历导致我们尝试打印失败的整个错误链。
然后,我们可以修改 StoreTokenError 的 Debug 实现来使用它:
//! src/routes/subscriptions.rs
// [...]
impl std::fmt::Debug for StoreTokenError {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
error_chain_fmt(self, f)
}
}
结果是相同的——如果我们想要类似的 Debug 表示,我们可以在处理其他错误时重用它。
控制流错误
分层
我们实现了想要的结果(有用的日志),但我不太喜欢这个解决方案:我们从 Web 框架中实现了一个trait (ResponseError), 用于处理由一个完全不了解 REST 或 HTTP 协议的操作(store_token)返回的错误类型。我们可以从其他入口点(例如 CLI)调用 store_token——它的实现应该没有任何改变。
即使假设我们只会在 REST API 上下文中调用 store_token,我们也可能会添加依赖于该例程的其他端点——它们可能不希望在失败时返回 500。
在发生错误时选择合适的 HTTP 状态码是请求处理程序需要考虑的问题,它不应该泄露到其他地方。
让我们删除
//! src/routes/subscriptions.rs
// [...]
// Nuke it!
impl ResponseError for StoreTokenError {}
为了强制执行适当的关注点分离,我们需要引入另一种错误类型: SubscribeError。
我们将使用它作为 subscribe 的失败变体,并负责 HTTP 相关的逻辑 (ResponseError 的实现)。
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(/* */) -> Result<HttpResponse, SubscribeError> {
// [...]
}
#[derive(Debug)]
struct SubscribeError {}
impl std::fmt::Display for SubscriberError {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
write!(
f,
"Failed to create a new subscriber."
)
}
}
impl std::error::Error for SubscriberError {}
impl ResponseError for SubscriberError {}
如果你运行 cargo check, 你会看到大量的 '?', 无法将错误转换为 SubscribeError ——我们需要实现函数返回的错误类型与 SubscribeError 之间的转换。
将错误建模为枚举
枚举是解决这个问题最常用的方法: 为我们需要处理的每个错误类型提供一个变体。
//! src/routes/subscriptions.rs
// [...]
#[derive(Debug)]
pub enum SubscribeError {
ValidationError(String),
DatabaseError(sqlx::Error),
StoreTokenError(StoreTokenError),
SendEmailError(reqwest::Error),
}
impl ResponseError for SubscribeError {}
impl std::error::Error for SubscribeError {}
impl std::fmt::Display for SubscribeError {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
write!(f, "Failed to create a new subscriber.")
}
}
然后,我们可以在处理程序中利用 ? 运算符,为每个包装的错误类型提供一个 From 实现:
//! src/routes/subscriptions.rs
// [...]
impl From<reqwest::Error> for SubscribeError {
fn from(value: reqwest::Error) -> Self {
Self::SendEmailError(value)
}
}
impl From<sqlx::Error> for SubscribeError {
fn from(e: sqlx::Error) -> Self {
Self::DatabaseError(e)
}
}
impl From<StoreTokenError> for SubscribeError {
fn from(e: StoreTokenError) -> Self {
Self::StoreTokenError(e)
}
}
impl From<String> for SubscribeError {
fn from(e: String) -> Self {
Self::ValidationError(e)
}
}
现在,我们可以通过删除所有 match / if fallible_function().is_err() 行来清理我们的请求处理程序:
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(
// [...]
) -> Result<HttpResponse, SubscribeError> {
let new_subscriber = form.into_inner().try_into()?;
let mut transaction = pool.begin().await?;
let subscriber_id = insert_subscriber(&mut *transaction, &new_subscriber).await?;
let subscription_token = generate_subscription_token();
store_token(/*[...]*/).await?;
transaction.commit().await?;
// Pass the applicaiton url
send_confirmation_email(/*[...]*/).await?;
Ok(HttpResponse::Ok().finish())
}
代码可以编译,但是我们的一个测试失败了:
thread 'subscriptions::subscribe_returns_a_200_when_fields_are_present_but_inval
id' panicked at tests/api/subscriptions.rs:93:9:
assertion `left == right` failed: The API did not return a 400 OK when the paylo
ad was empty name.
left: 400
right: 500
我们仍然使用 ResponseError 的默认实现——它总是返回 500。
这就是枚举的亮点:我们可以使用 match 语句来控制流——根据我们处理的失败场景,我们会采取不同的行为。
//! src/routes/subscriptions.rs
use actix_web::http::StatusCode;
// [...]
impl ResponseError for SubscribeError {
fn status_code(&self) -> actix_web::http::StatusCode {
match self {
SubscribeError::ValidationError(_) => StatusCode::BAD_REQUEST,
SubscribeError::DatabaseError(_)
| SubscribeError::StoreTokenError(_)
| SubscribeError::SendEmailError(_) => StatusCode::INTERNAL_SERVER_ERROR,
}
}
}
测试应该会再次通过。
错误类型还不足够
我们的日志怎么样?
我们再来看看:
export RUST_LOG="sqlx=error,info"
export TEST_LOG=enabled
cargo t subscribe_fails_if_there_is_a_fatal_database_error | bunyan
exception.details: StoreTokenError(A database error was encountered while tr
ying to store a subscription token.
Caused by:
error returned from database: column "subscription_token" of relation "s
ubscription_tokens" does not exist
我们仍然可以在 exception.details 中很好地表示底层的 StoreTokenError, 但它显示我们现在正在使用派生的 Debug 实现来处理 SubscribeError。不过,
信息没有丢失。
但 exception.message 的情况则不同——无论失败模式如何,我们总是会收到“无法创建新订阅者”的错误信息。这不太实用。
让我们改进一下 Debug 和 Display 的实现:
//! src/routes/subscriptions.rs
// [...]
// Remember to delete `#[derive(Debug)]`!
impl std::fmt::Debug for SubscribeError {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
error_chain_fmt(self, f)
}
}
impl std::error::Error for SubscribeError {
fn source(&self) -> Option<&(dyn std::error::Error + 'static)> {
match self {
// &str does not implement `Error` - we consider it the root cause
SubscribeError::ValidationError(_) => None,
SubscribeError::DatabaseError(e) => Some(e),
SubscribeError::StoreTokenError(e) => Some(e),
SubscribeError::SendEmailError(e) => Some(e),
}
}
}
impl std::fmt::Display for SubscribeError {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
match self {
SubscribeError::ValidationError(e) => write!(f, "{}", e),
// What should we do here?
SubscribeError::DatabaseError(_) => write!(f, "???"),
SubscribeError::StoreTokenError(_) => write!(
f,
"Failed to store the confirmation token for a new subscriber."
),
SubscribeError::SendEmailError(_) => {
write!(f, "Failed to send a confirmation email.")
}
}
}
}
Debug 很容易排序: 我们为 SubscribeError 实现了 Error trait,包括 source, 并且我们可以再次使用之前为 StoreTokenError 编写的辅助函数。
在 Display 方面,我们遇到了一个问题——相同的 DatabaseError 变体用于以下情况下遇到的错误:
- 从池中获取新的 Postgres 连接
- 在订阅者表中插入订阅者
- 提交 SQL 事务
在为 SubscribeError 实现 Display 时,我们无法区分我们正在处理的是这三种情况中的哪一种——底层错误类型是不够的。
让我们通过为每个操作使用不同的枚举变体来消除歧义:
//! src/routes/subscriptions.rs
// [...]
pub enum SubscribeError {
// [...]
// No more `DatabaseError`
PoolError(sqlx::Error),
InsertSubscriberError(sqlx::Error),
TransactionCommitError(sqlx::Error),
}
impl std::error::Error for SubscribeError {
fn source(&self) -> Option<&(dyn std::error::Error + 'static)> {
match self {
// [...]
// No more DatabaseError
SubscribeError::PoolError(e) => Some(e),
SubscribeError::InsertSubscriberError(e) => Some(e),
SubscribeError::TransactionCommitError(e) => Some(e),
}
}
}
impl std::fmt::Display for SubscribeError {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
match self {
// [...]
// No more DatabaseError
SubscribeError::PoolError(_) => {
write!(f, "Failed to acquire a Postgres connection from the pool")
}
SubscribeError::InsertSubscriberError(_) => {
write!(f, "Failed to insert new subscriber in the database.")
}
SubscribeError::TransactionCommitError(_) => {
write!(
f,
"Failed to commit SQL transaction to store a new subscriber."
)
}
}
}
}
impl ResponseError for SubscribeError {
fn status_code(&self) -> actix_web::http::StatusCode {
match self {
SubscribeError::ValidationError(_) => StatusCode::BAD_REQUEST,
SubscribeError::TransactionCommitError(_)
| SubscribeError::InsertSubscriberError(_)
| SubscribeError::PoolError(_)
| SubscribeError::StoreTokenError(_)
| SubscribeError::SendEmailError(_) => StatusCode::INTERNAL_SERVER_ERROR,
}
}
}
DatabaseError 还在另一个地方使用:
//! src/routes/subscriptions.rs
// [...]
impl From<sqlx::Error> for SubscribeError {
fn from(e: sqlx::Error) -> Self {
Self::DatabaseError(e)
}
}
仅凭类型不足以区分应该使用哪种新变体;我们无法为 sqlx::Error 实现 From。
我们必须使用 map_err 在每种情况下执行正确的转换。
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(
form: web::Form<FormData>,
pool: web::Data<PgPool>,
// Get the email client from the app context
email_client: web::Data<EmailClient>,
base_url: web::Data<ApplicationBaseUrl>,
) -> Result<HttpResponse, SubscribeError> {
// [...]
let mut transaction = pool.begin().await
.map_err(SubscribeError::PoolError)?;
let subscriber_id = insert_subscriber(/* */).await
.map_err(SubscribeError::InsertSubscriberError)?;
// [...]
store_token(/* */).await?;
transaction.commit().await
.map_err(SubscribeError::TransactionCommitError)?;
// [...]
}
代码编译后, exception.message 再次变得有用:
exception.details: Failed to store the confirmation token for a new subscrib
er.
Caused by:
A database error was encountered while trying to store a subscription to
ken.
Caused by:
error returned from database: column "subscription_token" of relation "s
ubscription_tokens" does not exist
使用 thiserror 移除模板代码
我们花了大约 90 行代码来实现 SubscriberError 及其周围的所有机制,以便实现所需的行为并在日志中获得有用的诊断信息。
这代码量很大,包含大量样板代码(例如源代码或 From 的实现)。
我们能做得更好吗?
嗯,我不确定我们能否编写更少的代码,但我们可以找到另一种方法:我们可以使用宏来生成所有这些样板代码!
碰巧的是,生态系统中已经有一个很棒的 crate 用于此目的: thiserror。让我们将它添加到我们的依赖项中:
cargo add thiserror
它提供了一个 derive 宏,可以生成我们刚刚手写的大部分代码。
我们来看看它的实际效果:
//! src/routes/subscriptions.rs
// [...]
#[derive(thiserror::Error)]
pub enum SubscribeError {
#[error("{0}")]
ValidationError(String),
#[error("Failed to store the confirmation token for a new subscriber.")]
StoreTokenError(#[from] StoreTokenError),
#[error("Failed to send a confirmation email.")]
SendEmailError(#[from] reqwest::Error),
#[error("Failed to acquire a Postgres connection from the pool")]
PoolError(#[source] sqlx::Error),
#[error("Failed to insert new subscriber in the database.")]
InsertSubscriberError(#[source] sqlx::Error),
#[error("Failed to commit SQL transaction to store a new subscriber")]
TransactionCommitError(#[source] sqlx::Error),
}
// We are still using a bespoke implementation of `Debug`
// to get a nice report using the error source chain
impl std::fmt::Debug for SubscribeError {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
error_chain_fmt(self, f)
}
}
pub async fn subscribe(
// [...]
) -> Result<HttpResponse, SubscribeError> {
let new_subscriber = form.into_inner().try_into()
.map_err(SubscribeError::ValidationError)?;
// [...]
}
我们把它精简到了 21 行——还不错!
让我们来分析一下现在的情况。
thiserror::Error 是一个通过 #[derive(/* */)] 属性使用的过程宏。
我们之前见过并使用过这些宏,例如 #[derive(Debug)] 或 #[derive(serde::Serialize)]。
该宏在编译时接收 SubscribeError 的定义作为输入,并返回另一个 token 流作为输出——它会生成新的 Rust 代码,然后将其编译成最终的二进制文件。
在 #[derive(thiserror::Error)] 的上下文中,我们可以访问其他属性来实现我们想要的行为:
#[error(/* */)]定义了它所应用到的枚举变量的 Display 表示形式。例如,当在SubscribeError::SendEmailError的实例上调用Display时,它将返回Failed to send a confirmed email.。你可以在最终表示形式中插入值,例如ValidationError 之上#[error("{0}")]中的 {0} 指的是包装的字符串字段,模仿了访问元组结构体(例如 self.0)字段的语法。#[source]用于表示 Error::source 中应返回的根本原因;#[from]自动将 From 的实现派生为所应用类型的顶级错误类型(例如,impl From<StoreTokenError> for SubscribeError {/* */})。带有#[from]注解的字段也用作错误源,这样我们就不必在同一个字段上使用两个注解了(例如,#[source]#[from] reqwest::Error)。
我想提醒您注意一个小细节: 我们没有对 ValidationError 变体使用 #[from] 或 #[source]。这是因为 String 没有实现 Error trait,因此它无法在 Error::source 中返回——这与我们之前手动实现 Error::source 时遇到的限制相同,导致我们在 ValidationError 的情况下返回 None。
避免“泥球”错误枚举
在 SubscribeError 中我们使用枚举变量有两个目的:
- 确定应返回给 API 调用者的响应 (
ResponseError) - 提供相关的诊断信息 (
Error::source、Debug、Display)。
目前定义的 SubscribeError 暴露了 subscribe 的大量实现细节:我们在请求处理程序中,每个可能出错的函数调用都有一个对应的变体!
这种策略的扩展性并不好。
我们需要从抽象层的角度来思考:subscribe 的调用者需要知道什么?
他们应该能够确定要返回给用户的响应(通过 ResponseError)。就是这样。
subscribe 的调用者不了解订阅流程的复杂性:他们对领域了解不够,无法对 SendEmailError 和 TransactionCommitError 做出不同的行为(设计如此!)。subscribe 应该返回一个在正确抽象层级上表达的错误类型。
理想的错误类型如下所示:
//! src/routes/subscriptions.rs
// [...]
#[derive(thiserror::Error)]
pub enum SubscribeError {
#[error("{0}")]
ValidationError(String),
#[error(/* */)]
UnexpectedError(/* */),
}
ValidationError 映射到 400 Bad Request, UnexpectedError 映射到不透明的 500 Internal Server Error。
我们应该在 UnexpectedError 变量中存储什么?
我们需要将多种错误类型映射到它——sqlx::Error、StoreTokenError 和 reqwest::Error。
我们不想暴露通过 subscribe 映射到 UnexpectedError 的易错例程的实现细节——它必须是不透明的。
在查看 Rust 标准库中的 Error trait 时,我们偶然发现了一个满足这些要求的类型: Box<dyn std::error::Error> !
让我们试一试:
//! src/routes/subscriptions.rss
#[derive(thiserror::Error)]
pub enum SubscribeError {
#[error("{0}")]
ValidationError(String),
// Transparent delegates both `Display`'s and `source`s implementation
// to the type wrapped by `UnexpectedError`
#[error(transparent)]
UnexpectedError(#[from] Box<dyn std::error::Error>)
}
我们仍然可以为呼叫者生成准确的响应:
//! src/routes/subscriptions.rs
// [...]
impl ResponseError for SubscribeError {
fn status_code(&self) -> actix_web::http::StatusCode {
match self {
SubscribeError::ValidationError(_) => StatusCode::BAD_REQUEST,
SubscribeError::UnexpectedError(_) => StatusCode::INTERNAL_SERVER_ERROR,
}
}
}
我们只需要在使用 ? 运算符之前调整 subscribe 方法以正确转换我们的错误:
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(
form: web::Form<FormData>,
pool: web::Data<PgPool>,
// Get the email client from the app context
email_client: web::Data<EmailClient>,
base_url: web::Data<ApplicationBaseUrl>,
) -> Result<HttpResponse, SubscribeError> {
let new_subscriber = form
.into_inner()
.try_into()
.map_err(SubscribeError::ValidationError)?;
let mut transaction = pool.begin()
.await
.map_err(|e| SubscribeError::UnexpectedError(Box::new(e)))?;
let subscriber_id = insert_subscriber(/* */)
.await
.map_err(|e| SubscribeError::UnexpectedError(Box::new(e)))?;
// [...]
store_token(/**/)
.await
.map_err(|e| SubscribeError::UnexpectedError(Box::new(e)))?;
transaction
.commit()
.await
.map_err(|e| SubscribeError::UnexpectedError(Box::new(e)))?;
send_confirmation_email(/* */)
.await
.map_err(|e| SubscribeError::UnexpectedError(Box::new(e)))?;
Ok(HttpResponse::Ok().finish())
}
代码有些重复,但暂时先这样吧。
代码编译通过,测试也按预期通过。
让我们修改一下之前用来检查日志消息质量的测试: 在 insert_subscriber 中触发一个失败,而不是在 store_token 中。
//! tests/api/subscriptions.rs
// [...]
#[tokio::test]
async fn subscribe_fails_if_there_is_a_fatal_database_error() {
// [...]
sqlx::query!("ALTER TABLE subscriptions DROP COLUMN email;",)
.execute(&app.db_pool)
.await
.unwrap();
// [...]
}
测试通过了,但是我们可以看到我们的日志已经倒退了:
exception.details: error returned from database: column "email" of relation
"subscriptions" does not exist
Caused by:
column "email" of relation "subscriptions" does not exist
我们再也看不到原因链了。
我们丢失了之前附加到 InsertSubscriberError 的、对操作员友好的错误消息,通过这个错误:
//! src/routes/subscriptions.rs
// [...]
#[derive(thiserror::Error)]
pub enum SubscribeError {
#[error("Failed to insert new subscriber in the database.")]
InsertSubscriberError(#[source] sqlx::Error),
// [...]
}
这是意料之中的:我们现在将原始错误转发到 Display (通过 #[error(transparent)]),
我们没有在 subscribe 中附加任何额外的上下文。
我们可以解决这个问题——让我们在 UnexpectedError 中添加一个新的字符串字段,以便将上下文信息附加到我们存储的不透明错误中:
//! src/routes/subscriptions.rs
// [...]
#[derive(thiserror::Error)]
pub enum SubscribeError {
#[error("{0}")]
ValidationError(String),
// Transparent delegates both `Display`'s and `source`s implementation
// to the type wrapped by `UnexceptedError`
#[error("{1}")]
UnexpectedError(#[source] Box<dyn std::error::Error>, String),
}
impl ResponseError for SubscribeError {
fn status_code(&self) -> actix_web::http::StatusCode {
match self {
// The cariant now has two fields, we need an extra `_`
SubscribeError::UnexpectedError(_, _) => StatusCode::INTERNAL_SERVER_ERROR,
}
}
}
我们需要相应地调整 subscribe 中的映射代码——我们将重用重构 SubscribeError 之前的错误描述:
//! src/routes/subscriptions.rs
// [...]
pub async fn subscribe(
form: web::Form<FormData>,
pool: web::Data<PgPool>,
// Get the email client from the app context
email_client: web::Data<EmailClient>,
base_url: web::Data<ApplicationBaseUrl>,
) -> Result<HttpResponse, SubscribeError> {
// [...]
let mut transaction = pool.begin().await.map_err(|e| {
SubscribeError::UnexpectedError(
Box::new(e),
"Failed to acquire a Postgres conneciton from the pool".into(),
)
})?;
let subscriber_id = insert_subscriber(/* */)
.await
.map_err(|e| {
SubscribeError::UnexpectedError(
Box::new(e),
"Failed to insert new subscriber in the database.".into(),
)
})?;
// [...]
store_token(/* */)
.await
.map_err(|e| {
SubscribeError::UnexpectedError(
Box::new(e),
"Failed to store the confirmation token for a new subscriber.".into(),
)
})?;
transaction.commit().await.map_err(|e| {
SubscribeError::UnexpectedError(
Box::new(e),
"Failed to commit SQL transaction to store a new subscriber.".into(),
)
})?;
send_confirmation_email(/* */)
.await
.map_err(|e| {
SubscribeError::UnexpectedError(Box::new(e), "Failed to send a confirmation email.".into())
})?;
Ok(HttpResponse::Ok().finish())
}
虽然有点丑陋,但是可以工作:
[2025-09-01T04:48:01.123Z] ERROR: test/76786 on qby-workspace: [HTTP REQUEST - E
VENT] Error encountered while processing the incoming HTTP request: Failed to in
sert new subscriber in the database.
Caused by:
error returned from database: column "email" of relation "subscriptions"
does not exist
Caused by:
column "email" of relation "subscriptions" does not exist
使用 anyhow 作为不透明错误类型
我们可以花更多时间完善我们刚刚建造的机器,但事实证明这没有必要:
我们可以再次依靠生态系统。
无论如何,thiserror 的作者为我们准备了另一个 crate。
cargo add anyhow
我们正在寻找的类型是 anyhow::Error。引用文档:
anyhow::Error是一个动态错误类型的包装器。anyhow::Error的工作原理与Box<dyn std::error::Error>非常相似,但有以下区别:
anyhow::Error要求错误类型为Send、Sync和'static。anyhow::Error保证即使底层错误类型未提供回溯,也提供回溯。anyhow::Error表示为一个窄指针——长度恰好为一个字,而不是两个。
额外的约束(Send、Sync 和 'static')对我们来说不是问题。
如果我们感兴趣的话,我们很欣赏更紧凑的表示形式和访问回溯的选项。
让我们在 SubscribeError 中将 Box<dyn std::error::Error> 替换为 anyhow::Error:
//! src/routes/subscriptions.rs
// [...]
#[derive(thiserror::Error)]
pub enum SubscribeError {
#[error("{0}")]
ValidationError(String),
// Transparent delegates both `Display`'s and `source`s implementation
// to the type wrapped by `UnexceptedError`
#[error(transparent)]
UnexpectedError(#[from] anyhow::Error),
}
impl ResponseError for SubscribeError {
fn status_code(&self) -> actix_web::http::StatusCode {
match self {
SubscribeError::ValidationError(_) => StatusCode::BAD_REQUEST,
// Back to a single field
SubscribeError::UnexpectedError(_) => StatusCode::INTERNAL_SERVER_ERROR,
}
}
}
我们还删除了 SubscribeError::UnexpectedError 中的第二个 String 字段——它不再是必需的。
anyhow::Error 提供了使用额外上下文来丰富错误信息的功能。
//! src/routes/subscriptions.rs
use anyhow::Context;
// [...]
pub async fn subscribe(
form: web::Form<FormData>,
pool: web::Data<PgPool>,
// Get the email client from the app context
email_client: web::Data<EmailClient>,
base_url: web::Data<ApplicationBaseUrl>,
) -> Result<HttpResponse, SubscribeError> {
// [...]
let mut transaction = pool
.begin()
.await
.context("Failed to acquire a Postgres connection from the pool")?;
let subscriber_id = insert_subscriber(/* */)
.await
.context("Failed to insert new subscriber in the database.")?;
let subscription_token = generate_subscription_token();
store_token(/* */)
.await
.context("Failed to store the confirmation token for a new subscriber.")?;
transaction
.commit()
.await
.context("Failed to commit SQL transaction to store a new subscriber.")?;
send_confirmation_email(/* */)
.await
.context("Failed to send a confirmation email.")?;
Ok(HttpResponse::Ok().finish())
}
context 方法在这里执行双重任务:
- 它将我们方法返回的错误转换为
anyhow::Error - 它围绕调用者的意图,为其添加额外的上下文。
context 由 Context trait 提供——无论如何,它为 Result 实现了它,让我们能够访问
流畅的 API, 从而轻松处理各种易出错的函数。
anyhow 还是 thiserror
我们已经讨论了很多内容——现在是时候解决一个常见的 Rust 误区了:
anyhow 针对应用程序的,而 thiserror 是针对库的。
现在讨论错误处理并不是一个合适的框架。
你需要思考调用者的意图。
你是否期望调用者根据他们遇到的故障模式做出不同的行为?
使用错误枚举,让他们能够匹配不同的变体。引入 thiserror 可以减少样板代码的编写。
你是否期望调用者在发生故障时就放弃? 他们主要关心的是将错误报告给运维人员还是用户?
使用不透明的错误,不要让调用者通过编程方式访问错误内部细节。如果你觉得他们的 API 方便,可以使用 anyhow 或 eyre。
误解源于观察到大多数 Rust 库返回一个错误枚举,
而不是 Box<dyn std::error::Error>(例如 sqlx::Error)。
库的作者不能(或者不想)对用户的意图做出假设。他们避免(在一定程度上)固执己见——如果需要,枚举可以为用户提供更多控制权。
自由是有代价的——界面更加复杂,用户需要筛选 10 多个变体,才能找出哪些(如果有的话)需要特殊处理。
仔细考虑你的用例以及你能做出的假设,以便设计出
最合适的错误类型——有时 Box<dyn std::error::Error> 或 anyhow::Error 是最合适的选择, 即使对于库来说也是如此。
谁应该记录错误
让我们再次看一下请求失败时发出的日志。
# sqlx logs are a bit spammy, cutting them out to reduce noise
export RUST_LOG="sqlx=error,info"
export TEST_LOG=enabled
cargo t subscribe_fails_if_there_is_a_fatal_database_error | bunyan
错误级别的日志记录有三种:
- 一条由 insert_subscriber 中的代码发出
//! src/routes/subscriptions.rs
pub async fn insert_subscriber(
transaction: &mut PgConnection,
new_subscriber: &NewSubscriber,
) -> Result<Uuid, sqlx::Error> {
let subscriber_id = Uuid::new_v4();
sqlx::query!(/* */)
.execute(transaction)
.await
.inspect_err(|e| {
tracing::error!("Failed to execute query: {:?}", e);
})?;
Ok(subscriber_id)
}
- 当将
SubscribeError转换为actix_web::Error时,actix_web输出的错误 - 一个由我们的遥测中间件
tracing_actix_web::TracingLogger发出的
我们不需要看到三次相同的信息——我们发出了不必要的日志记录,这不仅没有帮助,反而让运维人员更加困惑,难以理解正在发生的事情 (这些日志报告的是同一个错误吗?我处理的是三个不同的错误吗?)。
根据经验,
处理错误时应记录错误。
如果您的函数将错误向上传播(例如使用 ? 运算符),则不应记录该错误。如果合理,可以添加更多上下文。
如果错误一直向上传播到请求处理程序,则将日志记录委托给专用的中间件 - 在本例中为 tracing_actix_web::TracingLogger。
actix_web 发出的日志记录将在下一个版本中被移除。我们暂时忽略它。
让我们回顾一下我们自己代码中的 tracing::error 语句:
//! src/routes/subscriptions.rs
// [...]
pub async fn insert_subscriber(
transaction: &mut PgConnection,
new_subscriber: &NewSubscriber,
) -> Result<Uuid, sqlx::Error> {
let subscriber_id = Uuid::new_v4();
sqlx::query!(/* */)
.execute(transaction)
.await
.inspect_err(|e| {
// This needs to go, we are propagating the error via `?`
tracing::error!("Failed to execute query: {:?}", e);
})?;
Ok(subscriber_id)
}
pub async fn store_token(
transaction: &mut PgConnection,
subscriber_id: Uuid,
subscription_token: &str,
) -> Result<(), StoreTokenError> {
sqlx::query!(/* */)
.execute(transaction)
.await
.map_err(|e| StoreTokenError(e))?;
Ok(())
}
再次检查日志以确认它们看起来完好无损。
小结
我们利用本章“艰难地”学习了错误处理模式——首先构建一个丑陋但可运行的原型,然后使用生态系统中流行的 crate 对其进行改进。
现在你应该具备:
- 扎实掌握应用程序中错误实现的不同目的
- 最合适的工具来实现这些目的。
内化我们讨论过的思维模型(位置为列,目的为行):
| Internal | At the edge | |
|---|---|---|
| 控制流报告 | 类型, 方法 , 字段, 日志/跟踪 | 状态码和body |
练习你所学的知识: 我们完成了订阅请求处理程序,并完成了确认操作,作为一项练习来验证你对所涵盖概念的理解。改进表单数据验证失败时返回给用户的响应。
你可以查看 GitHub 仓库 中的代码作为参考实现。
我们在本章中讨论的一些主题(例如分层和抽象边界)将在讨论应用程序的整体布局和结构时再次出现。
值得期待!
简单的新闻通讯发送
我们的项目还无法提供可行的新闻通讯服务:它无法发送新一集!
我们将利用本章通过一个简单的实现来提升新闻通讯的传递能力。
这将使我们有机会加深对前几章中涉及的技术的理解,同时为处理更高级的主题(例如身份验证/授权、容错)奠定基础。
用户故事并非一成不变
我们到底想要实现什么?
我们可以回顾一下我们在第二章中写下的用户故事:
作为博客作者, 我想向所有订阅者发送电子邮件, 以便在发布新内容时通知他们
至少表面上看起来很简单。但魔鬼总是藏在细节里。 例如,在第七章中,我们完善了订阅者的领域模型——现在我们有了已确认和未确认的订阅者。
哪些人应该接收我们的新闻通讯?
目前的用户故事并不能帮助我们——它是在我们开始区分之前编写的!
养成在项目整个生命周期中反复回顾用户故事的习惯。
当你花时间解决一个问题时,你最终会加深对它领域的理解。
你通常会获得一种更精确的语言,可以用来改进之前描述所需功能的尝试。
对于这个具体案例: 我们只希望将新闻通讯发送给已确认的订阅者。让我们相应地修改用户故事:
作为博客作者, 我想向所有已确认的订阅者发送一封电子邮件, 以便在新内容发布时通知他们。
不要给未订阅用户发垃圾邮件
我们可以先编写一个集成测试,明确哪些情况不应该发生:未经确认的订阅者不应该收到新闻通讯。
在第七章中,我们选择了 Postmark 作为我们的电子邮件传递服务。如果我们没有调用 Postmark,就不会发送电子邮件。
我们可以基于此来设计一个场景,以验证我们的业务规则: 如果所有订阅者都未经确认,那么当我们发布新闻通讯时,就不会向 Postmark 发出任何请求。
让我们将其转化为代码:
//! tests/api/main.rs
// [...]
mod newsletter;
//! tests/api/newsletter.rs
tchers::{any, method, path}, Mock, ResponseTemplate};
use crate::helpers::{spawn_app, TestApp};
#[tokio::test]
async fn newsletters_are_not_delivered_to_unconfirmed_subscribers() {
// Arrange
let app = spawn_app().await;
create_unconfirmed_subscriber(&app).await;
Mock::given(any())
.respond_with(ResponseTemplate::new(200))
.expect(0)
.mount(&app.email_server)
.await;
// Act
// A sketch of the newsletter payload structure
// We might change it later on.
let newsletter_request_body = serde_json::json!({
"title": "Newsletter title",
"content": {
"text": "Newsletter body as plain text",
"html": "<p>Newsletter body as HTML</p>",
}
});
let response = reqwest::Client::new()
.post(&format!("{}/newsletters", &app.address))
.json(&newsletter_request_body)
.send()
.await
.expect("Failed to execute request.");
// Assert
assert_eq!(response.status().as_u16(), 200);
// Mock verifies on Drop that we haven't sent the newsletter email
}
/// Use the public API of the application under test to create
/// an unconfirmed subscriber.
async fn create_unconfirmed_subscriber(app: &TestApp) {
let body = "name=le%20guin&email=ursula_le_guin%40gmail.com";
let _mock_guard = Mock::given(path("/email"))
.and(method("POST"))
.respond_with(ResponseTemplate::new(200))
.named("Create unconfirmed subscriber")
.expect(1)
.mount_as_scoped(&app.email_server)
.await;
app.post_subscriptions(body.into())
.await
.error_for_status()
.unwrap();
}
正如预期的那样,它失败了:
thread 'newsletter::newsletters_are_not_delivered_to_unconfirmed_subscribers' pa
nicked at tests/api/newsletter.rs:36:5:
assertion `left == right` failed
left: 404
right: 200
我们的 API 中没有用于 POST /newsletters 的处理程序: actix-web 返回 404 Not Found,而不是测试预期的 200 OK。
使用公共 API 设置状态
让我们花点时间看一下我们刚刚编写的测试的 "Arrange" 部分。
我们的测试场景对应用程序的状态做了一些假设:我们需要一个订阅者,并且该订阅者必须是未确认的。
每个测试都会启动一个全新的应用程序,并在一个空数据库上运行。
let app = spawn_app().await;
我们如何根据测试需求填充它?
我们坚持第三章中描述的黑盒方法: 尽可能通过调用应用程序的公共 API 来驱动应用程序状态。
这就是我们在 create_unconfirmed_subscriber 中所做的:
//! tests/api/newsletter.rs
// [...]
async fn create_unconfirmed_subscriber(app: &TestApp) {
let body = "name=le%20guin&email=ursula_le_guin%40gmail.com";
let _mock_guard = Mock::given(path("/email"))
.and(method("POST"))
.respond_with(ResponseTemplate::new(200))
.named("Create unconfirmed subscriber")
.expect(1)
.mount_as_scoped(&app.email_server)
.await;
app.post_subscriptions(body.into())
.await
.error_for_status()
.unwrap();
}
我们使用在 TestApp 中构建的 API 客户端向 /subscriptions 端点发出 POST 调用。
作用域模拟
我们知道 POST /subscriptions 会发送一封确认邮件——我们必须确保我们的 Postmark 测试服务器已准备好处理传入的请求,为此我们需要设置相应的模拟。
匹配逻辑与测试函数体中的逻辑重叠:我们如何确保这两个模拟不会互相干扰?
我们使用一个作用域模拟:
let _mock_guard = Mock::given(path("/email"))
.and(method("POST"))
.respond_with(ResponseTemplate::new(200))
.named("Create unconfirmed subscriber")
.expect(1)
// We are not using `mount`!
.mount_as_scoped(&app.email_server)
.await;
使用 mount 时,只要底层 MockServer 正常运行,我们指定的行为就会一直有效。
而使用 mount_as_scoped 时,我们会返回一个守护对象——MockGuard。
MockGuard 有一个自定义的 Drop 实现: 当超出范围时, wiremock 会指示底层 MockServer 停止执行指定的模拟行为。换句话说,在 create_unconfirmed_subscriber 的末尾, 我们会停止向 POST /email 返回 200。
我们的测试助手所需的模拟行为仅对测试助手本身有效。
当 MockGuard 被丢弃时,还会发生另一件事——我们会积极地检查作用域模拟的期望是否已得到验证。
这会创建一个有用的反馈循环,以保持我们的测试辅助函数干净且最新。
我们已经见证了黑盒测试如何促使我们为自己的应用程序编写 API 客户端,以保持测试简洁。
随着时间的推移,您会构建越来越多的辅助函数来驱动应用程序状态——就像我们刚才对 create_unconfirmed_subscriber 所做的那样。这些辅助函数依赖于模拟,但随着应用程序的发展,其中一些模拟最终不再需要——例如某个调用被移除,您停止使用某个提供程序等等。
积极地评估作用域模拟的期望有助于我们控制辅助函数代码,并在可能的情况下主动进行清理。
Green 测试
我们可以通过提供 POST /newsletters 的虚拟实现来使测试通过:
//! src/routes.rs
// [...]
mod newsletters;
pub use newsletters::*;
//! src/routes/newsletters.rs
use actix_web::HttpResponse;
pub async fn publish_newsletter() -> HttpResponse {
HttpResponse::Ok().finish()
}
//! src/startup.rs
// [...]
pub fn run(
// [...]
) -> Result<Server, std::io::Error> {
// [...]
let server = HttpServer::new(move || {
App::new()
// [...]
.route("/newsletters", web::post().to(publish_newsletter))
// [...]
})
// [...]
}
cargo test 应该可以通过了。
所有确认订阅者都会收到新刊
让我们再写一个集成测试, 这次针对理想情况的子集: 如果我们有一个确认的订阅者, 他们会收到一封包含新一期新闻通讯的电子邮件。
编写测试助手
与上一个测试一样,我们需要在执行测试逻辑之前将应用程序状态设置为我们想要的状态——它会调用另一个辅助函数,这次是为了创建一个已确认的订阅者。
通过稍微修改 create_unconfirmed_subscriber 函数,我们可以避免重复:
//! tests/api/newsletter.rs
// [...]
/// Use the public API of the application under test to create
/// an unconfirmed subscriber.
async fn create_unconfirmed_subscriber(app: &TestApp) -> ConfirmationLinks {
let body = "name=le%20guin&email=ursula_le_guin%40gmail.com";
let _mock_guard = Mock::given(path("/email"))
.and(method("POST"))
.respond_with(ResponseTemplate::new(200))
.named("Create unconfirmed subscriber")
.expect(1)
.mount_as_scoped(&app.email_server)
.await;
app.post_subscriptions(body.into())
.await
.error_for_status()
.unwrap();
// We now inspect the requests received by the mock Postmark server
// to retrieve the confirmation link and return it
let email_request = &app
.email_server
.received_requests()
.await
.unwrap()
.pop()
.unwrap();
app.get_confirmation_links(email_request)
}
async fn create_confirmed_subscriber(app: &TestApp) {
// We can then reuse the same helper and just add
// an extra step to actually call the confirmation link!
let confirmation_link = create_unconfirmed_subscriber(app).await;
reqwest::get(confirmation_link.html)
.await
.unwrap()
.error_for_status()
.unwrap();
}
我们现有的测试无需任何更改, 并且可以在新测试中立即利用 create_confirmed_subscriber 函数:
//! tests/api/newsletter.rs
// [...]
#[tokio::test]
async fn newsletters_are_delivered_to_confirmed_subscribers() {
// Arrange
let app = spawn_app().await;
create_confirmed_subscriber(&app).await;
Mock::given(path("/email"))
.and(method("POST"))
.respond_with(ResponseTemplate::new(200))
.expect(1)
.mount(&app.email_server)
.await;
// Act
let newsletter_request_body = serde_json::json!({
"title": "Newsletter title",
"content": {
"text": "Newsletter body as plain text",
"html": "<p>Newsletter body as HTML</p>",
}
});
let response = reqwest::Client::new()
.post(&format!("{}/newsletters", &app.address))
.json(&newsletter_request_body)
.send()
.await
.expect("Failed to execute request.");
// Assert
assert_eq!(response.status().as_u16(), 200);
// Mock verifies on Drop that we have sent the newsletter email
}
它失败了,正如它应该的那样:
Verifications failed:
- Mock #1.
Expected range of matching incoming requests: == 1
Number of matched incoming requests: 0
实现的策略
我们已经完成了足够多的测试, 可以收集反馈了——让我们开始实施吧!
我们将从一个简单的方法开始:
- 从传入的 API 调用正文中检索新闻通讯的发行详情
- 从数据库中获取所有已确认订阅者的列表
- 遍历整个列表:
- 获取订阅者的电子邮件地址
- 通过 Postmark 发送电子邮件
开始吧!
Body 结构
为了发送新闻通讯,我们需要了解哪些信息?
如果我们力求使其尽可能简洁:
- 标题,用作电子邮件主题
- 内容,以 HTML 和纯文本形式呈现,以满足所有电子邮件客户端的需求。
我们可以使用派生自 serde::Deserialize 的结构体来编码我们的需求,就像我们在 POST /subscriptions 中使用 FormData 进行编码一样。
//! src/routes/newsletters.rs
// [...]
#[derive(serde::Deserialize)]
pub struct BodyData {
title: String,
content: Content,
}
#[derive(serde::Deserialize)]
pub struct Content {
html: String,
text: String,
}
由于 BodyData 中的所有字段类型都实现了 serde::Deserialize, 因此 serde 对我们的嵌套布局没有任何问题。然后,我们可以使用 actix-web 提取器从传入的请求正文中解析出 BodyData。只有一个问题需要回答:我们使用什么序列化格式?
对于 POST /subscriptions, 由于我们处理的是 HTML 表单,我们使用 application/x-www-form-urlencode
作为 Content-Type。
对于 POST /newsletters, 我们不受网页中嵌入表单的约束: 我们将使用 JSON,这是构建 REST API 时的常见选择。
相应的提取器是 actix_web::web::Json:
//! src/routes/newsletters.rs
// [...]
use actix_web::web;
// We are prefixing `body` with a `_` to avoid
// a compiler warning about unused arguments
pub async fn publish_newsletter(_body: web::Json<BodyData>) -> HttpResponse {
HttpResponse::Ok().finish()
}
测试不合法输入
信任但要验证: 让我们添加一个新的测试用例, 在 POST /newsletters 端点抛出无效数据。
//! tests/api/newsletter.rs
// [...]
#[tokio::test]
async fn newsletters_returns_400_for_invalid_data() {
// Arrange
let app = spawn_app().await;
let test_cases = vec![
(
serde_json::json!({
"content": {
"text": "Newsletter body as plain text",
"html": "<p>Newsletter body as HTML</p>",
}
}),
"missing title",
),
(
serde_json::json!({"title": "Newsletter!"}),
"missing content",
),
];
for (invalid_body, error_message) in test_cases {
let response = reqwest::Client::new()
.post(&format!("{}/newsletters", &app.address))
.json(&invalid_body)
.send()
.await
.expect("Failed to execute request.");
// Assert
assert_eq!(
400,
response.status().as_u16(),
"The API did not fail with 400 Bad Request when the payload was {}.",
error_message
)
}
}
新的测试通过了——如果你愿意,还可以添加一些用例。
让我们抓住机会稍微重构一下,删除一些重复的代码——我们可以将触发 POST /newsletters 请求的逻辑提取到 TestApp 上的一个共享辅助方法中,就像我们对 POST /subscriptions 所做的那样:
//! tests/api/helpers.rs
// [...]
impl TestApp {
// [...]
pub async fn post_newsletters(&self, body: serde_json::Value) -> reqwest::Response {
reqwest::Client::new()
.post(&format!("{}/newsletters", &self.address))
.json(&body)
.send()
.await
.expect("Failed to execute request.")
}
}
//! tests/api/newsletter.rs
// [...]
async fn newsletters_are_delivered_to_confirmed_subscribers() {
// [...]
let response = app.post_newsletters(newsletter_request_body).await;
// [...]
}
async fn newsletters_returns_400_for_invalid_data() {
// Arrange
// [...]
for (invalid_body, error_message) in test_cases {
let response = app.post_newsletters(invalid_body).await;
// Assert
// [...]
}
}
async fn newsletters_are_not_delivered_to_unconfirmed_subscribers() {
// Arrange
// [...]
let response = app.post_newsletters(newsletter_request_body).await;
// Assert
// [...]
}
获取已确认订阅者列表
我们需要编写一个新的查询来检索所有已确认订阅者的列表。
状态列上的 WHERE 子句足以隔离我们关心的行:
//! src/routes/newsletters.rs
// [...]
struct ConfirmedSubscriber {
email: String,
}
#[tracing::instrument(name = "Get confirmed subscribers", skip(pool))]
async fn get_confirmed_subscribers(
pool: &PgPool,
) -> Result<Vec<ConfirmedSubscriber>, anyhow::Error> {
let rows = sqlx::query_as!(
ConfirmedSubscriber,
r#"
SELECT email
FROM subscriptions
WHERE status = 'confirmed'
"#,
)
.fetch_all(pool)
.await?;
Ok(rows)
}
这里有一些新特性:我们使用 sqlx::query_as! 而不是 sqlx::query!。
sqlx::query_as! 将检索到的行映射到其第一个参数指定的类型, ConfirmedSubscriber, 从而省去了我们大量的样板代码。
请注意, ConfirmedSubscriber 只有一个字段 - email。我们正在最小化从数据库获取的数据量,将查询限制在实际需要发送新闻通讯的列上。数据库的工作量更少,网络上传输的数据也更少。
在这种情况下,这不会带来明显的区别,但在处理数据占用空间更大的大型应用程序时,牢记这一点是一个好习惯。
为了在我们的处理程序中使用 get_confirmed_subscribers, 我们需要一个 PgPool——我们可以从应用程序状态中提取一个,就像我们在 POST /subscriptions 中所做的那样。
//! src/routes/newsletters.rs
// [...]
pub async fn publish_newsletter(
_body: web::Json<BodyData>,
pool: web::Data<PgPool>,
) -> HttpResponse {
let _subscribers = get_confirmed_subscribers(&pool).await?;
HttpResponse::Ok().finish()
}
这并不能编译通过:
--> src/routes/newsletters.rs:24:62
|
23 | ) -> HttpResponse {
| ___________________-
24 | | let _subscribers = get_confirmed_subscribers(&pool).await?;
| | ^ cannot use
the `?` operator in an async function that returns `HttpResponse`
25 | | HttpResponse::Ok().finish()
26 | | }
| |_- this function should return `Result` or `Option` to accept `?`
SQL 查询可能会失败, get_confirmed_subscribers 也可能会失败——我们需要更改 publish_newsletter 的返回类型。
我们需要返回一个带有适当错误类型的 Result, 就像我们在上一章中所做的那样:
//! src/routes/newsletters.rs
// [...]
use actix_web::{http::StatusCode, web, HttpResponse, ResponseError};
use sqlx::PgPool;
use crate::routes::error_chain_fmt;
#[derive(thiserror::Error)]
pub enum PublishError {
#[error(transparent)]
UnexpectedError(#[from] anyhow::Error),
}
// Same logic to get the full error chain on `Debug`
impl std::fmt::Debug for PublishError {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
error_chain_fmt(self, f)
}
}
impl ResponseError for PublishError {
fn status_code(&self) -> actix_web::http::StatusCode {
match self {
PublishError::UnexpectedError(_) => StatusCode::INTERNAL_SERVER_ERROR,
}
}
}
pub async fn publish_newsletter(
_body: web::Json<BodyData>,
pool: web::Data<PgPool>,
) -> Result<HttpResponse, PublishError> {
let _subscribers = get_confirmed_subscribers(&pool).await?;
Ok(HttpResponse::Ok().finish())
}
// [...]
注: 你还需要自己把 error_chain_fmt 移动到 routes.rs 并修改访问修饰符为 pub
利用我们在第 8 章中学到的知识,推出一个新的错误类型并不需要花费太多精力!
需要说明的是,我们正在对代码进行一些面向未来的设计: 我们将 PublishError 建模为枚举, 但目前只有一种变体。结构体 (或 actix_web::error::InternalError)暂时就足够了。
cargo check 现在应该可以通过了。
发送新闻邮件
是时候把邮件发出去了!
我们可以利用前几章写的 EmailClient —— 就像 PgPool 一样,它已经是应用程序状态的一部分了, 我们可以使用 web::Data 来提取它。
//! src/routes/newsletters.rs
// [...]
pub async fn publish_newsletter(
body: web::Json<BodyData>,
pool: web::Data<PgPool>,
// New argument!
email_client: web::Data<EmailClient>,
) -> Result<HttpResponse, PublishError> {
let subscribers = get_confirmed_subscribers(&pool).await?;
for subscriber in subscribers {
email_client
.send_email(
subscriber.email,
&body.title,
&body.content.html,
&body.content.text,
)
.await?;
}
Ok(HttpResponse::Ok().finish())
}
差一点就能工作:
error[E0308]: mismatched types
--> src/routes/newsletters.rs:52:17
|
51 | .send_email(
| ---------- arguments to this method are incorrect
52 | subscriber.email,
| ^^^^^^^^^^^^^^^^ expected `SubscriberEmail`, found `String`
|
error[E0277]: `?` couldn't convert the error to `PublishError`
--> src/routes/newsletters.rs:57:19
|
50 | / email_client
51 | | .send_email(
52 | | subscriber.email,
53 | | &body.title,
... |
57 | | .await?;
| | -^ unsatisfied trait bound
| |__________________|
| this can't be annotated with `?` because it has type `Re
sult<_, reqwest::Error>`
context Vs with_context
我们可以快速修复第二个错误
//! src/routes/newsletters.rs
// [...]
// Bring anyhow's extension trait into scope!
use anyhow::Context;
pub async fn publish_newsletter(
body: web::Json<BodyData>,
pool: web::Data<PgPool>,
email_client: web::Data<EmailClient>,
) -> Result<HttpResponse, PublishError> {
let subscribers = get_confirmed_subscribers(&pool).await?;
for subscriber in subscribers {
email_client
.send_email(/* */)
.await
.with_context(|| {
format!("Failed to send newsletter issue to {}", subscriber.email)
})?;
}
Ok(HttpResponse::Ok().finish())
}
// [...]
我们正在使用一个新方法, with_context。
它与 context 密切相关,后者是我们在第 8 章中广泛使用的方法,用于将 Result 的错误版本转换为 anyhow::Error, 同时用上下文信息丰富它。
两者之间有一个关键区别: with_context 是惰性的。
它接受一个闭包作为参数,并且只有在发生错误时才会调用该闭包。
如果您添加的上下文是静态的 - 例如 context("Oh no!") - 它们等效。
如果您添加的上下文有运行时开销,请使用 with_context - 这样可以避免在易出错的操作成功时为错误路径付出代价。
让我们以我们的情况为例: format! 在堆上分配内存来存储其输出字符串。使用 context, 我们每次发送电子邮件时都会分配该字符串。
而使用 with_context, 我们只有在电子邮件发送失败时才会调用 format!。
存储数据的验证
cargo check 现在应该返回一个错误:
error[E0308]: mismatched types
--> src/routes/newsletters.rs:53:17
|
52 | .send_email(
| ---------- arguments to this method are incorrect
53 | subscriber.email,
| ^^^^^^^^^^^^^^^^ expected `SubscriberEmail`, found `String`
|
我们没有对从数据库中检索的数据进行任何验证 - ConfirmedSubscriber::email 是字符串类型。
相反, EmailClient::send_email 需要一个经过验证的电子邮件地址 - 一个 SubscriberEmail 实例。
我们可以先尝试一个简单的解决方案 - 将 ConfirmedSubscriber::email 更改为 SubscriberEmail 类型。
//! src/routes/newsletters.rs
// [...]
struct ConfirmedSubscriber {
email: SubscriberEmail,
}
sqlx 似乎不是很喜欢这个类型, 它不知道怎么把 TEXT 转换为 SubscriberEmail
error[E0277]: the trait bound `SubscriberEmail: From<String>` is not satisfied
--> src/routes/newsletters.rs:70:16
|
70 | let rows = sqlx::query_as!(
| ________________^
71 | | ConfirmedSubscriber,
72 | | r#"
73 | | SELECT email
... |
76 | | "#,
77 | | )
| |_____^ unsatisfied trait bound
|
我们可以浏览 sqlx 的文档,寻找实现自定义类型支持的方法——虽然麻烦不少,但好处却不多。
我们可以采用与 POST /subscriptions 端点类似的方法—— 我们使用两个结构体:
- 一个结构体编码了我们期望传输的数据布局 (FormData);
- 另一个结构体通过使用我们的域类型解析原始表示来构建(
NewSubscriber)。
对于我们的查询,它看起来像这样:
//! src/routes/newsletters.rs
// [...]
#[tracing::instrument(name = "Get confirmed subscribers", skip(pool))]
async fn get_confirmed_subscribers(
pool: &PgPool,
) -> Result<Vec<ConfirmedSubscriber>, anyhow::Error> {
// We only need `Row` to map the data coming out of this query.
// Nesting its definition inside the function itself is a simple way
// to clearly communicate this coupling (and to ensure it doesn't
// get used elsewhere by mistake).
struct Row {
email: String,
}
let rows = sqlx::query_as!(
Row,
r#"
SELECT email
FROM subscriptions
WHERE status = 'confirmed'
"#,
)
.fetch_all(pool)
.await?;
// Map into the domain type
let confirmed_subscribers = rows
.into_iter()
.map(|r| ConfirmedSubscriber {
email: SubscriberEmail::parse(r.email).unwrap(),
})
.collect();
Ok(confirmed_subscribers)
}
SubscriberEmail::parse(r.email).unwrap() 是个好主意吗?
所有新订阅者的邮件都会经过 SubscriberEmail::parse 中的验证逻辑——这是我们第六章重点讨论的主题。
那么,你可能会争辩说,我们数据库中存储的所有邮件必然都是有效的——这里无需考虑验证失败的情况。直接将它们全部解包就很安全了,因为它永远不会崩溃。
假设我们的软件永远不会更改,这种推理是合理的。但我们正在针对高部署频率进行优化!
存储在 Postgres 实例中的数据会在应用程序的新旧版本之间创建时间耦合。
我们从数据库中检索的邮件已被应用程序的先前版本标记为有效。当前版本可能不同意。
例如,我们可能会发现我们的邮件验证逻辑过于宽松——一些无效的邮件漏掉了,导致在尝试发送新闻通讯时出现问题。我们实施了更严格的验证例程,并部署了修补版本,突然间,电子邮件投递完全失效了!
get_confirmed_subscribers 在处理之前被认为有效但现在已经失效的已存储电子邮件时会引发 panic。
那么,我们该怎么办?
从数据库检索数据时,是否应该完全跳过验证?
没有一刀切的答案。
您需要根据域的需求,逐个评估问题。
有时处理无效记录是不可接受的——例程应该失败,并且操作员必须介入以纠正损坏的记录。
有时我们需要处理所有历史记录(例如分析数据),并且应该对数据做出最少的假设——String 是我们最安全的选择。
在我们的例子中,我们可以折中一下: 在获取下一期新闻通讯的收件人列表时,我们可以跳过无效的电子邮件。我们将对发现的每个无效地址发出警告,以便操作员识别问题并在未来的某个时间点更正存储的记录。
//! src/routes/newsletters.rs
// [...]
async fn get_confirmed_subscribers(
pool: &PgPool,
) -> Result<Vec<ConfirmedSubscriber>, anyhow::Error> {
// [...]
// Map into the domain type
let confirmed_subscribers = rows
.into_iter()
.filter_map(|r| match SubscriberEmail::parse(r.email) {
Ok(email) => Some(ConfirmedSubscriber { email }),
Err(error) => {
tracing::warn!(
"A confirmed subscriber is using an invalid email address.\n{error}."
);
None
},
})
.collect();
Ok(confirmed_subscribers)
}
filter_map 是一个方便的组合器——它返回一个新的迭代器,其中只包含我们的闭包返回 Some 变量的项。
责任边界
我们可以避免这种情况,但值得花点时间思考一下这里谁在做什么。
当遇到无效的电子邮件地址时, get_confirmed_subscriber 是否是选择跳过或中止的最合适位置?
这感觉像是一个业务层面的决策,最好放在 publish_newsletter 中,它是我们交付工作流的驱动程序。
get_confirmed_subscriber 应该简单地充当存储层和领域层之间的适配器。它处理数据库特定的部分(即查询)和映射逻辑,但它将映射或查询失败时的处理决定委托给调用者。
让我们重构一下:
//! src/routes/newsletters.rs
// [...]
async fn get_confirmed_subscribers(
pool: &PgPool,
// We are returning a `Vec` of `Result`s in the happy case.
// This allows the caller to bubble up errors due to network issues or other
// transient failures using the `?` operator, while the compiler
// forces them to handle the subtler mapping error.
// See http://sled.rs/errors.html for a deep-dive about this technique.
) -> Result<Vec<Result<ConfirmedSubscriber, anyhow::Error>>, anyhow::Error> {
// We only need `Row` to map the data coming out of this query.
// Nesting its definition inside the function itself is a simple way
// to clearly communicate this coupling (and to ensure it doesn't
// get used elsewhere by mistake).
struct Row {
email: String,
}
let rows = sqlx::query_as!(
Row,
r#"
SELECT email
FROM subscriptions
WHERE status = 'confirmed'
"#,
)
.fetch_all(pool)
.await?;
// Map into the domain type
let confirmed_subscribers = rows
.into_iter()
.map(|r| match SubscriberEmail::parse(r.email) {
Ok(email) => Ok(ConfirmedSubscriber { email }),
Err(error) => Err(anyhow::anyhow!(error)),
})
.collect();
Ok(confirmed_subscribers)
}
我们现在在调用点收到编译器错误:
error[E0609]: no field `email` on type `Result<ConfirmedSubscriber, anyhow::Erro
r>`
--> src/routes/newsletters.rs:53:28
|
53 | subscriber.email,
| ^^^^^ unknown field
|
我们可以立即修复:
//! src/routes/newsletters.rs
// [...]
pub async fn publish_newsletter(
body: web::Json<BodyData>,
pool: web::Data<PgPool>,
email_client: web::Data<EmailClient>,
) -> Result<HttpResponse, PublishError> {
let subscribers = get_confirmed_subscribers(&pool).await?;
for subscriber in subscribers {
// The compiler forces us to handle both the happy and unhappy case!
match subscriber {
Ok(subscriber) => {
email_client
.send_email(
subscriber.email,
&body.title,
&body.content.html,
&body.content.text,
)
.await
.with_context(|| {
format!(
"Failed to send newsletter issue to {}",
subscriber.email
)
})?;
}
Err(error) => {
tracing::warn!(
// We record the error chain as a structured field
// on the log record.
error.cause_chain = ?error,
// Userin `\` to split a long string literal over
// two lines, without creating a `\n` character.
"Skipping a confirmed subscriber. \
Their stored contact details are invalid",
)
}
}
}
Ok(HttpResponse::Ok().finish())
}
关注编译器
编译器几乎可以正常工作:
error[E0277]: `SubscriberEmail` doesn't implement `std::fmt::Display`
--> src/routes/newsletters.rs:64:29
|
63 | ... "Failed to send newsletter issue to {}",
| -- required by th
is formatting parameter
64 | ... subscriber.email
| ^^^^^^^^^^^^^^^^ `SubscriberEmail` cannot be formatte
d with the default formatter
|
这是因为我们将 ConfirmedSubscriber 中的电子邮件类型从 String 更改为了 SubscriberEmail。
让我们为新类型实现 Display:
//! src/domain/subscriber_email.rs
// [...]
impl std::fmt::Display for SubscriberEmail {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
// We just forward to the Display implementation of
// the wrapped String
self.0.fmt(f)
}
}
进展顺利! 又一个编译器错误,这次是借用检查器的错误!
error[E0382]: borrow of moved value: `subscriber.email`
--> src/routes/newsletters.rs:61:35
|
55 | subscriber.email,
| ---------------- value moved here
...
61 | .with_context(|| {
| ^^ value borrowed here after move
...
64 | subscriber.email
| ---------------- borrow occurs due to use in cl
osure
|
我们可以在第一次使用时直接添加一个 .clone() 函数,然后就完事了。
但让我们更复杂一点:我们真的需要在 Email Client::send_email 中获取订阅者电子邮件的所有权吗?
//! src/email_client.rs
// [...]
pub async fn send_email(
&self,
recipient: SubscriberEmail,
subject: &str,
html_content: &str,
text_content: &str,
) -> Result<(), reqwest::Error> {
// [...]
let request_body = SendEmailRequest {
from: self.sender.as_ref(),
to: recipient.as_ref(),
subject: subject,
html_body: html_content,
text_body: text_content,
};
// [...]
}
我们只需要能够调用 as_ref 即可—— &SubscriberEmail 就可以了。
让我们相应地更改签名:
//! src/email_client.rs
// [...]
pub async fn send_email(
&self,
recipient: &SubscriberEmail,
// [...]
) -> Result<(), reqwest::Error> {
// [...]
}
有几个调用点需要更新——编译器会很温柔地指出它们。我会把修复留给读者,作为练习。
完成后, 测试套件应该会通过。
移除一些模板代码
在继续之前,让我们最后看一下 get_confirmed_subscribers:
//! src/routes/newsletters.rs
// [...]
async fn get_confirmed_subscribers(
pool: &PgPool,
) -> Result<Vec<Result<ConfirmedSubscriber, anyhow::Error>>, anyhow::Error> {
struct Row {
email: String,
}
let rows = sqlx::query_as!(
Row,
r#"
SELECT email
FROM subscriptions
WHERE status = 'confirmed'
"#,
)
.fetch_all(pool)
.await?;
// Map into the domain type
let confirmed_subscribers = rows
.into_iter()
.map(|r| match SubscriberEmail::parse(r.email) {
Ok(email) => Ok(ConfirmedSubscriber { email }),
Err(error) => Err(anyhow::anyhow!(error)),
})
.collect();
Ok(confirmed_subscribers)
}
Row 有什么用吗?
其实不然——查询本身就很简单,用一个专门的类型来表示返回的数据并没有什么好处。
我们可以切换回 query! 并完全移除 Row:
//! src/routes/newsletters.rs
// [...]
async fn get_confirmed_subscribers(
pool: &PgPool,
) -> Result<Vec<Result<ConfirmedSubscriber, anyhow::Error>>, anyhow::Error> {
let rows = sqlx::query!(
r#"
SELECT email
FROM subscriptions
WHERE status = 'confirmed'
"#,
)
.fetch_all(pool)
.await?;
// Map into the domain type
let confirmed_subscribers = rows
.into_iter()
.map(|r| match SubscriberEmail::parse(r.email) {
Ok(email) => Ok(ConfirmedSubscriber { email }),
Err(error) => Err(anyhow::anyhow!(error)),
})
.collect();
Ok(confirmed_subscribers)
}
我们甚至不需要触及剩余的代码 - 它可以直接编译。
简单方法的局限性
我们成功了——我们的实现已经通过了两项集成测试!
现在怎么办? 是要自我表扬然后将其投入生产环境吗?
别急。
我们一开始就说过——我们采用的方法是尽可能简单地启动并运行。
但是,这样就足够好了吗?
让我们仔细看看它的缺点!
- 安全性: 我们的 POST /newsletters 端点不受保护——任何人都可以向其发起请求,并广播给我们的所有受众,而无需经过任何检查。
- 您只有一次机会: 一旦您点击 POST /newsletters,您的内容就会发送到您的整个邮件列表。在批准发布之前,您没有机会在草稿模式下编辑或审阅它。
- 性能: 我们一次发送一封电子邮件。 我们会等待当前邮件成功发送后再继续发送下一封。 如果您有 10 或 20 个订阅者,这不会造成太大问题,但很快就会变得明显:对于拥有大量受众的新闻通讯来说,延迟将会非常严重。
- 容错: 如果我们发送一封电子邮件失败,我们会使用 ? 将错误冒泡,并向调用者返回 500 内部服务器错误。 剩余的电子邮件永远不会发送,我们也不会重试发送失败的邮件。
- 重试安全性: 网络通信时,很多事情都可能出错。如果我们 API 的使用者在调用我们的服务时遇到超时或 500 内部服务器错误,该怎么办? 他们无法重试——这可能会让新闻稿再次发送给整个邮件列表。
第 2 点和第 3 点虽然烦人,但我们可以忍受一段时间。
第 4 点和第 5 点是相当严重的限制,对我们的用户有明显的影响。
第 1 点是没有商量余地的:我们必须在发布 API 之前保护好端点。
小结
我们构建了新闻通讯发送逻辑的原型: 它满足了我们的功能需求, 但尚未准备好投入使用。
我们 MVP 的不足之处将成为下一章的重点, 并按优先顺序进行讨论: 我们将首先解决身份验证/授权问题, 然后再讨论容错问题。
保护我们的 API
在第九章中,我们为 API 添加了一个新的端点 - POST /newsletters。
它接收新闻简报的期刊作为输入,并向所有订阅者发送电子邮件。
但我们遇到了一个问题——任何人都可以访问该 API,并向我们的整个邮件列表广播任何他们想要的内容。
现在是时候升级我们的 API 安全工具箱了。
我们将介绍身份验证和授权的概念,评估各种方法(基本身份验证、基于会话的身份验证、OAuth 2.0、OpenId Connect),并讨论最常用的令牌格式之一——JSON Web 令牌 (JWT) 的优势(和缺陷)。
本章与本书其他章节一样,出于教学目的,选择先“做错”。 如果您不想养成不良的安全习惯,请务必读到最后!
鉴权
我们需要一种方法来验证谁在调用 POST / 新闻通讯。
只有少数负责内容的人才能向整个邮件列表发送电子邮件。
我们需要找到一种方法来验证 API 调用者的身份——我们必须对他们进行身份验证。
怎么做?
通过请求他们提供一些他们独有的资源。
方法多种多样,但都可以归结为三类:
- 他们知道的信息(例如密码、PIN 码、安全问题);
- 他们拥有的信息(例如智能手机、使用身份验证器应用程序);
- 他们的身份(例如指纹、Apple 的 Face ID)。 每种方法都有其自身的弱点。
缺点
他们知道的事情
密码必须足够长——短密码容易受到暴力破解攻击。
密码必须是唯一的——公开的信息(例如出生日期、家庭成员姓名等)不应给攻击者任何“猜测”密码的机会。
密码不应在多个服务中重复使用——如果任何一个服务被泄露,您将面临授予所有其他共享相同密码的服务访问权限的风险。
平均而言,一个人拥有 100 个或更多的在线账户——他们不可能被要求记住数百个冗长而独特的密码。
密码管理器虽然有所帮助,但它们尚未成为主流,而且用户体验通常不太理想。
他们拥有的东西
智能手机和 U2F 密钥可能会丢失,导致用户无法访问其账户。它们也可能被盗或被盗,给攻击者提供了冒充受害者的机会。
他们是什么
与密码不同,生物识别技术无法更改——你无法“旋转”你的指纹,也无法改变视网膜血管的图案。
伪造指纹比大多数人想象的要容易——而且这些信息通常会被政府机构获取,并可能被滥用或丢失。
多因素身份验证
那么,鉴于每种方法都有其自身的缺陷,我们该怎么做呢? 好吧,我们可以将它们结合起来!
这几乎就是多因素身份验证 (MFA) 的精髓——它要求用户 提供至少两种不同类型的身份验证因素才能获得访问权限。
基于密码的鉴权
让我们从理论到实践:如何实现身份验证?
在我们提到的三种方法中,密码验证看起来是最简单的。
我们应该如何将用户名和密码传递给 API?
基本鉴权
我们可以使用“基本”身份验证方案,这是互联网工程任务组 (IETF) 在 RFC 2617 中定义的标准,后来由 RFC 7617 更新。
API 必须在传入请求中查找授权标头,其结构如下:
Authorization: Basic <encoded credentials>
其中 <encoded credentials> 是 {username}:{password} 的 base64 编码。
根据规范,我们需要将 API 划分为多个保护空间或域 -
同一域内的资源使用相同的身份验证方案和凭证集进行保护。
我们只需要保护一个端点 - POST /newsletters。因此,我们将使用一个名为 publish 的域。
API 必须拒绝所有缺少标头或使用无效凭证的请求 - 响应必须使用 401 Unauthorized 状态码,并包含一个包含质询的特殊标头 WWW-Authenticate。
挑战是一个字符串,用于向 API 调用者解释我们期望在相关领域看到哪种类型的身份验证方案。
在我们的例子中,使用基本身份验证,它应该是:
HTTP/1.1 401 Unauthorized
WWW-Authenticate: Basic realm="publish"
让我们来实现它!
提取凭证
从传入请求中提取用户名和密码 将是我们的第一个里程碑。
让我们先从一个不太愉快的情况开始——没有 Authorization 标头的传入请求被拒绝。
//! tests/api/newsletter.rs
// [...]
#[tokio::test]
async fn requests_missing_authorization_are_rejected() {
// Arrange
let app = spawn_app().await;
let response = reqwest::Client::new()
.post(&format!("{}/newsletters", &app.address))
.json(&serde_json::json!({
"title": "Newsletter title",
"content": {
"text": "Newsletter body as plain text",
"html": "<p>Newsletter body as HTML</p>",
}
}))
.send()
.await
.expect("Failed to execute request.");
// Assert
assert_eq!(401, response.status().as_u16());
assert_eq!(r#"Basic realm="publish""#, response.headers()["WWW-Authenticate"]);
}
它在第一个断言时就失败了:
thread 'newsletter::requests_missing_authorization_are_rejected' panicked at tes
ts/api/newsletter.rs:158:5:
assertion `left == right` failed
left: 401
right: 200
我们必须更新处理程序以满足新的要求。
我们可以使用 HttpRequest 提取器来获取与传入请求关联的标头:
//! src/routes/newsletters.rs
// [...]
pub async fn publish_newsletter(
body: web::Json<BodyData>,
pool: web::Data<PgPool>,
email_client: web::Data<EmailClient>,
request: HttpRequest,
) -> Result<HttpResponse, PublishError> {
let _credentials = basic_authentication(request.headers());
// [...]
}
struct Credentials {
username: String,
password: SecretString,
}
fn basic_authentication(headers: &HeaderMap) -> Result<Credentials, anyhow::Error> {
todo!()
}
要提取凭证,我们需要处理 base64 编码。
让我们将 base64 crate 添加为依赖项:
cargo add base64
现在我们可以写下 basic_authentication 的主体:
//! src/routes/newsletters.rs
// [...]
fn basic_authentication(headers: &HeaderMap) -> Result<Credentials, anyhow::Error> {
// The header value, if present, must be a valid UTF8 string
let header_value = headers
.get("Authorization")
.context("The 'Authorization' header was missing")?
.to_str()
.context("The 'Authorization' header was not a valid UTF8 string.")?;
let base64_encoded_segment = header_value
.strip_prefix("Basic ")
.context("The authorization scheme was not 'Basic'.")?;
let decoded_bytes = base64::engine::general_purpose::STANDARD
.decode(base64_encoded_segment)
.context("Failed to base64-decode 'Basic' credentials.")?;
let decoded_credentials = String::from_utf8(decoded_bytes)
.context("The decoded credential string is not valid UTF8.")?;
// APlit into two segments, using ':' as delimitator
let mut credentials = decoded_credentials.splitn(2, ':');
let username = credentials
.next()
.ok_or_else(|| anyhow::anyhow!("A useranme must be provided in 'Basic' auth."))?
.to_string();
let password = credentials
.next()
.ok_or_else(|| anyhow::anyhow!("A password must be provided in 'Basic' auth."))?
.to_string();
Ok(Credentials {
username,
password: SecretString::from(password),
})
}
花点时间逐行检查代码,彻底理解发生了什么。很多操作都可能出错!
把 RFC 和书放在一起打开,会很有帮助!
我们还没完——我们的测试仍然失败。
我们需要根据 basic_authentication 返回的错误采取行动:
//! src/routes/newsletters.rs
// [...]
#[derive(thiserror::Error)]
pub enum PublishError {
// New error variant!
#[error("Authentication failed.")]
AuthError(#[source] anyhow::Error),
#[error(transparent)]
UnexpectedError(#[from] anyhow::Error),
}
impl ResponseError for PublishError {
fn status_code(&self) -> actix_web::http::StatusCode {
match self {
PublishError::AuthError(_) => StatusCode::UNAUTHORIZED,
// Return a 401 for auth errors
PublishError::UnexpectedError(_) => StatusCode::INTERNAL_SERVER_ERROR,
}
}
}
pub async fn publish_newsletter(
// [...]
) -> Result<HttpResponse, PublishError> {
let _credentials = basic_authentication(request.headers())
// Bubble up the error, performing the necessary conversion
.map_err(PublishError::AuthError)?;
// [...]
}
我们的状态代码断言现在很满意,但标头断言还不满意:
thread 'newsletter::requests_missing_authorization_are_rejected' panicked at tes
ts/api/newsletter.rs:159:62:
no entry found for key "WWW-Authenticate"
到目前为止,指定每个错误返回的状态码已经足够了——现在我们需要更多的东西,一个报头。
我们需要将重点从 ResponseError::status_code 转移到 ResponseError::error_response:
//! src/routes/newsletters.rs
// [...]
impl ResponseError for PublishError {
fn error_response(&self) -> HttpResponse<actix_web::body::BoxBody> {
match self {
PublishError::UnexpectedError(_) => {
HttpResponse::new(StatusCode::INTERNAL_SERVER_ERROR)
}
PublishError::AuthError(_) => {
let mut response = HttpResponse::new(StatusCode::UNAUTHORIZED);
let header_value = HeaderValue::from_str(r#"Basic realm="publish""#)
.unwrap();
response
.headers_mut()
// actix_web::http::header provides a collection of constants
// for the names of several well-known/standard HTTP headers
.insert(header::WWW_AUTHENTICATE, header_value);
response
},
}
}
// `status_code` is invoked by the default `error_response`
// implementation. We are providing a bespoke `error_response` implementation
// therefore there is no need to maintain a `status_code` implementation anymore.
}
我们的身份验证测试通过了!
不过,一些旧测试还是有问题:
thread 'newsletter::newsletters_are_not_delivered_to_unconfirmed_subscribers' pa
nicked at tests/api/newsletter.rs:34:5:
assertion `left == right` failed
left: 401
right: 200
thread 'newsletter::newsletters_are_delivered_to_confirmed_subscribers' panicked at tests/api/newsl
etter.rs:102:5:
assertion `left == right` failed
left: 401
right: 200
POST /newsletters 现在会拒绝所有未经身份验证的请求,包括我们在快乐路径黑盒测试中发出的请求。
我们可以通过提供随机的用户名和密码组合来阻止这种情况:
//! tests/api/helpers.rs
// [...]
impl TestApp {
pub async fn post_newsletters(&self, body: serde_json::Value) -> reqwest::Response {
reqwest::Client::new()
.post(&format!("{}/newsletters", &self.address))
// Random credentials!
// `reqwest` does all the encoding/formatting heavy-lefting for us.
.basic_auth(Uuid::new_v4().to_string(), Some(Uuid::new_v4().to_string()))
.json(&body)
.send()
.await
.expect("Failed to execute request.")
}
// [...]
}
测试套件应该再次通过。
密码验证 - 简单方法
接受随机凭证的身份验证层...并不理想。
我们需要开始验证从授权标头中提取的凭证——它们 应该与已知用户列表进行比较。
我们将创建一个新的用户 Postgres 表来存储此列表:
sqlx migrate add create_users_table
该模式的初稿可能如下所示:
-- migrations/<date>_create_users_table.sql
CREATE TABLE users(
user_id uuid PRIMARY KEY,
username TEXT NOT NULL UNIQUE,
password TEXT NOT NULL
);
然后我们可以更新我们的处理程序以便在每次执行身份验证时查询它:
//! src/routes/newsletters.rs
use secrecy::ExposeSecret;
// [...]
async fn validate_credentials(
credentials: Credentials,
pool: &PgPool,
) -> Result<uuid::Uuid, PublishError> {
let user_id: Option<_> = sqlx::query!(
r#"
SELECT user_id
FROM users
WHERE username = $1 AND password = $2
"#,
credentials.username,
credentials.password.expose_secret()
)
.fetch_optional(pool)
.await
.context("Failed to perform a query to validate auth credentials.")
.map_err(PublishError::UnexpectedError)?;
user_id
.map(|row| row.user_id)
.ok_or_else(|| anyhow::anyhow!("Invalid username or password."))
.map_err(PublishError::AuthError)
}
pub async fn publish_newsletter(
body: web::Json<BodyData>,
pool: web::Data<PgPool>,
email_client: web::Data<EmailClient>,
request: HttpRequest,
) -> Result<HttpResponse, PublishError> {
let credentials = basic_authentication(request.headers())
// Bubble up the error, performing the necessary conversion
.map_err(PublishError::AuthError)?;
let user_id = validate_credentials(credentials, &pool).await?;
// [...]
}
记录谁调用了 POST /newsletters 是个好主意——让我们在处理程序周围添加一个 tracing span:
//! src/routes/newsletters.rs
// [...]
#[tracing::instrument(
name = "Publish a newsletter issue",
skip(body, pool, email_client, request),
fields(username=tracing::field::Empty, user_id=tracing::field::Empty)
)]
pub async fn publish_newsletter(
body: web::Json<BodyData>,
pool: web::Data<PgPool>,
email_client: web::Data<EmailClient>,
request: HttpRequest,
) -> Result<HttpResponse, PublishError> {
let credentials = basic_authentication(request.headers())
// Bubble up the error, performing the necessary conversion
.map_err(PublishError::AuthError)?;
tracing::Span::current().record(
"username",
&tracing::field::display(&credentials.username)
);
let user_id = validate_credentials(credentials, &pool)
.await?;
tracing::Span::current().record("user_id", &tracing::field::display(user_id));
// [...]
}
现在,我们需要更新我们的快乐路径测试,以指定一个能被 validate_credentials 接受的用户名-密码对。
我们将为测试应用的每个实例生成一个测试用户。我们尚未实现新闻通讯编辑者的注册流程,因此我们无法采用完全黑盒的方法——目前,我们将把测试用户的详细信息直接注入数据库:
//! tests/api/helpers.rs
// [...]
pub async fn spawn_app() -> TestApp {
// [...]
let test_app = TestApp {
// [...]
};
add_test_user(&test_app.db_pool).await;
test_app
}
async fn add_test_user(pool: &PgPool) {
sqlx::query!(
"INSERT INTO users (user_id, username, password)
VALUES ($1, $2, $3)",
Uuid::new_v4(),
Uuid::new_v4().to_string(),
Uuid::new_v4().to_string(),
)
.execute(pool)
.await
.expect("Failed to create test users.");
}
TestApp 将提供一个辅助方法来检索其用户名和密码
//! tests/api/helpers.rs
// [...]
impl TestApp {
// [...]
pub async fn test_user(&self) -> (String, String) {
let row = sqlx::query!("SELECT username, password FROM users LIMIT 1",)
.fetch_one(&self.db_pool)
.await
.expect("Failed to create test users.");
(row.username, row.password)
}
}
然后我们将从您的 post_newsletters 方法中调用它,而不是使用随机凭据:
//! tests/api/helpers.rs
// [...]
impl TestApp {
// [...]
pub async fn post_newsletters(&self, body: serde_json::Value) -> reqwest::Response {
let (username, password) = self.test_user().await;
reqwest::Client::new()
.post(&format!("{}/newsletters", &self.address))
.basic_auth(username, Some(password))
.json(&body)
.send()
.await
.expect("Failed to execute request.")
}
}
现在所有测试应该都可以通过了
存储密码
将原始用户密码存储在数据库中并非明智之举。
攻击者可以访问您存储的数据,立即开始冒充您的用户——用户名和密码都已准备就绪。
他们甚至无需入侵您的实时数据库——只需一个未加密的备份即可。
不需要存储原始密码
我们为什么要存储密码呢?
我们需要执行相等性检查——每次用户尝试身份验证时,我们都会验证他们提供的密码是否与我们预期的密码匹配。 如果我们只关心相等性,就可以开始设计更复杂的策略。
例如,我们可以在比较密码之前应用一个函数来转换它们。
所有确定性函数在给定相同输入的情况下都会返回相同的输出。
设 f 是我们的确定性函数: psw_candidate == expected_psw 意味着 f(psw_candidate) == f(expected_psw)。
但这还不够——如果 f 对每个可能的输入字符串都返回 hello 呢?无论输入是什么,密码验证都会成功。 我们需要反过来:
如果 f(psw_candidate) == f(expected_psw) 则
psw_candidate == expected_psw。
假设我们的函数 f 具有一个附加属性,那么这是可能的:它必须是单射函数——如果 x != y, 则 f(x) != f(y)。
如果我们有这样一个函数 f,我们就可以完全避免存储原始密码:当用户注册时,我们计算 f(password) 并将其存储在数据库中。密码会被丢弃。
当同一个用户尝试登录时,我们计算 f(psw_candidate) 并检查它是否与我们在注册时存储的 f(password) 值匹配。原始密码永远不会被持久化。
这真的能改善我们的安全状况吗?
这取决于 f!
定义一个单射函数并不难——逆函数 f("hello") = "olleh"
就满足我们的标准。同样容易猜测如何反转转换以恢复原始密码——这不会妨碍攻击者。
我们可以让变换更加复杂——复杂到足以让攻击者难以找到逆变换。
即使这样也可能不够。通常情况下,攻击者能够从输出中恢复输入的某些属性(例如长度),从而发起例如有针对性的暴力破解攻击就足够了。
我们需要更强大的算法——两个输入 x 和 y 的相似度与相应的输出 f(x) 和 f(y) 的相似度之间不应该存在任何关系。
我们需要一个加密哈希函数。
哈希函数将输入空间中的字符串映射到固定长度的输出。
形容词“加密”指的是我们刚才讨论的一致性属性,也称为雪崩效应: 输入的微小差异会导致输出差异如此之大,以至于看起来不相关。
需要注意的是: 哈希函数不是单射的,存在微小的碰撞风险——如果 f(x) == f(y), 则有很大概率(不是 100%!)x == y。
使用加密哈希
理论讲得够多了——让我们更新一下实现,在存储密码之前先进行哈希处理。
市面上有几种加密哈希函数——MD5、SHA-1、SHA-2、SHA-3、KangarooTwelve 等等。
我们不会深入探讨每种算法的优缺点——对于密码来说,这毫无意义,原因稍后会解释清楚。
为了本节的方便,我们先来讨论一下安全哈希算法家族的最新成员 SHA-3。
除了该算法之外,我们还需要选择输出大小——例如,SHA3-224 使用 SHA-3 算法生成 224 位的固定大小输出。 输出大小选项包括 224、256、384 和 512。输出越长,发生碰撞的可能性就越小。另一方面,使用更长的哈希值会需要更多存储空间并消耗更多带宽。
SHA3-256 应该足以满足我们的用例。
Rust Crypto 组织提供了 SHA-3 的实现,即 sha3 crate。让我们将它添加到我们的依赖项中:
cargo add sha3
为了清楚起见,我们将 password column 重命名为 password_hash:
sqlx migrate add rename_password_column
-- migrations/<timestamp>_rename_password_column.sql
ALTER TABLE users RENAME password TO password_hash;
我们的项目应该停止编译:
error: error returned from database: column "password" does not exist
--> src/routes/newsletters.rs:182:30
|
182 | let user_id: Option<_> = sqlx::query!(
| ______________________________^
183 | | r#"
184 | | SELECT user_id
185 | | FROM users
... |
189 | | credentials.password.expose_secret()
190 | | )
| |_____^
|
= note: this error originates in the macro `$crate::sqlx_macros::expand_query` which comes from the expansion of the macro `sqlx::query` (in Nightly builds, run with -Z macro-backtrace for more in
fo)
sqlx::query! 发现我们的一个查询使用了当前模式中不再存在的列。
SQL 查询的编译时验证非常简洁,不是吗?
我们的 validate_credentials 函数如下所示:
//! src/routes/newsletters.rs
// [...]
async fn validate_credentials(
credentials: Credentials,
pool: &PgPool,
) -> Result<uuid::Uuid, PublishError> {
let user_id: Option<_> = sqlx::query!(
r#"
SELECT user_id
FROM users
WHERE username = $1 AND password = $2
"#,
credentials.username,
credentials.password.expose_secret()
)
// [...]
}
让我们更新它以使用散列密码:
//! src/routes/newsletters.rs
// [...]
use sha3::Digest;
async fn validate_credentials(
credentials: Credentials,
pool: &PgPool,
) -> Result<uuid::Uuid, PublishError> {
let password_hash = sha3::Sha3_256::digest(credentials.password.expose_secret().as_bytes());
let user_id: Option<_> = sqlx::query!(
r#"
SELECT user_id
FROM users
WHERE username = $1 AND password_hash = $2
"#,
credentials.username,
password_hash
)
// [...]
}
不幸的是,它不会立即编译:
error[E0308]: mismatched types
--> src/routes/newsletters.rs:191:9
|
191 | password_hash
| ^^^^^^^^^^^^^
| |
| expected `&str`, found `GenericArray<u8, UInt<..., ...>>`
| expected due to the type of this binding
|
= note: expected reference `&str`
found struct `GenericArray<u8, UInt<UInt<UInt<UInt<UInt<UInt<UTerm, B1>, B0>, B0>, B0>, B0>, B0>>`
Digest::digest 返回一个固定长度的字节数组, 而我们的 password_hash 列是 TEXT 类型,即字符串。
我们可以更改用户表的模式,将 password_hash 存储为二进制。或者,我们可以使用十六进制格式将 Digest::digest 返回的字节编码为字符串。
为了避免再次迁移,我们可以使用第二种方案:
//! src/routes/newsletters.rs
// [...]
async fn validate_credentials(
credentials: Credentials,
pool: &PgPool,
) -> Result<uuid::Uuid, PublishError> {
let password_hash = sha3::Sha3_256::digest(credentials.password.expose_secret().as_bytes());
// Lowercase hexadecimal encoding.
let password_hash = format!("{password_hash:x}");
// [...]
}
应用程序代码现在应该可以编译了。测试套件则需要更多工作。
test_user 辅助方法之前是通过查询用户表来恢复一组有效凭证的, ——现在我们存储的是哈希值而不是原始密码,所以这种方法不再可行!
//! tests/api/helpers.rs
// [...]
impl TestApp {
pub async fn test_user(&self) -> (String, String) {
let row = sqlx::query!("SELECT username, password FROM users LIMIT 1",)
.fetch_one(&self.db_pool)
.await
.expect("Failed to create test users.");
(row.username, row.password)
}
}
async fn add_test_user(pool: &PgPool) {
sqlx::query!(
"INSERT INTO users (user_id, username, password)
VALUES ($1, $2, $3)",
Uuid::new_v4(),
Uuid::new_v4().to_string(),
Uuid::new_v4().to_string(),
)
.execute(pool)
.await
.expect("Failed to create test users.");
}
// [...]
我们需要 Test`App 来存储随机生成的密码,以便我们在辅助方法中访问它。
我们先创建一个新的辅助结构体 TestUser:
//! tests/api/helpers.rs
// [...]
pub struct TestUser {
pub user_id: Uuid,
pub username: String,
pub password: String,
}
impl TestUser {
pub fn generate() -> Self {
Self {
user_id: Uuid::new_v4(),
username: Uuid::new_v4().to_string(),
password: Uuid::new_v4().to_string(),
}
}
async fn store(&self, pool: &PgPool) {
let password_hash = sha3::Sha3_256::digest(self.password.as_bytes());
let password_hash = format!("{password_hash:x}");
sqlx::query!(
"INSERT INTO users (user_id, username, password_hash)
VALUES ($1, $2, $3)",
self.user_id,
self.username,
password_hash,
)
.execute(pool)
.await
.expect("Failed to store test user.");
}
}
我们可以在 TestApp 中存储一个 TestUser 的实例, 作为新的字段:
//! tests/api/helpers.rs
// [...]
pub struct TestApp {
// [...]
test_user: TestUser,
}
pub async fn spawn_app() -> TestApp {
// [...]
let test_app = TestApp {
// [...]
test_user: TestUser::generate(),
};
test_app.test_user.store(&test_app.db_pool).await;
test_app
}
最后, 我们移除 add_test_user, TestApp::test_user 和更新 TestApp::post_newsletters:
//! tests/api/helpers.rs
// [...]
impl TestApp {
// [...]
pub async fn post_newsletters(&self, body: serde_json::Value) -> reqwest::Response {
reqwest::Client::new()
.post(format!("{}/newsletters", &self.address))
.basic_auth(&self.test_user.username, Some(&self.test_user.password))
.json(&body)
.send()
.await
.expect("Failed to execute request.")
}
}
现在测试套件应该可以通过了.
原像攻击
如果攻击者获取了我们的用户表,SHA3-256 是否足以保护用户的密码?
假设攻击者想要破解我们数据库中特定的密码哈希值。
攻击者甚至不需要检索原始密码。为了成功验证身份,他们
只需要找到一个输入字符串 s,其 SHA3-256 哈希值与他们试图破解的密码匹配——换句话说,就是碰撞。
这被称为原像攻击。
它有多难?
数学计算起来有点棘手,但暴力攻击的时间复杂度是指数级的——2^n,其中n 是哈希长度(以位为单位)。
如果 n > 128,则认为无法计算。
除非 SHA-3 中存在漏洞,否则我们无需担心针对 SHA3-256 的原像攻击。
朴素字典攻击
不过,我们并不是对任意输入进行哈希处理——我们可以通过对原始密码进行一些假设来减少搜索空间:它有多长?使用了哪些符号?
假设我们正在寻找一个长度少于 17 个字符的字母数字密码。
我们可以计算候选密码的数量:
// (26 letters + 10 number symbols) ^ Password Length
// for all allowed password lengths
36^1 +
36^2 +
... +
36^16
总计大约有 8 * 10^24 种可能性。
我找不到关于 SHA3-256 的具体数据,但研究人员使用图形处理单元 (GPU) 每秒计算出约 9 亿个 SHA3-512 哈希值。
假设哈希率约为每秒 10^9, 则我们需要约 10^15 秒来哈希所有候选密码。宇宙的年龄约为 4 * 10^17 秒。
字典攻击
让我们回顾一下本章开头讨论的内容——一个人不可能记住数百个在线服务的唯一密码。
他们要么依赖密码管理器,要么在多个账户中重复使用一个或多个密码。
此外,大多数密码即使重复使用也远非随机——常用词、全名、日期、热门运动队名称等等。
攻击者可以轻松设计一个简单的算法来生成数千个看似合理的密码——但他们不必这样做。他们可以查看过去十年中众多安全漏洞中的一个密码数据集,找出最常见的密码。
只需几分钟,他们就可以预先计算出最常用的一千万个密码的 SHA3-256 哈希值。然后,他们开始扫描我们的数据库,寻找匹配的密码。
这被称为字典攻击——而且非常有效。
我们到目前为止提到的所有加密哈希函数都旨在提高速度。
速度足够快,任何人都可以发起字典攻击,而无需使用专门的硬件。
我们需要一种速度慢得多,但又具有与加密哈希函数相同的数学特性的算法。
Argon2
开放式 Web 应用程序安全项目 (OWASP)75 提供了有关安全密码存储的有用指导 - 其中有一整节介绍如何选择正确的散列算法:
- 使用 Argon2id,最低配置为 15 MiB 内存、迭代次数为 2 且并行度为 1。
- 如果 Argon2id 不可用,请使用 bcrypt,工作因子为 10 或更高,密码长度限制为 72 字节。
- 对于使用 scrypt 的旧系统,请使用最低 CPU/内存成本参数 (2^16)、最小块大小为 8(1024 字节)和并行化参数为 1。
- 如果需要符合 FIPS-140 标准,请使用 PBKDF2,工作因子为 310,000 或更高,并使用 HMAC-SHA-256 内部哈希函数。
- 考虑使用胡椒粉来提供额外的纵深防御(尽管单独使用时,它不会提供额外的安全特性)。
所有这些选项——Argon2、bcrypt、scrypt、PBKDF2——都被设计为计算要求高。
它们还公开了一些配置参数(例如,bcrypt 的工作因子),以进一步降低哈希计算速度:应用程序开发者可以调整一些参数以跟上硬件加速的步伐——无需每隔几年就迁移到更新的算法。
让我们按照 OWASP 的建议,用 Argon2id 替换 SHA-3。
Rust Crypto 组织再次为我们提供了帮助——他们提供了一个纯 Rust 实现, argon2。
让我们将它添加到我们的依赖项中:
cargo add argon2 --features=std
要对密码进行哈希处理,我们需要创建一个 Argon2 结构体实例。
new 方法的签名如下:
//! argon2/lib.rs
// [...]
impl<'key> Argon2<'key> {
/// Create a new Argon2 context.
pub fn new(algorithm: Algorithm, version: Version, params: Params) -> Self {
// [...]
}
// [...]
}
Algorithm 是一个枚举: 它允许我们选择要使用的 Argon2 变体 - Argon2d、Argon2i、
Argon2id。为了符合 OWASP 的建议,我们将使用 Algorithm::Argon2id。
Version 的作用也类似 - 我们将使用最新版本, Version::V0x13。
那么 Params 呢?
Params::new 指定了构建一个 Argon2 所需的所有必需参数:
//! argon2/params.rs
// [...]
/// Create new parameters.
pub fn new(
m_cost: u32,
t_cost: u32,
p_cost: u32,
output_len: Option<usize>
) -> Result<Self> {
// [...]
}
m_cost、t_cost 和 p_cost 对应于 OWASP 的要求:
- m_cost 是内存大小,以千字节为单位
- t_cost 是迭代次数
- p_cost 是并行度
output_len 决定了返回哈希值的长度——如果省略,则默认为 32字节。这相当于 256 位,与我们通过 SHA3-256 获得的哈希值长度相同。
目前,我们已经掌握了足够的信息来构建一个:
//! src/routes/newsletters.rs
// [...]
async fn validate_credentials(
credentials: Credentials,
pool: &PgPool,
) -> Result<uuid::Uuid, PublishError> {
let hasher = Argon2::new(
argon2::Algorithm::Argon2id,
argon2::Version::V0x13,
Params::new(15000, 2, 1, None)
.context("Failed to build Argon2 parameters")
.map_err(PublishError::UnexpectedError)?,
);
let password_hash = sha3::Sha3_256::digest(credentials.password.expose_secret().as_bytes());
// [...]
}
Argon2 实现了 PasswordHasher trait:
//! password_hash/traits.rs
pub trait PasswordHasher {
// [...]
fn hash_password<'a, S>(
&self,
password: &[u8],
salt: &'a S
) -> Result<PasswordHash<'a>>
where
S: AsRef<str> + ?Sized;
}
它是 password-hash crate 的重新导出,后者是一个统一的接口,用于处理由多种算法(目前支持 Argon2、PBKDF2 和 scrypt)支持的密码哈希。
PasswordHasher::hash_password 与 Sha3_256::digest 略有不同——它要求在原始密码的基础上添加一个额外的参数, 即盐值。
加盐
Argon2 比 SHA-3 慢得多,但这不足以使字典攻击无法进行。虽然对最常见的 1000 万个密码进行哈希处理需要更长的时间,但也不会太长。
但是,如果攻击者必须为数据库中的每个用户重新哈希整个字典呢?
那就更具挑战性了!
这就是加盐算法的作用。对于每个用户,我们都会生成一个唯一的随机字符串——盐。
在生成哈希值之前,盐会被添加到用户密码的前面。PasswordHasher::hash_password 会为我们处理加盐的工作。
盐存储在数据库中,与密码哈希值相邻。
如果攻击者获取了数据库备份,他们就可以访问所有盐值。
但他们必须计算 dictionary_size * n_users 的哈希值,而不是 dictionary_size。此外,预先计算哈希值不再是一个选项——这为我们赢得了时间来检测违规行为并采取行动(例如,强制所有用户重置密码)。
让我们在 users 表中添加一个 password_salt 列:
sqlx migrate add add_salt_to_users
-- migrations/<timestamp>_add_salt_to_users.sql
ALTER TABLE users ADD COLUMN salt TEXT NOT NULL;
我们不能再在查询用户表之前计算哈希值了——我们需要先检索盐值。
让我们来改组一下操作:
//! src/routes/newsletters.rs
// [...]
async fn validate_credentials(
credentials: Credentials,
pool: &PgPool,
) -> Result<uuid::Uuid, PublishError> {
let hasher = Argon2::new(
argon2::Algorithm::Argon2id,
argon2::Version::V0x13,
Params::new(15000, 2, 1, None)
.context("Failed to build Argon2 parameters")
.map_err(PublishError::UnexpectedError)?,
);
let row: Option<_> = sqlx::query!(
r#"
SELECT user_id, password_hash, salt
FROM users
WHERE username = $1
"#,
credentials.username,
)
.fetch_optional(pool)
.await
.context("Failed to perform a query to retrieve stored credentials.")
.map_err(PublishError::UnexpectedError)?;
let (expected_password_hash, user_id, salt) = match row {
Some(row) => (row.password_hash, row.user_id, row.salt),
None => {
return Err(PublishError::AuthError(anyhow::anyhow!(
"Unknown username.",
)));
}
};
let mut password_hash = hasher
.hash_password(credentials.password.expose_secret().as_bytes(), &salt)
.context("Failed to hash password")
.map_err(PublishError::UnexpectedError)?;
let password_hash = format!("{:x}", password_hash.hash.unwrap());
if password_hash != expected_password_hash {
Err(PublishError::AuthError(anyhow::anyhow!(
"Invalid password."
)))
} else {
Ok(user_id)
}
}
很不幸的, 这不能编译
error[E0277]: the trait bound `Salt<'_>: std::convert::From<&std::string::String>` is not satisfied
--> src/routes/newsletters.rs:214:73
|
214 | .hash_password(credentials.password.expose_secret().as_bytes(), &salt)
| ------------- required by a bound introduced by this call ^^^^^ the trait `std::convert::
From<&std::string::String>` is not implemented for `Salt<'_>`
|
Output 提供了其他方法来获取字符串表示,例如 Output::b64_encode。
只要我们愿意更改数据库中存储的哈希值的假定编码,它就可以工作。
如果有必要进行更改,我们可以尝试比 base64 编码更好的方法。
PHC 字符串格式
为了验证用户身份,我们需要可重复性: 每次都必须运行完全相同的哈希算法。
盐值和密码只是 Argon2id 输入的一部分。所有其他加载参数(t_cost、m_cost、p_cost)对于在给定相同盐值和密码的情况下获得相同哈希值都同样重要。
如果我们存储哈希值的 base64 编码表示,则我们做出了一个强有力的隐含假设: password_hash 列中存储的所有值都是使用相同的加载参数计算的。
正如我们前几节所讨论的,硬件功能会随着时间推移而发展: 应用程序开发人员需要通过使用更高的加载参数来增加哈希值的计算成本,从而跟上时代的步伐。
当您必须将存储的密码迁移到更新的哈希配置时会发生什么? 为了继续验证旧用户的身份,我们必须在每个哈希值旁边存储用于计算哈希值的精确加载参数集。
这允许在两种不同的加载配置之间无缝迁移: 当旧用户进行身份验证时,我们使用存储的加载参数验证密码有效性;然后,我们使用新的加载参数重新计算密码哈希值,并相应地更新存储的信息。
我们可以采用简单的方法——在用户表中添加三个新列: t_cost、m_cost 和 p_cost。
只要算法仍然是 Argon2id,这种方法就有效。
如果在 Argon2id 中发现漏洞,我们被迫迁移到其他版本,会发生什么情况?
我们可能需要添加一个算法列,以及一些新列来存储 Argon2id 替代品的加载参数。
这可以做到,但很繁琐。
幸运的是,有一个更好的解决方案:PHC 字符串格式。PHC 字符串格式为密码哈希值提供了标准表示:它包含哈希值本身、盐值、算法以及所有相关参数。
使用 PHC 字符串格式,Argon2id 密码哈希如下所示:
# ${algorithm}${algorithm version}${$-separated algorithm parameters}${hash}${salt}
$argon2id$v=19$m=65536,t=2,p=1$gZiV/M1gPc22ElAH/Jh1Hw$CWOrkoo7oJBQ/iyh7uJ0LO2aLEfrHwTWllSAxT0zRno
argon2 crate 公开了 PasswordHash, 这是 PHC 格式的 Rust 实现:
//! argon2/lib.rs
// [...]
pub struct PasswordHash<'a> {
pub algorithm: Ident<'a>,
pub version: Option<Decimal>,
pub params: ParamsString,
pub salt: Option<Salt<'a>>,
pub hash: Option<Output>,
}
将密码哈希值存储为 PHC 字符串格式,可以避免我们不得不使用显式参数初始化 Argon2 结构体。
我们可以依赖 Argon2 的 PasswordVerifier 特性实现:
pub trait PasswordVerifier {
fn verify_password(
&self,
password: &[u8],
hash: &PasswordHash<'_>
) -> Result<()>;
}
通过 PasswordHash 传递预期的哈希值, Argon2 可以自动推断出应该使用哪些加载参数和盐来验证密码候选是否匹配。
让我们更新我们的实现:
//! src/routes/newsletters.rs
use argon2::{Argon2, PasswordHash, PasswordVerifier};
// [...]
async fn validate_credentials(
credentials: Credentials,
pool: &PgPool,
) -> Result<uuid::Uuid, PublishError> {
let row: Option<_> = sqlx::query!(
r#"
SELECT user_id, password_hash
FROM users
WHERE username = $1
"#,
credentials.username,
)
.fetch_optional(pool)
.await
.context("Failed to perform a query to retrieve stored credentials.")
.map_err(PublishError::UnexpectedError)?;
let (expected_password_hash, user_id) = match row {
Some(row) => (row.password_hash, row.user_id),
None => {
return Err(PublishError::AuthError(anyhow::anyhow!(
"Unknown username.",
)));
}
};
let expected_password_hash = PasswordHash::new(&expected_password_hash)
.context("Failed to parse hash in PHC string format.")
.map_err(PublishError::UnexpectedError)?;
Argon2::default()
.verify_password(
credentials.password.expose_secret().as_bytes(),
&expected_password_hash,
)
.context("Invalid password")
.map_err(PublishError::AuthError)?;
Ok(user_id)
}
编译成功。
你可能还注意到,我们不再直接处理盐值了——PHC 字符串格式会隐式地帮我们处理。
我们可以完全去掉盐值列:
sqlx migrate add remove_salt_from_users
-- migrations/<timestamp>_remove_salt_from_users.sql
ALTER TABLE users DROP COLUMN salt;
我们的测试怎么样?
其中两个测试失败了:
---- newsletter::newsletters_are_not_delivered_to_unconfirmed_subscribers stdout ----
thread 'newsletter::newsletters_are_not_delivered_to_unconfirmed_subscribers' panicked at tests/api
/newsletter.rs:34:5:
assertion `left == right` failed
left: 500
right: 200
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
---- newsletter::newsletters_are_delivered_to_confirmed_subscribers stdout ----
thread 'newsletter::newsletters_are_delivered_to_confirmed_subscribers' panicked at tests/api/newsl
etter.rs:102:5:
assertion `left == right` failed
left: 500
right: 200
failures:
newsletter::newsletters_are_delivered_to_confirmed_subscribers
newsletter::newsletters_are_not_delivered_to_unconfirmed_subscribers
我们可以查看日志来找出问题所在:
TEST_LOG=true cargo test newsletters_are_not_delivered | bunyan
Caused by:
password hash string missing field
让我们看一下测试用户的密码生成代码:
//! tests/api/helpers.rs
// [...]
impl TestUser {
// [...]
async fn store(&self, pool: &PgPool) {
let password_hash = sha3::Sha3_256::digest(self.password.as_bytes());
let password_hash = format!("{password_hash:x}");
// [...]
}
}
我们还在使用 SHA-3!
让我们更新它:
//! tests/api/helpers.rs
use argon2::password_hash::SaltString;
use argon2::{Argon2, PasswordHasher};
// [...]
impl TestUser {
// [...]
async fn store(&self, pool: &PgPool) {
let salt = SaltString::generate(&mut argon2::password_hash::rand_core::OsRng);
// We don't care about the exact Argon2 parameters here
// given that it's for testing purposes!
let password_hash = Argon2::default()
.hash_password(self.password.as_bytes(), &salt)
.unwrap()
.to_string();
// [...]
}
}
测试套件现在应该可以通过了。
我们已经从项目中删除了所有关于 sha3 的引用——现在可以将其从 Cargo.toml 的依赖项列表中删除了。
不要阻塞异步执行器
运行集成测试时,验证用户凭据需要多长时间?
我们目前没有关于密码哈希的跨度 - 让我们修复它:
//! src/routes/newsletters.rs
// [...]
async fn validate_credentials(
credentials: Credentials,
pool: &PgPool,
) -> Result<uuid::Uuid, PublishError> {
let (user_id, expected_password_hash) = get_stored_credentials(&credentials.username, pool)
.await
.map_err(PublishError::UnexpectedError)?
.ok_or_else(|| PublishError::AuthError(anyhow::anyhow!("Unknown username.")))?;
let expected_password_hash = PasswordHash::new(expected_password_hash.expose_secret())
.context("Failed to parse hash in PHC string format.")
.map_err(PublishError::UnexpectedError)?;
tracing::info_span!("Verify password hash")
.in_scope(|| {
Argon2::default().verify_password(
credentials.password.expose_secret().as_bytes(),
&expected_password_hash,
)
})
.context("Invalid password")
.map_err(PublishError::AuthError)?;
Ok(user_id)
}
// We extracted the db-querying logic in its own function with its own span.
#[tracing::instrument(name = "Get stored credentials", skip(username, pool))]
async fn get_stored_credentials(
username: &str,
pool: &PgPool,
) -> Result<Option<(uuid::Uuid, SecretString)>, anyhow::Error> {
let row: Option<_> = sqlx::query!(
r#"
SELECT user_id, password_hash
FROM users
WHERE username = $1
"#,
username,
)
.fetch_optional(pool)
.await
.context("Failed to perform a query to retrieve stored credentials.")?
.map(|row| (row.user_id, SecretString::from(row.password_hash)));
Ok(row)
}
现在我们可以查看其中一个集成测试的日志:
TEST_LOG=true cargo test --quiet --release newsletters_are_delivered | grep "VERIFY PASSWORD" | bunyan
[VERIFY PASSWORD HASH - END] (elaps
ed_milliseconds=16
大约 10 毫秒。
这很可能在负载下引发问题——臭名昭著的阻塞问题。
Rust 中的 async/await 是基于一个称为协作调度的概念构建的。
它是如何工作的?
我们来看一个例子:
async fn my_fn() {
a().await;
b().await;
c().await;
}
my_fn 返回一个 Future
当等待 Future 时,我们的异步运行时 (tokio) 就会介入: 它开始轮询 Future。
如何实现对 my_fn 返回的 Future 的轮询?
你可以将其视为一个状态机:
enum MyFnFuture {
Initialized,
CallingA,
CallingB,
CallingC,
Complete
}
每次调用 poll 时,它都会尝试进入下一个状态来取得进展。例如,如果 a.await() 返回,我们就开始等待 b()。
在 MyFnFuture 中,异步函数体中的每个 .await 都会有不同的状态。
这就是为什么 .await 调用通常被称为 yield point(让渡点)——我们的 Future 从上一个 .await 进展到下一个 .await, 然后将控制权交还给执行器。
执行器可以选择再次 poll 同一个 Future,或者优先处理其他任务。这就是像 tokio 这样的异步运行时如何通过不断地暂停和恢复每个任务来同时处理多个任务的方法。
在某种程度上,你可以将异步运行时视为出色的杂耍演员。
其基本假设是,大多数异步任务都在执行某种输入输出 (IO) 工作——它们的大部分执行时间都花在等待其他事件发生(例如,操作系统通知我们套接字上有可供读取的数据),因此,相比为每个任务分配一个并行执行单元(例如,每个操作系统核心一个线程),我们可以有效地并发执行更多任务。
如果任务之间能够协作,并频繁地将控制权交还给执行器,那么这种模型就能很好地发挥作用。
让我们实现它!
//! src/routes/newsletters.rs
// [...]
#[tracing::instrument(name = "Validate credentials", skip(credentials, pool))]
async fn validate_credentials(
credentials: Credentials,
pool: &PgPool,
) -> Result<uuid::Uuid, PublishError> {
let (user_id, expected_password_hash) = get_stored_credentials(&credentials.username, pool)
.await
.map_err(PublishError::UnexpectedError)?
.ok_or_else(|| PublishError::AuthError(anyhow::anyhow!("Unknown username.")))?;
let expected_password_hash = PasswordHash::new(expected_password_hash.expose_secret())
.context("Failed to parse hash in PHC string format.")
.map_err(PublishError::UnexpectedError)?;
tokio::task::spawn_blocking(move || {
tracing::info_span!("Verify password hash").in_scope(|| {
Argon2::default().verify_password(
credentials.password.expose_secret().as_bytes(),
&expected_password_hash,
)
})
})
.await
.context("Invalid password")
.map_err(PublishError::AuthError)?;
Ok(user_id)
}
borrow checker 并不是很满意
190 | let expected_password_hash = PasswordHash::new(expected_password_hash.expose_secret())
| ^^^^^^^^^^^^^^^^^^^^^^ borrowed value do
es not live long enough
...
194 | / tokio::task::spawn_blocking(move || {
195 | | tracing::info_span!("Verify password hash").in_scope(|| {
196 | | Argon2::default().verify_password(
197 | | credentials.password.expose_secret().as_bytes(),
... |
200 | | })
201 | | })
| |______- argument requires that `expected_password_hash` is borrowed for `'static`
我们正在一个单独的线程上启动一个计算——该线程本身的生命周期可能比我们创建它的异步任务更长。为了避免这个问题, spawn_blocking 要求其参数具有 'static 生命周期——这阻止我们将当前函数上下文的引用传递给闭包。
你可能会争辩说: "我们正在使用 move || {},闭包应该获取 expected_password_hash 的所有权!"。
你说得对!但这还不够。
我们再看看 PasswordHash 是如何定义的:
pub struct PasswordHash<'a> {
pub algorithm: Ident<'a>,
pub salt: Option<Salt<'a>>,
// [...]
}
它保存了对解析后的字符串的引用。
我们需要将原始字符串的所有权移到闭包中,并将解析逻辑也移到其中。
为了清晰起见,我们创建一个单独的函数 verify_password_hash:
//! src/routes/newsletters.rs
// [...]
#[tracing::instrument(name = "Validate credentials", skip(credentials, pool))]
async fn validate_credentials(
credentials: Credentials,
pool: &PgPool,
) -> Result<uuid::Uuid, PublishError> {
let (user_id, expected_password_hash) = get_stored_credentials(&credentials.username, pool)
.await
.map_err(PublishError::UnexpectedError)?
.ok_or_else(|| PublishError::AuthError(anyhow::anyhow!("Unknown username.")))?;
tokio::task::spawn_blocking(move || {
verify_password_hash(expected_password_hash, credentials.password)
})
.await
.context("Invalid password")
.map_err(PublishError::AuthError)??;
Ok(user_id)
}
#[tracing::instrument(
name = "Verify password hash",
skip(expected_password_hash, password_candidate)
)]
fn verify_password_hash(
expected_password_hash: SecretString,
password_candidate: SecretString,
) -> Result<(), PublishError> {
let expected_password_hash = PasswordHash::new(expected_password_hash.expose_secret())
.context("Failed to parse hash in PHC string format.")
.map_err(PublishError::UnexpectedError)?;
Argon2::default()
.verify_password(
password_candidate.expose_secret().as_bytes(),
&expected_password_hash,
)
.context("Invalid password.")
.map_err(PublishError::AuthError)
}
编译通过!
Tracing 上下文是线程本地的
让我们再次查看 verify password hash span的日志:
TEST_LOG=true cargo test --quiet --release newsletters_are_delivered | grep "VERIFY PASSWORD" | bunyan
[2025-09-16T14:13:30.467Z] INFO: test/124941 on qby-workspace: [VERIFY PASSWORD HASH - START] (file=...,line=...,target=...)
[2025-09-16T14:13:30.482Z] INFO: test/124941 on qby-workspace: [VERIFY PASSWORD HASH - END] (elapsed_milliseconds=14,file=...,line=...,target=...)
我们缺少从相应请求的根 span 继承的所有属性,例如 request_id、http.method、http.route 等。为什么?
让我们看看 tracing 的文档:
Span 构成树形结构——除非是根 Span,否则所有 Span 都有一个父级,并且可能有一个或多个子级。创建新 Span 时,当前 Span 将成为新 Span 的父级。
当前跨度是 tracing::Span::current() 返回的跨度 - 让我们查看其文档:
返回收集器认为是当前跨度的跨度句柄。如果收集器指示它不跟踪当前跨度,或者调用此函数的线程当前不在跨度内,则返回的跨度将被禁用。
“当前跨度”实际上是指“当前线程的活动跨度”。
这就是为什么我们没有继承任何属性:我们在一个单独的线程上生成计算,而 tracing::info_span! 在执行时找不到与其关联的任何活动跨度。
我们可以通过将当前跨度显式附加到新生成的线程来解决这个问题:
//! src/routes/newsletters.rs
// [...]
async fn validate_credentials(
credentials: Credentials,
pool: &PgPool,
) -> Result<uuid::Uuid, PublishError> {
// [...]
// This executes before spawning the new thread
let current_span = tracing::Span::current();
tokio::task::spawn_blocking(move || {
// We then pass ownership to it into the closure
// and explicitly executes all our computation
// within its scope.
current_span.in_scope(|| verify_password_hash(expected_password_hash, credentials.password))
})
// [...]
}
你可以验证它是否有效——我们现在获取了所有我们关心的属性。
不过这有点冗长——让我们编写一个辅助函数:
//! src/telemetry.rs
use tokio::task::JoinHandle;
// [...]
// Just copied trait bounds and signature from `spawn_blocking`
pub fn spawn_blocking_with_tracing<F, R>(f: F) -> JoinHandle<R>
where
F: FnOnce() -> R + Send + 'static,
R: Send + 'static,
{
let current_span = tracing::Span::current();
tokio::task::spawn_blocking(move || current_span.in_scope(f))
}
//! src/routes/newsletters.rs
use crate::telemetry::spawn_blocking_with_tracing;
// [...]
async fn validate_credentials(
credentials: Credentials,
pool: &PgPool,
) -> Result<uuid::Uuid, PublishError> {
// [...]
spawn_blocking_with_tracing(move || {
verify_password_hash(expected_password_hash, credentials.password)
})
// [...]
}
现在,每当我们需要将一些 CPU 密集型计算卸载到专用线程池时,都可以轻松地使用它。
用户枚举
让我们增加一个新测试用例:
//! tests/api/newsletter.rs
use uuid::Uuid;
// [...]
#[tokio::test]
async fn invalid_password_is_rejected() {
// Arrange
let app = spawn_app().await;
let username = &app.test_user.username;
// Random password
let password = Uuid::new_v4().to_string();
assert_ne!(app.test_user.password, password);
let response = reqwest::Client::new()
.post(format!("{}/newsletters", &app.address))
.basic_auth(username, Some(password))
.json(&serde_json::json!({
"title": "newsletter title",
"content": {
"text": "Newsletter body as plain text",
"html": "<p>Newsletter body as HTML</p>",
}
}))
.send()
.await
.expect("Failed to execute request.");
// Assert
assert_eq!(401, response.status().as_u16());
assert_eq!(
r#"Basic realm="publish""#,
response.headers()["WWW-Authenticate"]
)
}
这个应该也能通过。请求多久才会失败?
TEST_LOG=true cargo test --quiet --release invalid_password_is_rejected | grep "HTTP REQUEST" | bunyan
# [...] Omitting setup requests
[...] [HTTP REQUEST - END] (elapsed_millis
econds=19,..., http.route=/newsletters, ...)
大约 10 毫秒 - 小一个数量级!
我们可以利用这种差异来执行定时攻击,这是更广泛的旁道攻击之一。
如果攻击者知道至少一个有效用户名,他们就可以检查服务器响应时间81来确认是否存在其他用户名——我们正在研究一个潜在的用户枚举漏洞。
这会是个问题吗?
视情况而定。
如果您正在运行Gmail,还有很多其他方法可以查明@gmail.com电子邮件地址是否存在。
电子邮件地址的有效性并非秘密!
如果您正在运行SaaS产品,情况可能会更加复杂。
让我们假设一个场景:您的SaaS产品提供工资服务,并使用电子邮件地址作为用户名。产品有单独的员工和管理员登录页面。
我的目标是获取工资数据——我需要入侵具有特权访问权限的员工。
我们可以爬取LinkedIn数据,获取财务部门所有员工的姓名。
公司邮箱的结构是可预测的(姓名.姓氏@payrollaces.com),所以我们有一份候选人名单。
现在,我们可以对管理员登录页面进行定时攻击,将名单缩小到有权访问的用户。
即使在我们虚构的例子中,单靠用户枚举也不足以提升我们的权限。
但它可以作为跳板,缩小目标范围,以便进行更精准的攻击。
我们如何预防这种情况?
有两种策略:
- 消除因密码无效导致的身份验证失败和因用户名不存在导致的身份验证失败之间的时间差
- 限制给定 IP/用户名的身份验证失败次数。
第二种策略通常有助于防止暴力破解攻击,但它需要保存一些状态——我们稍后再讨论。
我们先来重点讨论第一种策略。
为了消除时间差异,我们需要在两种情况下执行相同的工作量。
目前,我们遵循以下方案:
- 获取给定用户名的存储凭证
- 如果不存在,则返回 401
- 如果存在,则对候选密码进行哈希处理,并与存储的哈希值进行比较。
我们需要消除这种提前退出的情况——我们应该有一个备用的预期密码(包含盐值和加载参数),
以便与候选密码的哈希值进行比较。
//! src/routes/newsletters.rs
// [...]
async fn validate_credentials(
credentials: Credentials,
pool: &PgPool,
) -> Result<uuid::Uuid, PublishError> {
let mut user_id = None;
let mut expected_password_hash = SecretString::from(
"$argon2id$v=19$m=15000,t=2,p=1$\
gZiV/M1gPc22ElAH/Jh1Hw$\
CWOrkoo7oJBQ/iyh7uJ0LO2aLEfrHwTWllSAxT0zRno"
.to_string(),
);
if let Some((stored_user_id, stored_password_hash)) =
get_stored_credentials(&credentials.username, pool)
.await
.map_err(PublishError::UnexpectedError)?
{
user_id = Some(stored_user_id);
expected_password_hash = stored_password_hash
}
spawn_blocking_with_tracing(move || {
verify_password_hash(expected_password_hash, credentials.password)
})
.await
.context("Invalid password")
.map_err(PublishError::AuthError)??;
// This is only set to `Some` if we found credentials in the store
// So, even if the default password ends up matching (somehow)
// with the provided password,
// we never authenticate a non-existing user.
user_id.ok_or_else(|| PublishError::AuthError(anyhow::anyhow!("Unknown username.")))
}
//! tests/api/helpers.rs
use argon2::{Algorithm, Argon2, Params, PasswordHasher, Version};
// [...]
impl TestUser {
// [...]
async fn store(&self, pool: &PgPool) {
let salt = SaltString::generate(&mut argon2::password_hash::rand_core::OsRng);
// We don't care about the exact Argon2 parameters here
// given that it's for testing purposes!
let password_hash = Argon2::new(
Algorithm::Argon2id,
Version::V0x13,
Params::new(15000, 2, 1, None).unwrap(),
)
.hash_password(self.password.as_bytes(), &salt)
.unwrap()
.to_string();
// [...]
}
}
现在不应该存在任何统计上显著的时间差异。
这安全吗
在构建基于密码的身份验证流程时,我们竭尽全力遵循所有最常见的最佳实践。
是时候问问自己: 它安全吗?
传输层安全 (TLS)
我们使用“基本”身份验证方案在客户端和服务器之间传递凭据: 用户名和密码已编码,但未加密。
我们必须使用传输层安全性 (TLS) 来确保没有人能够窃听客户端和服务器之间的通信,从而窃取用户凭据(即中间人攻击 - MITM)。
我们的 API 已通过 HTTPS 提供,因此此处无需执行任何操作。
密码重置
如果攻击者成功窃取一组有效的用户凭证,会发生什么?
密码不会过期——它们是长期有效的秘密。
目前,用户无法重置密码。这无疑是我们需要填补的一个空白。
互动类型
到目前为止,我们对 API 的调用者还比较模糊。
我们需要支持的交互类型是身份验证的关键决策因素。
我们将讨论三类调用者:
- 其他 API(机器对机器)
- 通过浏览器调用的人员
- 代表人员的其他 API。
机器对机器
您的 API 的使用者可能是一台机器(例如,另一个 API)。
这在微服务架构中很常见——您的功能源于各种通过网络交互的服务。
为了显著提升我们的安全性,我们必须加入一些他们拥有的功能(例如,请求签名)或他们本身的功能(例如,IP 范围限制)。
当所有服务都归同一组织所有时,一个流行的选择是相互 TLS (mTLS)。
签名和 mTLS 都依赖于公钥加密——密钥必须进行配置、轮换和管理。只有当您的系统达到一定规模时,这种开销才是合理的。
通过 OAuth2 获取客户端凭证
另一种选择是使用 OAuth2 客户端凭证。
API 不再需要管理密码(OAuth2 术语中称为客户端密钥),而将这一工作委托给集中式授权服务器。市面上有多种现成的授权服务器实现方案,包括开源软件和商业软件。您可以依赖这些方案,而不必自行开发。
调用者通过授权服务器进行身份验证,如果成功,授权服务器会授予他们一组临时凭证(JWT 访问令牌),可用于调用我们的 API。
我们的 API 可以使用公钥加密技术验证访问令牌的有效性,而无需保留任何状态。我们的 API 永远不会看到实际的密码,即客户端密钥。
JWT 验证并非没有风险,该规范充斥着危险的边缘情况。
通过浏览器的人
如果我们与使用 Web 浏览器的用户打交道会怎样?
“基本”身份验证要求客户端在每次请求时都提供其凭据。
我们现在只有一个受保护的端点,但您可以轻松想象五到十个页面提供特权功能的情形。目前,“基本”身份验证会强制用户在每一个页面上提交其凭据。这不太好。
我们需要一种方法来记住用户刚刚进行过身份验证——即将某种状态附加到来自同一浏览器的一系列请求中。这可以通过会话来实现。
用户需要通过登录表单进行一次身份验证: 如果成功,服务器将生成一次性的密钥——一个经过身份验证的会话令牌。该令牌作为安全 Cookie 存储在浏览器中。
与密码不同,会话具有过期功能——这降低了有效会话令牌被泄露的可能性(尤其是在不活动的用户自动注销的情况下)。它还可以避免用户在怀疑会话被劫持时重置密码——强制注销比自动重置密码更容易被接受。
这种方法通常被称为基于会话的身份验证。
联合身份
使用基于会话的身份验证,我们仍然需要处理一个身份验证步骤——登录表单。
我们可以继续开发自己的身份验证方案——即使我们放弃“基本”身份验证方案,我们学到的关于密码的所有知识仍然适用。
许多网站选择为用户提供额外的选项:通过社交账户登录——例如“使用 Google 登录”。这消除了注册流程中的障碍(无需再创建另一个密码!),
从而提高了转化率——这是一个理想的结果。
社交登录依赖于身份联合——我们将身份验证步骤委托给第三方身份提供商,然后他们会与我们共享我们请求的信息(例如,电子邮件地址、全名和出生日期)。
身份联合的常见实现依赖于 OpenID Connect,它是 OAuth2 标准之上的一个身份层。
机器对机器,代表一个人
还有一种场景:一个人授权一台机器(例如第三方服务)代表他们执行针对我们 API 的操作。
例如,一个为 Twitter 提供替代 UI 的移动应用。
需要强调的是,这与我们讨论的第一个场景(纯粹的机器对机器身份验证)有何不同。
在这种情况下,第三方服务本身无权针对我们的 API 执行任何操作。
第三方服务只有在用户授予访问权限(访问权限范围在其权限范围内)的情况下才能针对我们的 API 执行操作。
我可以安装一个移动应用来代表我发推文,但我不能授权它代表 David Guetta 发推文。
在这种情况下,“基本”身份验证非常不合适:我们不想与第三方应用共享密码。
看到我们密码的人越多,密码被泄露的可能性就越大。
此外,保留共享凭证的审计线索简直是一场噩梦。当出现问题时, 我们无法确定是谁做了什么: 是我做的吗? 是我共享凭证的二十个应用之一吗?
谁来承担责任?
这是 OAuth2 的典型场景——第三方永远无法看到我们的用户名和密码。他们从身份验证服务器收到一个不透明的访问令牌,我们的 API 知道如何检查该令牌,以授予(或拒绝)访问权限。
插曲:后续步骤
浏览器是我们的主要目标——这已经决定了。我们的身份验证策略也需要随之改进!
我们将首先将“基本”身份验证流程转换为基于会话的登录表单。
我们将从头构建一个管理面板。它将包含一个登录表单、一个注销链接以及一个用于更改密码的表单。这将使我们有机会讨论一些安全挑战(例如 XSS),介绍一些新概念(例如 Cookie、HMAC 标签)并尝试一些新工具(例如 Flash消息、actix-session)。
让我们开始工作吧!
登录表单
提供 HTML 页面
到目前为止,我们已经避开了浏览器和网页的复杂性——这有助于我们减少在学习初期需要学习的新概念数量。
现在,我们已经积累了足够的专业知识来完成这一步——我们将处理 HTML 页面和登录表单的有效负载提交。
让我们从基础开始: 如何从 API 返回 HTML 页面? 我们可以从添加一个虚拟主页端点开始。
//! src/routes.rs
// [...]
mod home;
pub use home::*;
//! src/routes/home.rs
use actix_web::HttpResponse;
pub async fn home() -> HttpResponse {
HttpResponse::Ok().finish()
}
//! src/startup.rs
use crate::routes::home;
// [...]
pub fn run(
// [...]
) -> Result</*[...]*/> {
// [...]
let server = HttpServer::new(move || {
App::new()
// [...]
.route("/", web::get().to(home))
// [...]
})
// [...]
}
这里没什么可看的——我们只是返回了一个 200 OK 状态码,没有正文。
让我们添加一个非常简单的 HTML 落地页:
<!-- src/routes/home/home.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<title>Home</title>
</head>
<body>
<p>Welcome to our newsletter!</p>
</body>
</html>
我们希望读取此文件并将其作为 GET / 端点的主体返回。
我们可以使用 include_str!, 这是 Rust 标准库中的一个宏: 它读取给定路径下的文件并将其内容作为 &'static str 返回。
这是可能的,因为 include_str! 在编译时运行 - 文件内容存储为应用程序二进制文件的一部分,因此确保指向其内容的指针 (&str) 保持有效无限期 ('static)
//! src/routes/home.rs
// [...]
pub async fn home() -> HttpResponse {
HttpResponse::Ok().body(include_str!("home/home.html"))
}
如果你使用 cargo run 启动你的应用程序,并在浏览器中访问 http://localhost:8000,你应该会看到“欢迎阅读我们的新闻通讯!”的消息。
不过,浏览器并不完全满意——如果你打开浏览器的 console ,你应该会看到一条警告。
在 Firefox 93.0 上:
HTML 文档的字符编码未声明。 如果文档包含 US-ASCII 范围之外的字符,则在某些浏览器配置下,文档将呈现乱码。 页面的字符编码必须在文档或传输协议中声明。
换句话说,浏览器已经推断出我们返回的是 HTML 内容,但它 更希望得到明确的提示。
我们有两个选择:
- 在文档中添加一个特殊的 HTML 元标记;
- 设置 Content-Type HTTP 标头(“传输协议”)。
最好两者兼顾。
将信息嵌入文档内部对浏览器和机器人爬虫(例如 Googlebot)来说效果很好,而 Content-Type HTTP 标头不仅能被浏览器识别,还能被所有 HTTP 客户端识别。
返回 HTML 页面时,内容类型应设置为 text/html; charset=utf-8。
让我们添加它:
<!DOCTYPE html>
<html lang="en">
<head>
<!-- This is equivalent to a HTTP header -->
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<title>Home</title>
</head>
<!-- [...] -->
</html>
//! src/routes/home.rs
// [...]
pub async fn home() -> HttpResponse {
HttpResponse::Ok()
.content_type(ContentType::html())
.body(include_str!("home/home.html"))
}
警告应该已经从浏览器控制台中消失了。
恭喜,您刚刚提供了第一个格式正确的网页!
登录
让我们开始处理登录表单。
我们需要连接一个端点占位符,就像之前对 GET / 所做的那样。我们将在 GET /login 中提供登录表单。
//! src/routes.rs
// [...]
// New module!
mod login;
pub use login::*;
//! src/routes/login.rs
mod get;
pub use get::login_form;
//! src/routes/login/get.rs
use actix_web::HttpResponse;
pub async fn login_form() -> HttpResponse {
HttpResponse::Ok().finish()
}
//! src/startup.rs
// [...]
pub fn run(
// [...]
) -> Result<Server, std::io::Error> {
// [...]
let server = HttpServer::new(move || {
App::new()
// [...]
.route("/login", web::get().to(login_form))
// [...]
})
// [...]
}
HTML 表单
这次 HTML 会更加复杂:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<title>Login</title>
</head>
<body>
<form>
<label>Username
<input type="text" placeholder="Enter Username" name="username">
</label>
<label>Password
<input type="password" placeholder="Enter password" name="password">
</label>
<button type="submit">Login</button>
</form>
</body>
</html>
//! src/routes/login/get.rs
use actix_web::{HttpResponse, http::header::ContentType};
pub async fn login_form() -> HttpResponse {
HttpResponse::Ok()
.content_type(ContentType::html())
.body(include_str!("login.html"))
}
form 是执行繁重工作的 HTML 元素。它的作用是收集一组数据字段,并将它们发送到后端服务器进行处理。
这些字段使用 input 元素定义——这里有两个: 用户名和密码。
输入元素被赋予 type 属性——它告诉浏览器如何显示它们。
text 和 password 都将呈现为单行自由文本字段,但有一个关键区别:
输入到密码字段的字符会被混淆。
每个输入元素都包裹在一个 label 元素中:
- 点击标签名称可切换输入字段
- 它提高了屏幕阅读器用户的可访问性(当用户将焦点放在元素上时,会大声读出)。
我们为每个输入元素设置了另外两个属性:
placeholder, 其值在用户开始填写表单之前在文本字段中显示为建议值;name, 我们必须在后端使用该键来识别已提交表单数据中的字段值。
表单末尾有一个按钮,它会触发将提供的输入提交到后端。
如果您输入随机的用户名和密码并尝试提交,会发生什么?
页面会刷新,输入字段会被重置——但 URL 已经改变了!
现在应该是 localhost:8000/login?username=myusername&password=mysecretpassword。
这是表单的默认行为—— form 使用 GET HTTP 动词将数据提交到它所服务的同一页面(即 /login)。这远非理想情况——正如您刚刚看到的,通过 GET 提交的表单会将所有输入数据以明文形式编码为查询参数。作为 URL 的一部分,它们最终会被存储为浏览器的导航历史记录。查询参数也会被捕获到日志中(例如,我们自己后端的 http.route 属性)。
我们真的不希望在那里存储密码或任何类型的敏感数据。
我们可以通过设置 form 上的 action 和 method 的值来改变这种行为:
<!-- src/routes/login/login.html -->
<!-- [...] -->
<form action="/login" method="post"></form>
<!-- [...] -->
从技术上讲,我们可以省略 action,但默认行为的文档记录并不详尽,因此明确定义它会更清晰。
由于 method="post", 输入数据将通过请求主体传递到后端,这是一个更安全的选择。
如果您尝试再次提交表单,您应该会在 POST /login 的 API 日志中看到 404 错误。让我们定义端点!
//! src/routes/login.rs
// [...]
mod post;
pub use post::login;
//! src/routes/login/post.rs
use actix_web::HttpResponse;
pub async fn login() -> HttpResponse {
HttpResponse::Ok().finish()
}
//! src/startup.rs
use crate::routes::login;
// [...]
pub fn run(
listener: TcpListener,
db_pool: PgPool,
email_client: EmailClient,
base_url: String,
) -> Result<Server, std::io::Error> {
// [...]
let server = HttpServer::new(move || {
App::new()
// [...]
.route("/login", web::post().to(login))
// [...]
})
// [...]
}
成功后重定向
尝试重新登录:表单将消失,您将看到一个空白页面。这不是 最好的反馈方式——理想情况下,显示一条确认用户已登录的消息才是理想的。此外,如果用户尝试刷新页面,浏览器会提示他们确认是否要再次提交表单。
我们可以通过使用重定向来改善这种情况——如果身份验证成功,我们会指示浏览器导航回我们的主页。
重定向响应需要两个元素:
- 重定向状态码;
- Location 标头,设置为我们要重定向到的 URL。
所有重定向状态码都在 3xx 范围内——我们需要根据 HTTP 动词和我们想要传达的语义(例如,临时重定向还是永久重定向)选择最合适的重定向。
您可以在 MDN Web 文档中找到完整的指南。303 See Other 最适合我们的用例(表单提交后的确认页面):
//! src/routes/login/post.rs
use actix_web::{HttpResponse, http::header::LOCATION};
pub async fn login() -> HttpResponse {
HttpResponse::SeeOther()
.insert_header((LOCATION, "/"))
.finish()
}
提交表单后,您现在应该会看到 "Welcome to our newsletter!"。
处理表单数据
说实话,我们并不是在成功时重定向——我们一直在重定向。
我们需要增强登录功能,以便真正验证传入的凭据。
正如我们在第 3 章中看到的,表单数据使用 application/x-www-form-urlencoded 内容类型提交到后端。
我们可以使用 actix-web 的表单提取器和一个实现 serde::Deserialize 的结构体从传入请求中解析出它:
//! src/routes/login/post.rs
// [...]
use actix_web::{HttpResponse, http::header::LOCATION, web};
use secrecy::SecretString;
#[derive(serde::Deserialize)]
pub struct FormData {
username: String,
password: SecretString,
}
pub async fn login(_form: web::Form<FormData>) -> HttpResponse {
// [...]
}
我们在本章前面部分构建了基于密码的身份验证的基础 - 让我们 再次看一下 POST /newsletters 处理程序中的授权码:
//! src/routes/newsletters.rs
// [...]
#[tracing::instrument(
name = "Publish a newsletter issue",
skip(body, pool, email_client, request),
fields(username=tracing::field::Empty, user_id=tracing::field::Empty)
)]
pub async fn publish_newsletter(
body: web::Json<BodyData>,
pool: web::Data<PgPool>,
email_client: web::Data<EmailClient>,
request: HttpRequest,
) -> Result<HttpResponse, PublishError> {
let credentials = basic_authentication(request.headers())
// Bubble up the error, performing the necessary conversion
.map_err(PublishError::AuthError)?;
tracing::Span::current().record("username", tracing::field::display(&credentials.username));
let user_id = validate_credentials(credentials, &pool).await?;
tracing::Span::current().record("user_id", tracing::field::display(user_id));
// [...]
}
basic_authentication 处理从 Authorization 标头中提取凭据当使用"Basic"身份验证方案时——我们不想在登录时重复使用它。
validation_credentials 才是我们想要的: 它以用户名和密码作为输入,返回相应的 user_id(如果身份验证成功)或错误(如果凭据无效)。
validation_credentials 的当前定义受到 publish_newsletters 关注点的影响:
//! src/routes/newsletters.rs
// [...]
async fn validate_credentials(
credentials: Credentials,
pool: &PgPool,
) -> Result<uuid::Uuid, PublishError> {
let mut user_id = None;
let mut expected_password_hash = SecretString::from(
"$argon2id$v=19$m=15000,t=2,p=1$\
gZiV/M1gPc22ElAH/Jh1Hw$\
CWOrkoo7oJBQ/iyh7uJ0LO2aLEfrHwTWllSAxT0zRno"
.to_string(),
);
if let Some((stored_user_id, stored_password_hash)) =
get_stored_credentials(&credentials.username, pool)
.await
.map_err(PublishError::UnexpectedError)?
{
user_id = Some(stored_user_id);
expected_password_hash = stored_password_hash
}
spawn_blocking_with_tracing(move || {
verify_password_hash(expected_password_hash, credentials.password)
})
.await
.context("Invalid password")
.map_err(PublishError::AuthError)??;
user_id.ok_or_else(|| PublishError::AuthError(anyhow::anyhow!("Unknown username.")))
}
构建一个 authentication 模块
让我们重构 validate_credentials, 以便为提取做好准备——我们想要构建一个共享的身份验证模块,它将在
POST /login 和 POST /newsletters 中同时使用。
让我们定义一个新的错误枚举 AuthError:
//! src/lib.rs
pub mod authentication;
//! src/authentication.rs
#[derive(thiserror::Error, Debug)]
pub enum AuthError {
#[error("Invalid credentials.")]
InvalidCredentials(#[source] anyhow::Error),
#[error(transparent)]
UnexpectedError(#[from] anyhow::Error),
}
我们使用枚举,是因为就像我们在 POST /newsletters 中所做的那样, 我们希望能够让调用者根据错误类型做出不同的响应 - 例如,对于 UnexpectedError 返回 500,而对于 AuthErrors 则返回 401。
现在,让我们将 validate_credentials 的签名更改为返回 Result<uuid::Uuid, AuthError>:
//! src/routes/newsletters.rs
usae crate::authentication::AuthError;
// [...]
async fn validate_credentials(
credentials: Credentials,
pool: &PgPool,
) -> Result<uuid::Uuid, AuthError> {
let mut user_id = None;
let mut expected_password_hash = SecretString::from(
"$argon2id$v=19$m=15000,t=2,p=1$\
gZiV/M1gPc22ElAH/Jh1Hw$\
CWOrkoo7oJBQ/iyh7uJ0LO2aLEfrHwTWllSAxT0zRno"
.to_string(),
);
if let Some((stored_user_id, stored_password_hash)) =
get_stored_credentials(&credentials.username, pool).await?
{
user_id = Some(stored_user_id);
expected_password_hash = stored_password_hash
}
spawn_blocking_with_tracing(move || {
verify_password_hash(expected_password_hash, credentials.password)
})
.await
.context("Invalid password")??;
user_id
.ok_or_else(|| anyhow::anyhow!("Unknown username."))
.map_err(AuthError::InvalidCredentials)
}
cargo check 返回了两个错误
error[E0277]: `?` couldn't convert the error to `PublishError`
--> src/routes/newsletters.rs:85:65
|
85 | let user_id = validate_credentials(credentials, &pool).await?;
| ----------------------------------------------^ the trait `std::convert::Fro
m<AuthError>` is not implemented for `PublishError`
| |
| this can't be annotated with `?` because it has type `Result<_, AuthError>`
|
error[E0277]: `?` couldn't convert the error to `AuthError`
--> src/routes/newsletters.rs:206:34
|
202 | / spawn_blocking_with_tracing(move || {
203 | | verify_password_hash(expected_password_hash, credentials.password)
204 | | })
205 | | .await
206 | | .context("Invalid password")??;
| | -^ the trait `std::convert::From<PublishError>` is not impl
emented for `AuthError`
| |_________________________________|
| this can't be annotated with `?` because it has type `Resul
t<_, PublishError>`
|
第一个错误来自 validate_credentials 本身——我们正在调用 verify_password_hash, 它仍然返回 PublishError。
//! src/routes/newsletters.rs
// [...]
fn verify_password_hash(
expected_password_hash: SecretString,
password_candidate: SecretString,
) -> Result<(), PublishError> {
let expected_password_hash = PasswordHash::new(expected_password_hash.expose_secret())
.context("Failed to parse hash in PHC string format.")
.map_err(PublishError::UnexpectedError)?;
Argon2::default()
.verify_password(
password_candidate.expose_secret().as_bytes(),
&expected_password_hash,
)
.context("Invalid password.")
.map_err(PublishError::AuthError)
}
让我们修正它:
//! src/routes/newsletters.rs
// [...]
fn verify_password_hash(
expected_password_hash: SecretString,
password_candidate: SecretString,
) -> Result<(), AuthError> {
let expected_password_hash = PasswordHash::new(expected_password_hash.expose_secret())
.context("Failed to parse hash in PHC string format.")?;
Argon2::default()
.verify_password(
password_candidate.expose_secret().as_bytes(),
&expected_password_hash,
)
.context("Invalid password.")
.map_err(AuthError::InvalidCredentials)
}
让我们处理第二个错误:
--> src/routes/newsletters.rs:85:65
|
85 | let user_id = validate_credentials(credentials, &pool).await?;
| ----------------------------------------------^ the trait `std::convert::Fro
m<AuthError>` is not implemented for `PublishError`
| |
| this can't be annotated with `?` because it has type `Result<_, AuthError>`
|
这源于在请求处理程序 publish_newsletters 中对 verify_credentials 的调用。
AuthError 未实现到 PublishError 的转换,因此无法使用 ? 运算符。
我们将调用 map_err 来内联执行映射:
//! src/routes/newsletters.rs
// [...]
pub async fn publish_newsletter(
body: web::Json<BodyData>,
pool: web::Data<PgPool>,
email_client: web::Data<EmailClient>,
request: HttpRequest,
) -> Result<HttpResponse, PublishError> {
// [...]
let user_id = validate_credentials(credentials, &pool)
.await
// We match on `AuthError`'s variants, bit we pass the **whole** error
// into the constructors for `PublishError` variants. This ensures that
// the context of the top-level wrapped is preserved when the error is
// logged by our middleware.
.map_err(|e| match e {
AuthError::InvalidCredentials(_) => PublishError::AuthError(e.into()),
AuthError::UnexpectedError(_) => PublishError::UnexpectedError(e.into()),
})?;
// [...]
}
现在代码应该可以编译通过了
让我们通过将 validate_credentials、Credentials、get_stored_credentials
和 verify_password_hash 移到 authentication 模块来完成提取:
//! src/authentication.rs
use anyhow::Context;
use argon2::{Argon2, PasswordHash, PasswordVerifier};
use secrecy::{ExposeSecret, SecretString};
use sqlx::PgPool;
use crate::telemetry::spawn_blocking_with_tracing;
// [...]
pub struct Credentials {
// These two fields were not marked as `pub` before!
pub username: String,
pub password: SecretString,
}
#[tracing::instrument(/* */)]
pub async fn validate_credentials(/* */) -> Result<uuid::Uuid, AuthError> {
// [...]
}
#[tracing::instrument(/* */)]
fn verify_password_hash(/* */) -> Result<(), AuthError> {
// [...]
}
#[tracing::instrument(/* */)]
async fn get_stored_credentials(/* */) -> Result<Option<(uuid::Uuid, SecretString)>, anyhow::Error> {
// [...]
}
//! src/routes/newsletters.rs
// [...]
use crate::authentication::{validate_credentials, AuthError, Credentials};
// There will be warnings about unused imports, follow the compiler to fix them!
// [...]
拒绝无效凭证
提取的 authentication 模块现在可以在我们的 login 函数中使用了。
让我们将其插入:
//! src/routes/login/post.rs
use actix_web::{HttpResponse, http::header::LOCATION, web};
use secrecy::SecretString;
use sqlx::PgPool;
use crate::authentication::{Credentials, validate_credentials};
#[derive(serde::Deserialize)]
pub struct FormData {
username: String,
password: SecretString,
}
#[tracing::instrument(
skip(form, pool),
fields(username=tracing::field::Empty, user_id=tracing::field::Empty)
)]
pub async fn login(form: web::Form<FormData>, pool: web::Data<PgPool>) -> HttpResponse {
let credentials = Credentials {
username: form.0.username,
password: form.0.password,
};
tracing::Span::current().record("username", tracing::field::display(&credentials.username));
match validate_credentials(credentials, &pool).await {
Ok(user_id) => {
tracing::Span::current().record("user_id", tracing::field::display(&user_id));
HttpResponse::SeeOther()
.insert_header((LOCATION, "/"))
.finish()
}
Err(_) => {
todo!()
}
}
}
使用随机凭证的登录尝试现在应该会失败:请求处理程序会因为 validation_credentials 返回错误而崩溃,进而导致 actix-web 断开连接。
这并非优雅的失败——浏览器可能会显示类似以下内容: 连接已重置。
我们应该尽可能避免请求处理程序中出现崩溃——所有错误都应该优雅地处理。
让我们引入一个 LoginError:
//! src/routes/login/post.rs
// [...]
use actix_web::{
HttpResponse, ResponseError,
http::{StatusCode, header::LOCATION},
web,
};
use crate::{
authentication::{Credentials, validate_credentials},
routes::error_chain_fmt,
};
#[derive(serde::Deserialize)]
pub struct FormData {
username: String,
password: SecretString,
}
#[tracing::instrument(
skip(form, pool),
fields(username=tracing::field::Empty, user_id=tracing::field::Empty)
)]
pub async fn login(
form: web::Form<FormData>,
pool: web::Data<PgPool>,
) -> Result<HttpResponse, LoginError> {
// [...]
let user_id = validate_credentials(credentials, &pool)
.await
.map_err(|e| match e {
AuthError::InvalidCredentials(_) => LoginError::AuthError(e.into()),
AuthError::UnexpectedError(_) => LoginError::UnexpectedError(e.into()),
})?;
tracing::Span::current().record("user_id", tracing::field::display(&user_id));
Ok(HttpResponse::SeeOther()
.insert_header((LOCATION, "/"))
.finish())
}
#[derive(thiserror::Error)]
pub enum LoginError {
#[error("Authentication failed")]
AuthError(#[source] anyhow::Error),
#[error("Something went wrong")]
UnexpectedError(#[from] anyhow::Error),
}
impl std::fmt::Debug for LoginError {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
error_chain_fmt(self, f)
}
}
impl ResponseError for LoginError {
fn status_code(&self) -> actix_web::http::StatusCode {
match self {
LoginError::UnexpectedError(_) => StatusCode::INTERNAL_SERVER_ERROR,
LoginError::AuthError(_) => StatusCode::UNAUTHORIZED,
}
}
}
这段代码与我们之前重构 POST /newsletters 时编写的代码非常相似。
这会对浏览器产生什么影响?
提交表单会触发页面加载,导致屏幕上显示"Authentication failed"。
比以前好多了,我们正在取得进展!
语境错误
错误信息已经足够清晰了——但用户接下来应该怎么做呢?
我们合理地假设他们想再次尝试输入凭证——他们可能拼错了用户名或密码。
我们需要将错误信息显示在登录表单的顶部——为用户提供信息,同时允许他们快速重试。
简单实现
最简单的方法是什么?
我们可以从 ResponseError 返回登录 HTML 页面,并注入一个额外的段落 (<p>
HTML 元素) 来向用户报告错误。
它看起来应该像这样:
//! src/routes/login/post.rs
// [...]
impl ResponseError for LoginError {
fn status_code(&self) -> actix_web::http::StatusCode {
// [...]
}
fn error_response(&self) -> HttpResponse<actix_web::body::BoxBody> {
HttpResponse::build(self.status_code())
.content_type(ContentType::html())
.body(format!(
r#"<!DOCTYPE html>
<html lang="en">
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<title>Login</title>
</head>
<body>
<p><i>{}</i></p>
<form action="/login" method="post">
<label>Username
<input
type="text"
placeholder="Enter Username"
name="username"
>
</label>
<label>Password
<input
type="password"
placeholder="Enter Password"
name="password"
>
</label>
<button type="submit">Login</button>
</form>
</body>
</html>
"#,
self
))
}
}
这种方法有几个缺点:
-
我们有两个略有不同但几乎完全相同的登录页面,定义在两个不同的地方。 如果我们决定修改登录表单,我们需要记住同时修改这两个页面
-
如果用户在登录失败后尝试刷新页面,系统会提示用户确认是否重新提交表单。
为了解决第二个问题,我们需要让用户登录到 GET 端点。
为了解决第一个问题,我们需要找到一种方法来重用我们在 GET /login 中编写的 HTML, 而不是复制它。
我们可以通过另一个重定向来实现这两个目标:如果身份验证失败,我们会将用户返回到 GET /login。
//! src/routes/login/post.rs
// [...]
impl ResponseError for LoginError {
fn error_response(&self) -> HttpResponse<actix_web::body::BoxBody> {
HttpResponse::build(self.status_code())
.insert_header((LOCATION, "/login"))
.finish()
}
fn status_code(&self) -> StatusCode {
StatusCode::SEE_OTHER
}
}
不幸的是,普通的重定向是不够的——浏览器会再次向用户显示登录表单,而且没有任何反馈来解释他们的登录尝试失败。
我们需要找到一种方法来指示 GET /login 显示错误消息。
让我们来探索一些方案。
查询参数
Location 标头的值决定了用户将被重定向到的 URL。
但这还不够——我们还可以指定查询参数!
让我们将身份验证错误消息编码到错误查询参数中。
查询参数是 URL 的一部分——因此我们需要对 LoginError 的显示表示进行 URL 编码。
#! Cargo.toml
# [...]
[dependencies]
urlencoding = "2"
impl ResponseError for LoginError {
fn error_response(&self) -> HttpResponse<actix_web::body::BoxBody> {
let encoded_error = urlencoding::Encoded::new(self.to_string());
HttpResponse::build(self.status_code())
.insert_header((LOCATION, format!("/login?error={encoded_error}")))
.finish()
}
// [...]
}
然后可以在 GET /login 的请求处理程序中提取错误查询参数。
//! src/routes/login/get.rs
use actix_web::{HttpResponse, http::header::ContentType, web};
#[derive(serde::Deserialize)]
pub struct QueryParams {
error: Option<String>,
}
pub async fn login_form(query: web::Query<QueryParams>) -> HttpResponse {
let _error = query.0.error;
HttpResponse::Ok()
.content_type(ContentType::html())
.body(include_str!("login.html"))
}
最后,我们可以根据其值定制返回的 HTML 页面:
//! src/routes/login/get.rs
// [...]
pub async fn login_form(query: web::Query<QueryParams>) -> HttpResponse {
let error_html = match query.0.error {
None => "".into(),
Some(error_message) => format!("<p><i>{error_message}</i><p>"),
};
HttpResponse::Ok()
.content_type(ContentType::html())
.body(format!(
r#"<!DOCTYPE html>
<html lang="en">
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<title>Login</title>
</head>
<body>
{error_html}
<form action="/login" method="post">
<label>Username
<input
type="text"
placeholder="Enter Username"
name="username"
>
</label>
<label>Password
<input
type="password"
placeholder="Enter Password"
name="password"
>
</label>
<button type="submit">Login</button>
</form>
</body>
</html>
"#
))
}
有用!
跨站脚本(XSS)
查询参数并非私密信息 - 我们的后端服务器无法阻止用户修改 URL。
尤其无法阻止攻击者利用这些参数。
请尝试访问以下 URL:
http://localhost:8000/login?error=Your%20account%20has%20been%20locked%2C%20 please%20submit%20your%20details%20%3Ca%20href%3D%22https%3A%2F%2Fzero2prod.com %22%3Ehere%3C%2Fa%3E%20to%20resolve%20the%20issue
在登录表单顶部,您将看到
Your account has been locked, please submit your details here to resolve the issue.
这里是一个指向另一个网站的链接(在本例中为 zero2prod.com)。
在更现实的情况下,这里会链接到一个由攻击者控制的网站,诱使受害者泄露其登录凭据。
这被称为跨站脚本攻击 (XSS)。
攻击者利用来自不可信来源(例如用户输入、查询参数等)的动态内容,将 HTML 片段或 JavaScript 代码段注入受信任的网站。
从用户的角度来看,XSS 攻击尤其隐蔽——URL 与您想要访问的 URL 匹配, 因此您很可能会信任显示的内容。
OWASP 提供了一份关于如何预防 XSS 攻击的详尽备忘单——如果您正在开发 Web 应用程序,我强烈建议熟悉它。
让我们看一下针对我们问题的指南:我们希望在 HTML 元素中显示不受信任的数据(查询参数的值) (<p><i>此处显示不受信任的数据</i></p>)。
根据 OWASP 的指南,我们必须对不受信任的输入进行 HTML 实体编码,即:
- 将
&转换为& - 将
<转换为< - 将
>转换为> - 将
"转换为" - 将
'转换为' - 将
/转换为/
HTML 实体编码通过转义定义 HTML 元素所需的字符来阻止插入其他 HTML 元素。
让我们修改 login_form 处理程序:
#! Cargo.toml
# [...]
[dependencies]
htmlescape = "0.3"
//! src/routes/login/get.rs
// [...]
pub async fn login_form(query: web::Query<QueryParams>) -> HttpResponse {
let error_html = match query.0.error {
None => "".into(),
Some(error_message) => format!(
"<p><i>{}</i><p>",
htmlescape::encode_minimal(&error_message)
),
};
// [...]
}
再次加载受损的 URL - 您将看到不同的消息:
Your account has been locked, please submit your details
<a href=“https://zero2prod.com”>here</a>to resolve the issue.
HTML a 元素不再被浏览器渲染——用户现在有理由怀疑有什么不对劲。
这样就够了吗?
至少,与直接点击相比,用户不太可能复制粘贴并导航到链接。
尽管如此,攻击者并非天真——一旦他们注意到我们的网站正在执行 HTML 实体编码,他们就会立即修改注入的消息。
这可能很简单:
Your account has been locked, please call +CC3332288777 to resolve the issue.
这或许足以引诱几个受害者。我们需要比角色逃脱更强的手段。
消息认证码
我们需要一种机制来验证查询参数是否已由我们的 API 设置,并且未被第三方更改。
这被称为消息认证——它保证消息在传输过程中未被修改(完整性),并允许您验证发送者的身份(数据源认证)。
消息认证码 (MAC) 是一种常用的消息认证技术——在消息中添加一个标签,允许验证者检查其完整性和来源。
HMAC 是一个著名的 MAC 系列——基于哈希的消息认证码。
HMAC 围绕一个密钥和一个哈希函数构建。
密钥被添加到消息的前面,并将生成的字符串输入到哈希函数中。
然后将生成的哈希值与密钥连接起来,再次进行哈希运算——输出就是消息标签。
伪代码如下:
let hmac_tag = hash(
concat(
key,
hash(concat(key, message))
)
);
我们特意省略了有关键填充的一些细微差别——您可以在 RFC 2104 中找到所有详细信息。
添加 HMAC 标签来保护查询参数
让我们尝试使用 HMAC 来验证查询参数的完整性和来源。
Rust Crypto 组织提供了 HMAC 的实现,即 hmac crate。我们还需要一个哈希函数——我们选择 SHA-256。
#! Cargo.toml
# [...]
[dependencies]
hmac = { version = "0.12", features = ["std"] }
sha2 = "0.10"
让我们在 Location header 中添加另一个查询参数 tag,用于存储错误消息的 HMAC。
//! src/routes/login/post.rs
use hmac::{Hmac, Mac};
// [...]
impl ResponseError for LoginError {
fn error_response(&self) -> HttpResponse<actix_web::body::BoxBody> {
let query_string = format!("error={}", urlencoding::Encoded::new(self.to_string()));
// We need the secret there - how do we get it?
let secret: &[u8] = todo!();
let hmac_tag = {
let mut mac = Hmac::<sha2::Sha256>::new_from_slice(secret).unwrap();
mac.finalize().into_bytes()
};
HttpResponse::build(self.status_code())
// Appending the hexadecimal representation of the HMAC tag to the
// query string as an additional query parameter.
.insert_header((LOCATION, format!("/login?{query_string}&tag={hmac_tag:x}")))
.finish()
}
// [...]
}
这段代码几乎完美了——我们只需要一种方法来获取密钥!
可惜的是,这在 ResponseError 内部无法实现——我们只能访问我们试图转换为 HTTP 响应的错误类型 (LoginError)。ResponseError 只是一个特化的 Into trait。
具体来说,我们无法访问应用程序状态(即我们无法使用 web::Data
提取器),而这正是我们存储密钥的地方。
让我们将代码移回请求处理程序:
//! src/routes/login/post.rs
use secret::ExposeSecret;
// [...]
pub async fn login(
form: web::Form<FormData>,
pool: web::Data<PgPool>,
// Injecting the secret as a secret string for the time being.
secret: web::Data<SecretString>,
// No longer returning a `Result<HttpResponse, LoginError>`~
) -> HttpResponse {
// [...]
match validate_credentials(credentials, &pool).await {
Ok(user_id) => {
tracing::Span::current().record("user_id", &tracing::field::display(&user_id));
HttpResponse::SeeOther()
.insert_header((LOCATION, "/"))
.finish()
}
Err(e) => {
let e = match e {
AuthError::InvalidCredentials(_) => LoginError::AuthError(e.into()),
AuthError::UnexpectedError(_) => LoginError::UnexpectedError(e.into()),
};
let query_string = format!("error={}", urlencoding::Encoded::new(e.to_string()));
let hmac_tag = {
let mut mac =
Hmac::<sha2::Sha256>::new_from_slice(secret.expose_secret().as_bytes())
.unwrap();
mac.update(query_string.as_bytes());
mac.finalize().into_bytes()
};
HttpResponse::SeeOther()
.insert_header((
LOCATION,
format!("/login?{}&tag={:x}", query_string, hmac_tag),
))
.finish()
}
}
}
// The `ResponseError` implementation for `LoginError` has been deleted.
这是一种可行的方法,而且可以编译通过。
但它有一个缺点——我们不再将错误上下文传播到上游中间件链。
这在处理 LoginError::UnexpectedError 时会令人担忧——我们的日志应该
真正捕获出错的地方。
幸运的是,有一种方法可以鱼与熊掌兼得: actix_web::error::InternalError。
InternalError 可以由 HttpResponse 和错误构建。它可以作为错误从请求处理程序(它实现了 ResponseError 接口)返回,并将你传递给其构造函数的 HttpResponse 返回给调用者——这正是我们所需要的!
让我们再次修改登录方法以使用它:
//! src/routes/login/post.rs
// [...]
// Returning a `Result` again!
pub async fn login(
// [...]
) -> Result<HttpResponse, InternalError<LoginError>> {
// [...]
match validate_credentials(credentials, &pool).await {
Ok(user_id) => {
// [...]
// We need to Ok-wrap again
Ok(/* */)
}
Err(e) => {
// [...]
let response = HttpResponse::SeeOther()
.insert_header((
LOCATION,
format!("/login?{}&tag={:x}", query_string, hmac_tag),
))
.finish();
Err(InternalError::from_response(e, response))
}
}
}
错误报告已保存。
我们还剩最后一个任务: 将 HMAC 使用的密钥注入应用程序状态。
//! src/configuration.rs
// [...]
#[derive(serde::Deserialize, Clone)]
pub struct ApplicationSettings {
// [...]
pub hmac_secret: SecretString,
}
//! src/startup.rs
use secrecy:::SecretString;
// [...]
impl Application {
pub async fn build(configuration: Settings) -> Result<Self, std::io::Error> {
// [...]
let server = run(
listener,
connection_pool,
email_client,
configuration.application.base_url,
configuration.application.hmac_secret,
)?;
}
// [...]
}
pub fn run(
// [...]
hmac_secret: SecretString,
) -> Result<Server, std::io::Error> {
// [...]
let server = HttpServer::new(move || {
App::new()
// [...]
.app_data(web::Data::new(hmac_secret.clone()))
})
// [...]
}
#! configuration/base.yml
application:
# [...]
# You need to set the `APP_APPLICATION__HMAC_SECRET` environment variable
# on Digital Ocean as well for production!
hmac_secret: "super-long-and-secret-random-key-needed-to-verify-message-integrity"
# [...]
使用 SecretString 作为注入应用状态的类型远非理想。String 是一种原始类型,存在很大的冲突风险——例如,另一个中间件或服务会注册另一个 SecretString 到应用状态,从而覆盖我们的 HMAC 密钥(反之亦然)。
让我们创建一个包装器类型来规避这个问题:
//! src/startup.rs
// [...]
#[derive(Clone)]
pub struct HmacSecret(pub Secret<String>);
pub fn run(
hmac_secret: SecretString,
) -> Result<Server, std::io::Error> {
// [...]
let server = HttpServer::new(move || {
App::new()
// [...]
.app_data(web::Data::new(HmacSecret(hmac_secret.clone())))
})
// [...]
}
//! src/routes/login/post.rs
use crate::startup::HmacSecret;
// [...]
#[tracing::instrument(
skip(/* */, secret),
fields(/* */)
)]
pub async fn login(
// [...]
// Injec the wrapper type!
secret: web::Data<HmacSecret>,
) -> Result<HttpResponse, InternalError<LoginError>> {
// [...]
match validate_credentials(credentials, &pool).await {
Ok(/* */) => { /* */ }
Err(e) => {
// [...]
let hmac_tag = {
let mut mac =
Hmac::<sha2::Sha256>::new_from_slice(secret.0.expose_secret().as_bytes())
.unwrap();
// [...]
};
// [...]
}
}
}
验证 HMAC 标签
是时候在 GET /login 中验证该标签了!
让我们从提取标签查询参数开始。
我们目前正在使用查询提取器将传入的查询参数解析为 QueryParams 结构体,该结构体包含一个可选的错误字段。
展望未来,我们预计会出现两种情况:
- 没有错误(例如,您刚刚进入登录页面),因此我们不需要任何查询参数;
- 需要报告错误,因此我们预计会同时看到错误和标签查询 参数。
将 QueryParams 从
#[derive(serde::Deserialize)]
pub struct QueryParams {
error: Option<String>,
}
修改为
#[derive(serde::Deserialize)]
pub struct QueryParams {
error: Option<String>,
tag: Option<String>,
}
无法准确捕捉新的需求——它会允许调用者传递标签参数,而忽略错误参数,反之亦然。我们需要在请求处理程序中进行额外的验证,以确保不会出现这种情况。
我们可以完全避免这个问题,方法是将 QueryParams 中的所有字段设为必填字段,而 QueryParams 本身则变为可选字段:
//! src/routes/login/get.rs
// [...]
#[derive(serde::Deserialize)]
pub struct QueryParams {
error: String,
tag: String,
}
pub async fn login_form(query: Option<web::Query<QueryParams>>) -> HttpResponse {
let error_html = match query {
None => "".into(),
Some(query) => format!("<p><i>{}</i><p>", htmlescape::encode_minimal(&query.error)),
};
// [...]
}
温馨提示: 非法状态无法用类型表示!
为了验证标签,我们需要访问 HMAC 共享密钥——让我们注入它:
//! src/routes/login/get.rs
use crate::startup::HmacSecret;
// [...]
pub async fn login_form(
query: Option<web::Query<QueryParams>>,
secret: web::Data<HmacSecret>,
) -> HttpResponse {
// [...]
}
tag 是一个编码为十六进制字符串的字节切片。我们需要十六进制 crate 在 GET /login 中将其解码回字节。
让我们将其添加为依赖项:
#! Cargo.toml
[dependencies]
hex = "0.4"
现在我们可以在 QueryParams 本身上定义一个 verify 方法: 如果消息验证码符合我们的预期,它将返回错误字符串,否则返回错误。
//! src/routes/login/get.rs
use hmac::{Hmac, Mac};
use secrecy::ExposeSecret;
// [...]
impl QueryParams {
fn verify(self, secret: &HmacSecret) -> Result<String, anyhow::Error> {
let tag = hex::decode(self.tag)?;
let query_string = format!("error={}", urlencoding::Encoded::new(&self.error));
let mut mac =
Hmac::<sha2::Sha256>::new_from_slice(secret.0.expose_secret().as_bytes()).unwrap();
mac.update(query_string.as_bytes());
mac.verify_slice(&tag)?;
Ok(self.error)
}
}
现在我们需要修改请求处理程序来调用它,这就引出了一个问题:如果验证失败,我们该怎么做?
一种方法是返回 400 错误码,使整个请求失败。或者,我们可以将验证失败记录为警告,并在渲染 HTML 时跳过错误消息。
我们选择后者——用户被一些不可靠的查询参数重定向后,会看到我们的登录页面,这是一个可以接受的场景。
//! src/routes/login/get.rs
// [...]
pub async fn login_form(
query: Option<web::Query<QueryParams>>,
secret: web::Data<HmacSecret>,
) -> HttpResponse {
let error_html = match query {
None => "".into(),
Some(query) => match query.0.verify(&secret) {
Ok(error) => format!("<p><i>{}</i><p>", htmlescape::encode_minimal(&error)),
Err(e) => {
tracing::warn!(
error.message = %e,
error.cause_chain = ?e,
"Failed to verify query parameters using the HMAC tag"
);
"".into()
}
},
};
// [...]
}
您可以再次尝试加载我们的诈骗网址:
http://localhost:8000/login?error=Your%20account%20has%20been%20locked%2C%20please%20submit%20your%20details%20%3Ca%20href%3D%22https%3A%2F%2Fzero2prod.com%22%3Ehere%3C%2Fa%3E%20to%20resolve%20the%20issue.
浏览器不应该呈现任何错误消息!
错误消息必须是短暂的
从实现角度来看,我们很满意:错误信息按预期呈现,而且由于 HMAC 标签的存在,没有人能够篡改我们的消息。我们应该部署它吗?
我们选择使用查询参数来传递错误消息,因为查询参数是 URL 的一部分——在失败时重定向回登录表单时,很容易将它们传递到 Location 标头的值中。这既是它们的优点,也是它们的缺点: URL 存储在浏览器历史记录中,而浏览器历史记录会在您在地址栏中输入 URL 时提供自动完成建议。
您可以自己尝试一下:尝试在地址栏中输入 localhost:8000, 会得到什么建议?
由于我们目前为止进行的所有实验,大多数 URL 都会包含错误查询参数。
如果您选择一个带有有效标签的 URL,登录表单就会显示身份验证失败的错误消息……
即使距离您上次登录尝试已经过去了一段时间。这是
我们不希望看到的。
我们希望错误消息是短暂的。
它会在登录尝试失败后立即显示,但不会存储在您的浏览器历史记录中。唯一 再次触发错误消息的方法应该是……再次登录失败。
我们确定查询参数不符合我们的要求。我们还有其他选择吗?
是的,Cookie!
这是一个很棒的休息时刻,这是一个漫长的篇章!
如果您想检查您的实现,请查看 GitHub 上的项目快照
什么是 Cookie
MDN Web Docs 将 HTTP cookie 定义为
[...] 服务器向用户网络浏览器发送的一小段数据。浏览器可能会存储 Cookie, 并在后续请求中将其发送回同一服务器。
我们可以使用 Cookie 来实现之前尝试过的查询参数策略:
- 用户输入无效凭证并提交表单
POST /login设置包含错误消息的 Cookie,并将用户重定向回GET /login- 浏览器调用
GET /login,并传入当前为用户设置的 Cookie 值 GET /login的请求处理程序检查 Cookie,以确定是否有需要渲染的错误消息GET /login将 HTML 表单返回给调用者,并从 Cookie 中删除错误消息。
URL 不会被触及——所有与错误相关的信息都通过侧信道(Cookie)进行交换, 而这些侧信道对浏览器历史记录不可见。算法的最后一步确保了错误消息确实是短暂的——在渲染错误消息时,Cookie 会被“消耗”。如果页面重新加载,错误消息将不会再次显示。
我们刚才描述的一次性通知技术被称为闪现消息。
登录失败的集成测试
到目前为止,我们已经进行了相当自由的实验——我们编写了一些代码,启动了应用程序,并对其进行了各种尝试。
我们现在正接近设计的最终迭代,如果能使用一些黑盒测试来捕捉所需的行为,那就太好了。
就像我们迄今为止对项目支持的所有用户流程所做的那样。
编写测试也有助于我们熟悉 Cookie 及其行为。
我们想验证登录失败时会发生什么,这是我们之前几个章节一直在讨论的主题。
现在,让我们先在测试套件中添加一个新的登录模块:
//! tests/main.rs
// [...]
mod login;
//! tests/api/login.rs
// Empty for now
我们需要发送一个 POST /login 请求——让我们为 TestApp (用于在测试中与我们的应用程序交互的 HTTP 客户端) 添加一个帮助方法:
//! tests/api/helpers.rs
// [...]
impl TestApp {
pub async fn post_login<Body>(&self, body: &Body) -> reqwest::Response
where
Body: serde::Serialize,
{
reqwest::Client::new()
.post(format!("{}/login", &self.address))
// This `reqwest` method makes sure that the body is URL-encoded
// and the `Content-Type` header is set accordingly
.form(body)
.send()
.await
.expect("Failed to execute request.")
}
// [...]
}
现在我们可以开始勾勒测试用例了。
在处理 Cookie 之前,我们先来一个简单的断言: 它返回一个重定向, 状态码为 303。
//! tests/api/login.rs
use crate::helpers::spawn_app;
#[tokio::test]
async fn an_error_flash_message_is_set_on_failure() {
// Arrange
let app = spawn_app().await;
// Act
let login_body = serde_json::json!({
"username": "random-username",
"password": "random-password"
});
let response = app.post_login(&login_body).await;
// Assert
assert_eq!(response.status().as_u16(), 303);
}
测试失败了!
---- login::an_error_flash_message_is_set_on_failure stdout ----
thread 'login::an_error_flash_message_is_set_on_failure' panicked at tests/api/login.rs:16:5:
assertion `left == right` failed
left: 200
right: 303
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
无论成功还是失败,我们的端点都返回了 303 错误! 这是怎么回事?
答案可以在 reqwest 的文档中找到:
默认情况下,客户端会自动处理 HTTP 重定向,重定向链的最大跳数为 10。要自定义此行 为,可以将
redirect::Policy与ClientBuilder结合使用。
reqwest::Client 看到 303 状态码后,会自动继续调用 GET /login, 即 Location 标头中指定的路径,并返回 200——也就是我们在断言恐慌消息中看到的状态码。
为了测试目的,我们不希望 reqwest::Client 遵循重定向——让我们按照其文档中提供的指导来自定义HTTP 客户端的行为:
//! tests/api/helpers.rs
// [...]
impl TestApp {
pub async fn post_login<Body>(&self, body: &Body) -> reqwest::Response
where
Body: serde::Serialize,
{
reqwest::Client::builder()
.redirect(reqwest::redirect::Policy::none())
.build()
.unwrap()
// [...]
}
// [...]
}
测试现在应该可以通过了。
我们可以更进一步——检查 Location 标头的值。
//! tests/api/helpers.rs
// [...]
// Little helper function - we will be doing this check serveral times throughout
// this chapter and the next one.
pub fn assert_is_redirect_to(response: &reqwest::Response, location: &str) {
assert_eq!(response.status().as_u16(), 303);
assert_eq!(response.headers().get("Location").unwrap(), location);
}
//! tests/api/login.rs
use crate::helpers::assert_is_redirect_to;
// [...]
#[tokio::test]
async fn an_error_flash_message_is_set_on_failure() {
// [...]
// Assert
assert_is_redirect_to(&response, "/login");
}
您应该会看到另一个失败:
assertion `left == right` failed
left: "/login?error=Authentication%20failed&tag=bebe215d4cc4e2617d18153cc1dd6215e94cd6e616b972
6dd6c4cf9b3284ff72"
right: "/login"
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
端点仍在使用查询参数传递错误消息。让我们从请求处理程序中移除该功能:
//! src/routes/login/post.rs
// A few imports are now unused and can be removed.
// [...]
pub async fn login(
form: web::Form<FormData>,
pool: web::Data<PgPool>,
// We no longer need `HmacSecret`!
) -> Result<HttpResponse, InternalError<LoginError>> {
// [...]
match validate_credentials(credentials, &pool).await {
Ok(/* */) => { /* */ }
Err(e) => {
let e = match e {
AuthError::InvalidCredentials(_) => LoginError::AuthError(e.into()),
AuthError::UnexpectedError(_) => LoginError::UnexpectedError(e.into()),
};
let response = HttpResponse::SeeOther()
.insert_header((LOCATION, "/login"))
.finish();
Err(InternalError::from_response(e, response))
}
}
}
我知道,感觉像是在倒退——你需要一点耐心!
测试应该会通过。现在我们可以开始查看 Cookie 了,这就引出了一个问题——“设置 Cookie”到底是什么意思?
Cookie 是通过在响应中附加一个特殊的 HTTP 标头来设置的——Set-Cookie。
其最简单的形式如下:
Set-Cookie: <cookie-name>=<cookie-value>
Set-Cookie 可以多次指定——每个要设置的 Cookie 都需要指定一次。
reqwest 提供了 get_all 方法来处理多值标头:
//! tests/api/login.rs
// [...]
use reqwest::header::HeaderValue;
use std::collections::HashSet;
async fn an_error_flash_message_is_set_on_failure() {
// [...]
let response = app.post_login(&login_body).await;
let cookies: HashSet<_> = response
.headers()
.get_all("Set-Cookie")
.into_iter()
.collect();
// Assert
// [...]
assert!(cookies.contains(&HeaderValue::from_str("_flash=Authentication failed").unwrap()));
}
说实话, Cookie 如此普遍,值得专门创建一个 API, 这样我们就可以省去处理原始标头的麻烦。
reqwest 将此功能锁定在 cookies 功能标志后面 - 让我们启用它:
#! Cargo.toml
# [...]
# Using multi-line format for brevity
[dependencies.reqwest]
version = "[...]"
default-features = false
features = ["json", "rustls-tls", "cookies"]
//! tests/api/login.rs
// [...]
use reqwest::header::HeaderValue;
use std::collections::HashSet;
#[tokio::test]
async fn an_error_flash_message_is_set_on_failure() {
// Arrange
let app = spawn_app().await;
// Act
let login_body = serde_json::json!({
"username": "random-username",
"password": "random-password"
});
let response = app.post_login(&login_body).await;
// Assert
let flash_cookie = response.cookies().find(|c| c.name() == "_flash").unwrap();
assert_eq!(flash_cookie.value(), "Authentication failed");
assert_is_redirect_to(&response, "/login");
}
如您所见,cookie API 明显更加符合人体工程学。尽管如此,至少一次直接接触它抽象出来的东西也是有价值的。
测试应该会像预期的那样失败。
如何在 actix-web 中设置 Cookie
如何在 actix-web 中为传出的响应设置 Cookie?
我们可以直接使用标头:
//! src/routes/login/post.rs
// [...]
pub async fn login(
// [...]
) -> Result<HttpResponse, InternalError<LoginError>> {
// [...]
match validate_credentials(credentials, &pool).await {
Ok(/* */) => {/* */}
Err(e) => {
// [...]
let response = HttpResponse::SeeOther()
.insert_header((LOCATION, "/login"))
.insert_header(("Set-Cookie", format!("_flash={e}")))
.finish();
Err(InternalError::from_response(e, response))
}
}
}
这项更改应该足以让测试通过。
与 reqwest 一样, actix-web 也提供了专用的 Cookie API。 Cookie::new 接受两个参数:
Cookie 的名称和值。让我们使用它:
//! src/routes/login/post.rs
use actix_web::cookie::Cookie;
// [...]
pub async fn login(
// [...]
) -> Result<HttpResponse, InternalError<LoginError>> {
// [...]
match validate_credentials(credentials, &pool).await {
Ok(user_id) => {
// [...]
}
Err(e) => {
// [...]
let response = HttpResponse::SeeOther()
.insert_header((LOCATION, "/login"))
.cookie(Cookie::new("_flash", e.to_string()))
.finish();
// [...]
}
}
}
测试应该保持通过。
登录失败的集成测试 - 第 2 部分
现在让我们关注故事的另一面—— GET /login 。我们想要验证 _flash cookie 中传递的错误消息是否在重定向后真正呈现在用户看到的登录表单上方。
首先, 让我们在 TestApp 上添加一个 get_login_html 辅助方法:
impl TestApp {
// Our tests will only look at the HTML page, therefore
// we do not expose the underlying reqwest::Response
pub async fn get_login_html(&self) -> String {
reqwest::Client::new()
.get(format!("{}/login", self.address))
.send()
.await
.expect("Failed to execute request.")
.text()
.await
.unwrap()
}
}
//! tests/api/login.rs
// [...]
async fn an_error_flash_message_is_set_on_failure() {
// [...]
// Act - Part 2
let html_page = app.get_login_html().await;
assert!(html_page.contains(r#"<p><i>Authentication failed</i></p>"#))
}
测试应该会失败。
目前,我们无法让它通过:我们在向 GET /login 发送请求时,并没有传播 POST /login 设置的 Cookie——浏览器在正常情况下应该会完成这项任务。
那么 reqwest 能解决这个问题吗?
默认情况下,它不支持 cookie 传播 - 但可以配置!
我们只需将 true 传递给 reqwest::ClientBuilder::cookie_store。
不过需要注意的是 - 如果我们希望 cookie 传播功能正常工作,则必须对所有发送到 API 的请求使用相同的 reqwest::Client 实例。这需要在 TestApp 中进行一些重构 - 我们目前正在每个辅助方法中创建一个新的 reqwest::Client 实例。让我们修改一下 TestApp::spawn_app, 使其创建并存储一个 reqwest::Client 实例, 并在其所有辅助方法中使用它。
//! tests/api/helpers.rs
// [...]
pub struct TestApp {
// [...]
// New field!
pub api_client: reqwest::Client,
}
pub async fn spawn_app() -> TestApp {
// [...]
let client = reqwest::Client::builder()
.redirect(reqwest::redirect::Policy::none())
.cookie_store(true)
.build()
.unwrap();
let test_app = TestApp {
// [...]
api_client: client,
};
// [...]
}
impl TestApp {
pub async fn get_login_html(&self) -> String {
self.api_client
.get(/* */)
// [..]
}
pub async fn post_login<Body>(&self, body: &Body) -> reqwest::Response
where
Body: serde::Serialize,
{
self.api_client
.post(/* */)
// [...]
}
pub async fn post_subscriptions(&self, body: String) -> reqwest::Response {
self.api_client
.post(/* */)
// [...]
}
// [...]
pub async fn post_newsletters(&self, body: serde_json::Value) -> reqwest::Response {
self.api_client
.post(/* */)
// [...]
}
}
Cookie 传播现在应该可以按预期工作。
如何在 actix-web 中读取 Cookie
现在是时候再次查看我们的 GET /login 请求处理程序了
//! src/routes/login/get.rs
use actix_web::{HttpResponse, http::header::ContentType, web};
use hmac::{Hmac, Mac};
use secrecy::ExposeSecret;
use crate::startup::HmacSecret;
#[derive(serde::Deserialize)]
pub struct QueryParams {
error: String,
tag: String,
}
impl QueryParams {
fn verify(self, secret: &HmacSecret) -> Result<String, anyhow::Error> {
// [...]
}
}
pub async fn login_form(
query: Option<web::Query<QueryParams>>,
secret: web::Data<HmacSecret>,
) -> HttpResponse {
let error_html = match query {
None => "".into(),
Some(query) => match query.0.verify(&secret) {
Ok(error) => format!("<p><i>{}</i><p>", htmlescape::encode_minimal(&error)),
Err(e) => {
tracing::warn!(
error.message = %e,
error.cause_chain = ?e,
"Failed to verify query parameters using the HMAC tag"
);
"".into()
}
},
};
HttpResponse::Ok()
.content_type(ContentType::html())
.body(format!(/* HTML */))
}
让我们首先删除与查询参数及其(加密)验证相关的所有代码:
//! src/routes/login/get.rs
use actix_web::http::header::ContentType;
use actix_web::HttpResponse;
pub async fn login_form() -> HttpResponse {
let error_html: String = todo!();
HttpResponse::Ok()
.content_type(ContentType::html())
.body(format!(
r#"<!DOCTYPE html>
<html lang="en">
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<title>Login</title>
</head>
<body>
{error_html}
<form action="/login" method="post">
<label>Username
<input
type="text"
placeholder="Enter Username"
name="username"
>
</label>
<label>Password
<input
type="password"
placeholder="Enter Password"
name="password"
>
</label>
<button type="submit">Login</button>
</form>
</body>
</html>
"#
))
}
回到基础。让我们抓住这个机会,移除我们在 HMAC 探索过程中添加的依赖项——sha2、hmac 和 hex。
为了访问传入请求的 cookie, 我们需要获取 HttpRequest 本身。让我们
将它添加为 login_form 的参数:
//! src/routes/login/get.rs
// [...]
pub async fn login_form(request: HttpRequest) -> HttpResponse {
// [...]
}
然后我们可以使用 HttpRequest::cookie 来检索给定名称的 cookie:
//! src/routes/login/get.rs
// [...]
pub async fn login_form(request: HttpRequest) -> HttpResponse {
let error_html: String = match request.cookie("_flash") {
None => "".into(),
Some(cookie) => {
format!("<p><i>{}</i></p>", cookie.value())
}
};
// [...]
}
现在我们的集成测试应该可以通过了!
怎么在 acitx-web 中删除 Cookie
如果在登录失败后刷新页面会发生什么?
错误信息仍然存在!
如果您打开新标签页并直接导航到 localhost:8000/login,也会发生同样的事情——登录表单顶部会显示“身份验证失败”信息。
这与我们之前所说的错误信息应该是短暂的截然不同。
该如何解决这个问题? 没有 Unset-cookie 标头——如何从用户的浏览器中删除 _flash cookie?
让我们深入探讨一下 Cookie 的生命周期。
说到持久性,Cookie 分为两种类型:会话 Cookie 和持久 Cookie。
会话 Cookie 存储在内存中——会话结束时(即浏览器关闭时)会被删除。而持久 Cookie 则保存在磁盘上,即使您重新打开浏览器,它们仍然会存在。
一个普通的 Set-Cookie 标头会创建一个会话 Cookie。要设置持久性 Cookie,您必须使用 Cookie 属性指定过期策略 - Max-Age 或 Expires。
Max-Age 表示 Cookie 过期前的剩余秒数 - 例如: Set-Cookie: _flash=omg; Max-Age=5 会创建一个持久性的 _flash Cookie,其有效期为接下来的 5 秒。
Expires 则需要一个日期 - 例如: Set-Cookie: _flash=omg; Expires=Thu, 31 Dec 2022 23:59:59 GMT; 会创建一个持久性的 Cookie,其有效期至 2022 年底。
将 Max-Age 设置为 0 会指示浏览器立即使 Cookie 过期 - 即取消设置, 这正是我们想要的!有点 hack 吗? 是的, 但这就是它。
让我们开始实现吧。我们可以先修改集成测试来应对这种情况——如果我们在第一次重定向后重新加载登录页面,则不应该显示错误消息:
//! tests/api/login.rs
// [...]
async fn an_error_flash_message_is_set_on_failure() {
// Arrange
// [...]
// Act - Part 1 - Try to login
// [...]
// Act - Part 2 - Follow the redirect
// [...]
// Act - Part 3 - Reload the login page
let html_page = app.get_login_html().await;
assert!(!html_page.contains(r"<p><i>Authentication failed</i></p>"))
}
cargo test 应该会报告失败。现在我们需要修改请求处理程序——我们必须在响应中设置
_flash cookie, 并将 Max-Age 设置为 0, 以删除存储在用户浏览器中的 Flash 消息。
//! src/routes/login/get.rs
use actix_web::{
HttpRequest, HttpResponse,
cookie::{Cookie, time::Duration},
http::header::ContentType,
};
pub async fn login_form(request: HttpRequest) -> HttpResponse {
// [...]
HttpResponse::Ok()
.content_type(ContentType::html())
.cookie(Cookie::build("_flash", "").max_age(Duration::ZERO).finish())
.body(/* [...] */)
}
测试现在应该可以通过了!
我们可以重构处理程序,使用 add_removal_cookie 方法,让我们的意图更清晰:
//! src/routes/login/get.rs
use actix_web::cookie::{Cookie, time::Duration};
// [...]
pub async fn login_form(request: HttpRequest) -> HttpResponse {
// [...]
let mut response = HttpResponse::Ok()
.content_type(ContentType::html())
.body(/* [...] */);
response
.add_removal_cookie(&Cookie::new("_flash", ""))
.unwrap();
response
}
在底层,它执行完全相同的操作,但不需要读者拼凑将 Max-Age 设置为零的含义。
Cookie 安全
我们在使用 Cookie 时面临哪些安全挑战?
使用 Cookie 仍然可能发起 XSS 攻击,但与查询参数相比,它需要更多努力——您无法创建指向我们网站的链接来设置或操纵 Cookie。然而,粗暴地使用 Cookie 可能会让我们暴露给不法分子。
哪些类型的攻击可以针对 Cookie 发起?
广义上讲,我们希望防止攻击者篡改我们的 Cookie(即完整性)或嗅探其内容(即机密性)。
首先,通过不安全的连接(即 HTTP 而不是 HTTPS)传输 Cookie 会让我们面临中间人攻击——浏览器发送到服务器的请求可能会被拦截、读取,其内容也可能被任意修改。
第一道防线是我们的 API——它应该拒绝通过未加密通道发送的请求。我们可以通过将新创建的 Cookie 标记为“安全”来获得额外的防御层: 这会指示浏览器仅将 Cookie 附加到通过安全连接传输的请求中。
对我们 Cookie 的机密性和完整性的第二大威胁是 JavaScript:运行在客户端的脚本可以与 Cookie 存储交互,读取/修改现有 Cookie 或设置新的 Cookie。
根据经验,最低权限策略是一个不错的默认策略:除非有令人信服的理由,否则 Cookie 不应该对脚本可见。
我们可以将新创建的 Cookie 标记为“仅 HTTP”策略,以便将它们隐藏在客户端代码中——浏览器会像往常一样存储它们并将其附加到发出的请求中,但脚本将无法看到它们。
“仅 HTTP”策略是一个不错的默认策略,但它并非万能的——JavaScript 代码可能无法访问我们的“仅 HTTP”策略 Cookie,但有一些方法可以覆盖它们, 并诱使后端执行一些意外或不必要的操作。
最后但同样重要的是,用户也可能构成威胁!他们可以使用浏览器提供的开发者工具随意修改其 Cookie 存储的内容。虽然这在查看 Flash 消息时可能不成问题,但处理其他类型的 Cookie(例如,我们稍后会讨论的身份验证会话)时,这绝对是一个问题。
我们应该建立多层防御。
我们已经知道一种无论前端通道发生什么都能确保完整性的方法,不是吗?
消息认证码 (MAC),我们用来保护查询参数的那些!
带有 HMAC 标签的 Cookie 值通常被称为签名 Cookie。通过在后端验证标签, 我们可以确信签名 Cookie 的值没有被篡改,就像我们对查询参数所做的那样。
actix-web-flash-messages
我们可以使用 actix-web 提供的 cookie API 来强化基于 cookie 的 Flash 消息实现——有些功能很简单(例如 Secure、Http-Only),有些则需要一些额外的工作(例如 HMAC),但只要我们付出一些努力,这些功能都是可以实现的。
在讨论查询参数时,我们已经深入探讨了 HMAC 标签,因此, 从头开始实现签名 cookie 并没有什么教育意义。我们将使用 actix-web 社区生态系统中的一个 crate: actix-web-flash-messages。
actix-web-flash-messages 提供了一个用于在 actix-web 中使用 flash 消息的框架,该框架与 Django 的消息框架紧密相关。
让我们将其添加为依赖项:
#! Cargo.toml
# [...]
[dependencies]
actix-web-flash-messages = { version = "0.5.0", features = ["cookies"] }
# [...]
要开始使用 flash 消息,我们需要在 actix_web 的 App 中注册 FlashMessagesFramework 作为中间件:
//! src/startup.rs
// [...]
pub fn run(/* */) -> Result<Server, std::io::Error> {
// [..]
let message_framework = FlashMessagesFramework::builder(todo!()).build();
let server = HttpServer::new(move || {
App::new()
.wrap(message_framework.clone())
.wrap(TracingLogger::default())
// [...]
})
.// [...]
}
FlashMessagesFramework::builder 需要一个存储后端作为参数 - flash 消息应该存储在哪里?
并从哪里检索?
actix-web-flash-messages 提供了一个基于 Cookie 的实现, CookieMessageStore。
//! src/startup.rs
// [...]
use actix_web_flash_messages::storage::CookieMessageStore;
pub fn run(/* */) -> Result<Server, std::io::Error> {
// [...]
let message_store = CookieMessageStore::builder(todo!()).build();
let message_framework = FlashMessagesFramework::builder(message_store).build();
// [...]
}
CookieMessageStore 强制要求用于存储的 Cookie 必须经过签名,因此我们必须向其构建器提供
密钥。我们可以复用在处理 HMAC 标签时引入的 hmac_secret 来作为查询参数:
//! src/startup.rs
// [...]
use secrecy::ExposeSecret;
use actix_web::cookie::Key;
// [...]
pub fn run(/* */) -> Result<Server, std::io::Error> {
// [...]
let message_store =
CookieMessageStore::builder(Key::from(hmac_secret.expose_secret().as_bytes())).build();
// [...]
}
现在我们可以开始发送 FlashMessage 了。
每个 FlashMessage 都有一个级别和一个内容字符串。消息级别可用于过滤
和渲染 - 例如:
- 在生产环境中仅显示信息级别或更高级别的 Flash 消息,同时保留 调试级别的消息以供本地开发使用;
- 在 UI 中使用不同的颜色显示消息(例如,红色表示错误,橙色表示警告, 等等)。
我们可以重新设计 POST /login 来发送 FlashMessage:
//! src/routes/login/post.rs
// [...]
pub async fn login(/* */) -> Result<HttpResponse, InternalError<LoginError>> {
// [...]
match validate_credentials(/* */).await {
Ok(/* */) => {/* */}
Err(e) => {
let e = /* */;
FlashMessage::error(e.to_string()).send();
let response = HttpResponse::SeeOther()
// No cookies here now!
.insert_header((LOCATION, "/login"))
.finish();
Err(InternalError::from_response(e, response))
}
}
}
FlashMessagesFramework 中间件负责处理所有繁重的后台工作——创建 Cookie、签名、设置正确的属性等等。
我们还可以将多条 Flash 消息附加到单个响应中——框架负责如何组合它们并在存储层中呈现。
接收端如何工作? 如何在 GET /login 中读取传入的 Flash 消息?
我们可以使用 IncomingFlashMessages 提取器:
//! src/routes/login/get.rs
// [...]
use actix_web_flash_messages::{IncomingFlashMessages, Level};
use std::fmt::Write;
// No need to access the raw request anymore!
pub async fn login_form(flash_messages: IncomingFlashMessages) -> HttpResponse {
let mut error_html = String::new();
for m in flash_messages.iter().filter(|m| m.level() == Level::Error) {
writeln!(error_html, "<p><i>{}</i></p>", m.content()).unwrap();
}
HttpResponse::Ok()
// No more removal cookie!
.content_type(ContentType::html())
.body(format!(/* */))
}
代码需要稍微修改一下,以适应收到多条 Flash 消息的情况,但总体来说效果差不多。特别是,我们不再需要处理 Cookie API,也不需要检索传入的 Flash 消息,也不需要确保读取后删除它们——
actix-web-flash-messages 会处理这些事情。Cookie 签名的有效性也会在后台验证,
在调用请求处理程序之前。
我们的测试怎么样?
它们失败了:
thread 'login::an_error_flash_message_is_set_on_failure' panicked at tests/api/login.rs:18:5:
assertion `left == right` failed
left: "Ik4JlkXTiTlc507ERzy2Ob4Xc4qXAPzJ7MiX6EB04c4%3D%5B%7B%22content%22%3A%22Authentication%20fa
iled%22,%22level%22%3A%22Error%22%7D%5D"
right: "Authentication failed"
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
我们的断言与实现细节过于接近了——我们只需要验证渲染的 HTML 是否包含(或不包含)预期的错误消息。让我们修改一下测试代码:
//! tests/api/login.rs
// [...]
#[tokio::test]
async fn an_error_flash_message_is_set_on_failure() {
// Arrange
let app = spawn_app().await;
// Act - Part 1 - Try to login
let login_body = serde_json::json!({
"username": "random-username",
"password": "random-password"
});
let response = app.post_login(&login_body).await;
// Assert
// No longer asserting facts related to cookies
assert_is_redirect_to(&response, "/login");
// Act - Part 2 - Follow the redirect
let html_page = app.get_login_html().await;
assert!(html_page.contains(r#"<p><i>Authentication failed</i></p>"#));
// Act - Part 3 - Reload the login page
let html_page = app.get_login_html().await;
assert!(!html_page.contains(r"<p><i>Authentication failed</i></p>"))
}
现在测试应该通过了
会话
我们花了一段时间思考登录失败后应该如何处理。现在该交换一下了: 登录成功后,我们期望看到什么?
身份验证旨在限制对需要更高权限的功能的访问——在我们的例子中, 就是向整个邮件列表发送新一期新闻通讯的功能。我们想要构建一个管理面板——我们将有一个 /admin/dashboard 页面,仅限登录用户访问,以便访问所有管理功能。
我们将分阶段实现。作为第一个里程碑,我们希望:
- 登录成功后重定向到
/admin/dashboard, 并显示欢迎 <username>!问候语 - 如果用户尝试直接导航到
/admin/dashboard并且他们尚未登录,他们将被重定向到登录表单。
此计划需要会话。
基于会话的鉴权
基于会话的身份验证是一种避免在每个页面上都要求用户输入密码的策略。
用户只需通过登录表单进行一次身份验证:如果成功,服务器将生成一个一次性密钥——经过身份验证的会话令牌。
后端 API 将接受会话令牌而不是用户名/密码组合,并 授予对受限功能的访问权限。每次请求都必须提供会话令牌—— 这就是会话令牌以 Cookie 形式存储的原因。浏览器将确保将 Cookie 附加到所有 API 的传出请求中。
从安全角度来看,有效的会话令牌与相应的身份验证密钥(例如用户名/密码组合、生物识别或物理第二因素)一样强大。
我们必须格外小心,避免将会话令牌暴露给攻击者。
OWASP 提供了有关如何保护会话安全的详尽指南——我们将在下一节中实施他们的大部分建议。
会话存储
让我们开始思考具体实现吧!
基于我们目前讨论的内容,我们需要 API 在登录成功后生成一个会话令牌。
该令牌值必须是不可预测的——我们不希望攻击者能够生成或猜测一个有效的会话令牌。OWASP 建议使用加密安全的伪随机数生成器 (CSPRNG)。
仅仅随机性是不够的——我们还需要唯一性。如果我们将两个用户关联到同一个会话令牌,就会遇到麻烦:
- 我们可能会授予其中一个用户高于其应得权限的权限
- 我们可能会泄露个人或机密信息,例如姓名、电子邮件、过往活动等。
我们需要一个会话存储——服务器必须记住它生成的令牌,以便授权已登录用户的未来请求。我们还希望将信息关联到每个活动会话——这被称为会话状态。
选择会话存储
在会话的生命周期中,我们需要执行以下操作:
- 创建会话,当用户登录时
- 检索会话,使用从传入请求中附加的 Cookie 中提取的会话令牌
- 更新会话,当登录用户执行某些操作导致其会话状态发生变化时
- 删除会话,当用户注销时
这些操作通常称为 CRUD(创建、删除、读取、更新)。
我们还需要某种形式的过期机制——会话应该是短暂的。如果没有清理机制, 我们最终会为过期/陈旧的会话占用比活动会话更多的空间。
Postgres
Postgres 是否是一个可行的会话存储方案?
我们可以创建一个新的会话表,以令牌作为主索引——这是一种确保令牌唯一性的简单方法。
对于会话状态,我们有几种选择:
- “经典”关系建模,使用规范化模式(即我们存储应用程序状态的方式)
- 单个状态列,使用 jsonb 数据类型,保存键值对集合。
遗憾的是,Postgres 没有内置的行过期机制。我们必须
添加一个 expires_at 列,并定期触发清理作业来清除过期会话——
这有点繁琐。
Redis
Redis 是另一种流行的会话存储方案。
Redis 是一个内存数据库——它使用内存而非磁盘进行存储,牺牲了持久性来换取速度。
它非常适合存储那些可以建模为键值对集合的数据。
它还原生支持过期时间——我们可以为所有值附加一个生存时间,Redis 会负责处理这些值。
它如何应用于会话?
我们的应用程序从不批量操作会话——我们每次只处理一个会话, 并使用其令牌进行标识。因此,我们可以使用会话令牌作为键,而值则是会话状态的 JSON 表示形式——应用程序负责序列化/反序列化。
会话的生命周期很短——无需担心使用内存而不是磁盘进行持久化, 速度提升是一个不错的附加效果!
正如您可能已经猜到的那样,我们将使用 Redis 作为会话存储后端!
actix-session
actix-session 为 actix-web 应用程序提供会话管理。让我们将它添加到我们的依赖项中:
#! Cargo.toml
# [...]
[dependencies]
actix-session = "0.11.0"
# [...]
actix-session 中的键类型是 SessionMiddleware - 它负责加载会话数据、跟踪状态变化并在请求/响应生命周期结束时将其持久化。
要构建 SessionMiddleware 实例,我们需要提供一个存储后端和一个密钥来对会话 cookie 进行签名(或加密)。该方法与 actix-web-flash-messages 中的 FlashMessagesFramework 所使用的方法非常相似。
//! src/startup.rs
// [...]
use actix_session::SessionMiddleware;
pub fn run(
// [...]
hmac_secret: SecretString,
) -> Result<Server, std::io::Error> {
// [...]
let secret_key = Key::from(hmac_secret.expose_secret().as_bytes());
let message_store =
CookieMessageStore::builder(Key::from(hmac_secret.expose_secret().as_bytes())).build();
// [...]
let server = HttpServer::new(move || {
App::new()
.wrap(message_framework.clone())
.wrap(SessionMiddleware::new(todo!(), secret_key.clone()))
.wrap(TracingLogger::default())
// [...]
})
.listen(listener)?
.run();
Ok(server)
}
actix-session 在存储方面非常灵活——您可以通过实现 SessionStore trait 来提供自己的存储。它还提供了一些开箱即用的实现,隐藏在一系列功能标志后面——其中包括一个 Redis 后端。让我们启用它:
#! Cargo.toml
# [...]
[dependencies]
actix-session = { version = "0.11.0", features = ["redis-session-rustls"] }
现在我们可以访问 RedisSessionStore 了。要构建一个 RedisSessionStore, 我们需要传入一个 Redis 连接字符串作为输入——让我们将 redis_uri 添加到我们的配置结构体中:
//! src/configuration.rs
// [...]
pub struct Settings {
// [...]
pub redis_uri: SecretString,
}
// [...]
# configuration/base.yaml
# 6379 is Redis' default port
redis_uri: "redis://127.0.0.1:6379"
# [...]
让我们使用它来构建一个 RedisSessionStore 实例:
//! src/startup.rs
// [...]
impl Application {
// Async now! We also return anyhow::Error instead of std::io::Error
pub async fn build(configuration: Settings) -> Result<Self, anyhow::Error> {
// [...]
let server = run(
// [...]
configuration.redis_uri,
).await?;
Ok(Self { port, server })
}
// [...]
}
// Now it's asynchronous!
async fn run(
listener: TcpListener,
db_pool: PgPool,
email_client: EmailClient,
base_url: String,
hmac_secret: SecretString,
redis_uri: SecretString,
// Returning anyhow::Error instead of std::io::Error
) -> Result<Server, anyhow::Error> {
// [...]
let redis_store = RedisSessionStore::new(redis_uri.expose_secret()).await?;
let server = HttpServer::new(move || {
App::new()
.wrap(message_framework.clone())
.wrap(SessionMiddleware::new(
redis_store.clone(),
secret_key.clone(),
))
.wrap(TracingLogger::default())
// [...]
})
// [...]
}
//! src/main.rs
// [...]
#[tokio::main]
// anyhow::Result now instead of std::io::Error
async fn main() -> anyhow::Result<()> {
// [...]
}
是时候将正在运行的 Redis 实例添加到我们的设置中了。
我们开发设置中的 Redis
我们需要在 CI 管道中运行一个 Redis 容器,与 Postgres 容器一起运行——请查看书籍存储库中更新的 YAML。
我们还需要在开发机器上运行一个 Redis 容器来执行测试套件并启动应用程序。让我们添加一个脚本来启动它:
# scripts/init_redis.sh
#!/usr/bin/env bash
set -x
set -eo pipefail
# if a redis container is running, print instructions to kill it and exit
RUNNING_CONTAINER=$(docker ps --filter 'name=redis' --format '{{.ID}}')
if [[ -n $RUNNING_CONTAINER ]]; then
echo >&2 "there is a redis container already running, kill it with"
echo >&2 "
docker kill ${RUNNING_CONTAINER}"
exit 1
fi
# Launch Redis using Docker
docker run \
-p "6379:6379" \
-d \
--name "redis_$(date '+%s')" \
redis:8
>&2 echo "Redis is ready to go!"
该脚本需要标记为可执行,然后启动:
chmod +x ./scripts/init_redis.sh
./script/init_redis.sh
Digital Ocean 上的 Redis
Digital Ocean 不支持通过 spec.yaml 文件创建开发版 Redis 集群。您需要访问他们的仪表盘 - 在此处创建一个新的 Redis 集群。请务必选择您部署应用程序的数据中心。集群创建完成后, 您需要完成一个快速的“入门”流程来配置一些参数(可信源、驱逐策略等)。
在“入门”流程的最后,您将能够将连接字符串复制到新配置的 Redis 实例。连接字符串包含用户名和密码,因此我们必须将其视为机密信息。我们将使用环境变量值(在应用程序控制台的“设置”面板中设置 APP_REDIS_URI)将其值注入应用程序。
管理员仪表盘
我们的会话存储现已在所有我们关注的环境中启动并运行。现在是时候实际地 用它做点什么了!
让我们创建一个新页面(管理仪表板)的框架。
//! src/routes/admin.rs
mod dashboard;
pub use dashboard::admin_dashboard;
//! src/routes/admin.dashboard.rs
use actix_web::HttpResponse;
pub async fn admin_dashboard() -> HttpResponse {
HttpResponse::Ok().finish()
}
//! src/routes.rs
// [...]
mod admin;
pub use admin::*;
//! src/startup.rs
use crate::routes::admin_dashboard;
// [...]
async fn run(
// [...]
) -> Result<Server, anyhow::Error> {
// [...]
let server = HttpServer::new(move || {
App::new()
// [...]
.route("/admin/dashboard", web::get().to(admin_dashboard))
// [...]
})
// [...]
}
登录成功后跳转
让我们开始着手实现第一个里程碑:
登录成功后重定向到
/admin/dashboard并显示欢迎信息Welcome <username>!;
我们可以在集成测试中对需求进行编码:
//! tests/api/login.rs
// [...]
#[tokio::test]
async fn redirect_to_admin_dashboard_after_login_success() {
// Arrange
let app = spawn_app().await;
// Act - Part 1 - Login
let login_body = serde_json::json!({
"username": &app.test_user.username,
"password": &app.test_user.password,
});
let response = app.post_login(&login_body).await;
assert_is_redirect_to(&response, "/admin/dashboard");
// Act - Part 2 - Follow the redirect
let html_page = app.get_admin_dashboard().await;
assert!(html_page.contains(&format!("Welcome {}", app.test_user.username)));
}
//! tests/api/helpers.rs
// [...]
impl TestApp {
pub async fn get_admin_dashboard(&self) -> String {
self.api_client
.get(format!("{}/admin/dashboard", &self.address))
.send()
.await
.expect("Failed to execute requet.")
.text()
.await
.unwrap()
}
// [...]
}
这个测试将会失败:
thread 'login::redirect_to_admin_dashboard_after_login_success' panicked at tests/api/helpers.rs:24
2:5:
assertion `left == right` failed
left: "/"
right: "/admin/dashboard"
通过第一个断言很容易——我们只需要更改 POST /login 返回的响应中的 Location 标头:
//! src/routes/login/post.rs
// [...]
#[tracing::instrument(/* */)]
pub async fn login(/* */) -> Result</* */> {
// [...]
match validate_credentials(/* */).await {
Ok(/* */) => {
// [...]
Ok(HttpResponse::SeeOther()
.insert_header((LOCATION, "/admin/dashboard"))
.finish())
}
// [...]
}
}
现在测试会在第二个断言失败
thread 'login::redirect_to_admin_dashboard_after_login_success' panicked at tests/api/login.rs:43:5
:
assertion failed: html_page.contains(&format!("Welcome {}", app.test_user.username))
是时候让这些会话发挥作用了。
会话实现
我们需要在用户执行 POST /login 返回的重定向后,访问 GET /admin/dashboard 时识别用户身份——
这是会话的完美用例。
我们将用户标识符存储到 login 中的会话状态中,然后从 admin_dashboard 中的会话状态中检索它。
我们需要熟悉 Session, 它是 actix_session 中的第二个键类型。
SessionMiddleware 负责在传入请求中检查会话 cookie 的所有繁重工作——
如果找到,它会从所选的存储后端加载相应的会话状态。否则,
它会创建一个新的空会话状态。
然后,我们可以使用 Session 作为提取器,在请求处理程序中与该状态进行交互。
让我们在 POST /login 中看看它的实际作用:
//! src/routes/login/post.rs
use actix_session::Session;
// [...]
#[tracing::instrument(
skip(/* */, session),
// [...]
)]
pub async fn login(
// [...]
session: Session,
) -> Result<HttpResponse, InternalError<LoginError>> {
// [...]
match validate_credentials(credentials, &pool).await {
Ok(user_id) => {
tracing::Span::current().record("user_id", tracing::field::display(&user_id));
session.insert("user_id", user_id);
Ok(HttpResponse::SeeOther()
.insert_header((LOCATION, "/admin/dashboard"))
.finish())
}
Err(e) => {
// [...]
}
}
}
#! Cargo.toml
# [...]
[dependencies]
# We need to add the `serde` feature
uuid = { version = "...", features = ["v4", "serde"] }
您可以将 Session 视为 HashMap 上的句柄 - 您可以根据 String 键插入和检索值。
您传入的值必须是可序列化的 - actix-session 会在后台将它们转换为 JSON。
这就是为什么我们必须在 uuid 依赖项中添加 serde 功能。
序列化意味着失败的可能性 - 如果您运行 cargo check, 您会看到编译器
警告我们没有处理 session.insert 返回的结果。让我们来解决这个问题:
//! src/routes/login/post.rs
// [...]
#[tracing::instrument(/* */)]
pub async fn login(
// [...]
session: Session,
) -> Result<HttpResponse, InternalError<LoginError>> {
// [...]
match validate_credentials(credentials, &pool).await {
Ok(user_id) => {
tracing::Span::current().record("user_id", tracing::field::display(&user_id));
session
.insert("user_id", user_id)
.map_err(|e| login_redirect(LoginError::UnexpectedError(e.into())))?;
// [...]
}
Err(e) => {
let e = match e {
AuthError::InvalidCredentials(_) => LoginError::AuthError(e.into()),
AuthError::UnexpectedError(_) => LoginError::UnexpectedError(e.into()),
};
Err(login_redirect(e))
}
}
}
// Redirect to the login page with an error message.
fn login_redirect(e: LoginError) -> InternalError<LoginError> {
FlashMessage::error(e.to_string()).send();
let response = HttpResponse::SeeOther()
.insert_header((LOCATION, "/login"))
.finish();
InternalError::from_response(e, response)
}
如果出现问题,用户将被重定向回 /login 页面,并显示相应的 错误消息。
那么 Session::insert 究竟做了什么呢?
所有针对 Session 的操作都在内存中执行——它们不会影响存储后端看到的
会话状态。处理程序返回响应后, SessionMiddleware
将检查 Session 的内存状态——如果状态发生变化,它将调用 Redis 来更新(或创建)
状态。它还会负责在客户端设置会话 cookie(如果之前没有)。
它能正常工作吗? 让我们尝试在另一端获取 user_id!
//! src/routes/admin/dashboard.rs
use actix_session::Session;
use actix_web::HttpResponse;
use uuid::Uuid;
// Return an opaque 500 while preserving the error's root cause for logging.
fn e500<T>(e: T) -> actix_web::Error
where
T: std::fmt::Debug + std::fmt::Display + 'static,
{
actix_web::error::ErrorInternalServerError(e)
}
pub async fn admin_dashboard(session: Session) -> Result<HttpResponse, actix_web::Error> {
let _username = if let Some(user_id) = session.get::<Uuid>("user_id").map_err(e500)? {
todo!();
} else {
todo!();
};
Ok(HttpResponse::Ok().finish())
}
使用 Session::get 时,我们必须指定要将会话状态条目反序列化为哪种类型——
在本例中是 Uuid。反序列化可能会失败,因此我们必须处理错误情况。
现在我们有了 user_id, 我们可以使用它来获取用户名并返回我们之前讨论过的 "Welcome {username}!" 消息。
//! src/routes/admin/dashboard.rs
// [...]
use actix_session::Session;
use actix_web::{HttpResponse, http::header::ContentType, web};
use anyhow::Context;
use sqlx::PgPool;
use uuid::Uuid;
// Return an opaque 500 while preserving the error's root cause for logging.
fn e500<T>(e: T) -> actix_web::Error
where
T: std::fmt::Debug + std::fmt::Display + 'static,
{
actix_web::error::ErrorInternalServerError(e)
}
pub async fn admin_dashboard(
session: Session,
pool: web::Data<PgPool>,
) -> Result<HttpResponse, actix_web::Error> {
let username = if let Some(user_id) = session.get::<Uuid>("user_id").map_err(e500)? {
get_username(user_id, &pool).await.map_err(e500)?
} else {
todo!()
};
Ok(HttpResponse::Ok()
.content_type(ContentType::html())
.body(format!(
r#"<!DOCTYPE html>
<html lang="en">
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<title>Admin dashboard</title>
</head>
<body>
<p>Welcome {username}!</p>
</body>
</html>"#
)))
}
#[tracing::instrument(name = "Get username", skip(pool))]
async fn get_username(user_id: Uuid, pool: &PgPool) -> Result<String, anyhow::Error> {
let row = sqlx::query!(
r#"
SELECT username
FROM users
WHERE user_id = $1
"#,
user_id
)
.fetch_one(pool)
.await
.context("Failed to perform a query to retrieve a username.")?;
Ok(row.username)
}
我们的集成测试现在应该可以通过了! 不过,我们还没完成——目前,我们的登录流程可能容易受到 会话固定攻击。
会话的用途远不止身份验证——例如,在“访客”模式下购物时,用于跟踪已添加到购物车的商品。
这意味着用户可能关联到一个匿名会话,并在身份验证后关联到一个特权会话。攻击者可以利用这一点。 网站竭尽全力阻止恶意行为者嗅探会话令牌,这导致了 另一种攻击策略——在用户登录前向其浏览器植入一个已知的会话令牌, 等待身份验证完成,然后,砰,你就成功了!
我们可以采取一个简单的对策来阻止这种攻击——在用户登录时轮换会话令牌。
这是一种非常常见的做法,你会发现所有主流 Web 框架 (包括 actix-session) 的会话管理 API 都支持它,
通过 Session::renew 来实现。让我们将其添加到:
//! src/routes/login/post.rs
// [...]
#[tracing::instrument(/* */)]
pub async fn login(/* */) -> Result<HttpResponse, InternalError<LoginError>> {
// [...]
match validate_credentials(/* */).await {
Ok(user_id) => {
// [...]
session.renew();
session
.insert("user_id", user_id)
.map_err(|e| login_redirect(LoginError::UnexpectedError(e.into())))?;
// [...]
}
// [...]
}
}
现在我们可以安心了。
会话的类型接口
Session 功能强大,但就其本身而言,它作为构建应用程序状态处理的基础, 却不够稳定。我们使用基于字符串的 API 访问数据, 并注意在插入和检索两端使用相同的键和类型。
当状态非常简单时,它还能正常工作,但如果有多个路由访问相同的数据, 它很快就会变得一团糟——在需要改进架构时,如何确保更新了所有路由?
如何防止键值错误导致生产中断? 测试可以提供帮助,但我们可以使用类型系统彻底解决这个问题。我们将在 Session 之上构建一个强类型 API 来访问和修改状态, 从而在请求处理程序中不再使用字符串键和类型转换。
Session 是一个外部类型(在 actix-session 中定义),因此我们必须使用扩展特征
模式:
//! src/lib.rs
// [...]
pub mod session_state;
//! src/session_state.rs
use actix_session::Session;
use uuid::Uuid;
pub struct TypedSession(Session);
impl TypedSession {
const USER_ID_KEY: &'static str = "user_id";
pub fn renew(&self) {
self.0.renew();
}
pub fn insert_user_id(&self, user_id: Uuid) -> Result<(), actix_session::SessionInsertError> {
self.0.insert(Self::USER_ID_KEY, user_id)
}
pub fn get_user_id(&self) -> Result<Option<Uuid>, actix_session::SessionGetError> {
self.0.get(Self::USER_ID_KEY)
}
}
请求处理程序如何构建 TypedSession 实例?
我们可以提供一个以 Session 作为参数的构造函数。另一个选择是
将 TypedSession 本身变成一个 actix-web 提取器——让我们试试看!
//! src/session_state.rs
// [...]
use actix_session::SessionExt;
use actix_web::dev::Payload;
use actix_web::{FromRequest, HttpRequest};
use std::future::{Ready, ready};
impl FromRequest for TypedSession {
// This is a complicated way of saying
// "We return the same error returned by the
// implementation of `FromRequest` for `Session`"
type Error = <Session as FromRequest>::Error;
// Rust does not yet support the `async` syntax in traits.
//
// From request expects a `Future` as return type to allow for extractors
// that need to perform asynchronous operations (e.g. a HTTP call)
// We do not have a `Future`, because we don't perform any I/O,
// so we wrap `TypedSession` into `Ready` to convert it into a `Future` that
// resolves to the wrapped value the first time it's polled by the executor.
type Future = Ready<Result<TypedSession, Self::Error>>;
fn from_request(req: &HttpRequest, _payload: &mut Payload) -> Self::Future {
ready(Ok(TypedSession(req.get_session())))
}
}
它只有三行代码,但很可能会让你接触到一些新的 Rust 概念/结构。
花点时间逐行阅读,正确理解正在发生的事情——或者,如果你愿意, 也可以先理解要点,稍后再深入研究!
现在我们可以在请求处理程序中将 Session 替换为 TypedSession 了:
//! src/routes/login/post.rs
// You can now remove the `Session` import
use crate::session_state::TypedSession;
// [...]
pub async fn login(
// [...]
session: TypedSession,
) -> Result<HttpResponse, InternalError<LoginError>> {
// [...]
match validate_credentials(credentials, &pool).await {
Ok(user_id) => {
// [...]
session.renew();
session
.insert_user_id(user_id)
.map_err(|e| login_redirect(LoginError::UnexpectedError(e.into())))?;
// [...]
}
// [...]
}
}
//! src/routes/admin/dashboard.rs
// You can now remove the `Session` import
pub async fn admin_dashboard(
// [...]
// Changed from `Session` to `TypedSession`!
session: TypedSession,
) -> Result<HttpResponse, actix_web::Error> {
let username = if let Some(user_id) = session.get_user_id().map_err(e500)? {
// [...]
} else {
todo!()
};
// [...]
}
测试应该会保持通过。
拒绝未验证的用户
现在我们可以处理第二个里程碑:
如果用户尝试直接导航到 /admin/dashboard 但尚未登录,他们将被重定向到登录表单。
让我们像往常一样在集成测试中对需求进行编码:
//! tests/api/admin_dashboard.rss
use crate::helpers::{spawn_app, assert_is_redirect_to};
use crate::helpers::{assert_is_redirect_to, spawn_app};
#[tokio::test]
async fn you_must_be_logged_in_to_access_the_admin_dashboard() {
// Arrange
let app = spawn_app().await;
// Act
let response = app.get_admin_dashboard().await;
// Assert
assert_is_redirect_to(&response, "/login");
}
//! tests/api/main.rs
mod admin_dashboard;
//! tests/api/helpers.rs
// [...]
impl TestApp {
pub async fn get_admin_dashboard(&self) -> reqwest::Response {
self.api_client
.get(format!("{}/admin/dashboard", &self.address))
.send()
.await
.expect("Failed to execute requet.")
}
pub async fn get_admin_dashboard_html(&self) -> String {
self.get_admin_dashboard().await.text().await.unwrap()
}
}
测试应该会失败——处理程序会 panic。
我们可以通过实现 todo!() 来解决这个问题:
//! src/routes/admin/dashboard.rs
use actix_web::http::header::LOCATION;
// [...]
pub async fn admin_dashboard(
session: TypedSession,
pool: web::Data<PgPool>,
) -> Result<HttpResponse, actix_web::Error> {
let username = if let Some(user_id) = session.get_user_id().map_err(e500)? {
// [...]
} else {
return Ok(HttpResponse::SeeOther()
.insert_header((LOCATION, "/login"))
.finish());
};
// [...]
}
现在测试应该可以通过了。
种子用户
在我们的测试套件中,一切看起来都很棒。
我们还没有对最新的功能进行任何探索性测试——我们停止了在浏览器中的胡乱操作, 几乎是在开始研究快乐路径的同时。这并非 巧合——我们目前无法进行快乐路径测试!
数据库中没有用户,也没有管理员注册流程——我们隐含的期望是 应用程序所有者会以某种方式成为新闻通讯的首位管理员! 现在是时候实现这一点了。
我们将创建一个种子用户——即添加一个迁移文件,在应用程序首次部署时将用户创建到数据库中。
种子用户将拥有一个预先确定的用户名和密码;
然后他们将能够在首次登录后更改密码。
数据库迁移
让我们使用 sqlx 创建一个新的迁移
sqlx migrate add seed_user
我们需要在用户表中插入一行新数据。我们需要:
- 用户 ID (UUID)
- 用户名
- PHC 字符串
选择您喜欢的 UUID 生成器来获取有效的用户 ID。我们将使用 admin 作为用户名。
获取 PHC 字符串稍微麻烦一些——我们将使用 everythinghastostartsomewhere 作为密码,
但如何生成相应的 PHC 字符串呢?
我们可以利用我们在测试套件中编写的代码来“作弊”:
//! tests/api/helpers.rs
// [...]
impl TestUser {
pub fn generate() -> Self {
Self {
// [...]
// password: Uuid::new_v4().to_string(),
password: "everythinghastostartsomewhere".into(),
}
}
async fn store(&self, pool: &PgPool) {
// [...]
let password_hash = /* */;
dbg!(&password_hash);
// [...]
}
}
这只是一个临时的修改——之后只需运行 cargo test -- --nocapture 即可为我们的迁移脚本获取格式正确的 PHC 字符串。获取后请还原更改。
迁移脚本如下所示:
INSERT INTO users (user_id, username, password_hash)
VALUES (
'ddf8994f-d522-4659-8d02-c1d479057be6',
'admin',
'$argon2id$v=19$m=15000,t=2,p=1$fA5tDKcNuhzfD6UD1Hmlsw$TN5KrFnqlxJBY7LUFpsV9OZZ/u0wKklR/KrRrzIras0'
);
sqlx migrate run
运行迁移,然后使用 cargo run 启动你的应用程序 - 你最终应该能够成功登录!
如果一切正常, /admin/dashboard 上应该会出现一条 "Welcome admin" 的消息。
恭喜!
重置密码
让我们从另一个角度来审视当前的情况——我们刚刚为一个高权限用户配置了已知的用户名/密码组合。 这很危险。
我们需要赋予种子用户更改密码的权限。这将是管理面板上的第一个功能!
构建此功能不需要任何新概念——请利用本节作为机会, 复习并确保您已经牢牢掌握了我们目前为止所讲的所有内容!
表单框架
让我们先来搭建所需的框架。这是一个基于表单的流程, 就像登录流程一样——我们需要一个 GET 端点来返回 HTML 表单,以及一个 POST 端点来处理提交的信息:
//! src/routes/admin.rs
// [...]
mod password;
pub use password::*;
//! src/routes/admin/password.rs
mod get;
mod post;
pub use get::change_password_form;
pub use post::change_password;
//! src/routes/admin/password/get.rs
use actix_web::{HttpResponse, http::header::ContentType};
pub async fn change_password_form() -> Result<HttpResponse, actix_web::Error> {
Ok(HttpResponse::Ok().content_type(ContentType::html()).body(
r#"<!DOCTYPE html>
<html lang="en">
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<title>Change Password</title>
</head>
<body>
<form action="/admin/password" method="post">
<label>Current password
<input
type="password"
placeholder="Enter current password"
name="current_password"
>
</label>
<br>
<label>New password
<input
type="password"
placeholder="Enter new password"
name="new_password"
>
</label>
<br>
<label>Confirm new password
<input
type="password"
placeholder="Type the new password again"
name="new_password_check"
>
</label>
<br>
<button type="submit">Change password</button>
</form>
<p><a href="/admin/dashboard"><- Back</a></p>
</body>
</html>"#,
))
}
//! src/routes/admin/password/post.rs
use actix_web::{HttpResponse, web};
use secrecy::SecretString;
#[derive(serde::Deserialize)]
pub struct FormData {
current_password: SecretString,
new_password: SecretString,
new_password_check: SecretString,
}
pub async fn change_password(form: web::Form<FormData>) -> Result<HttpResponse, actix_web::Error> {
todo!()
}
//! src/startup.rs
// [...]
async fn run(
// [...]
) -> Result<Server, anyhow::Error> {
// [...]
let server = HttpServer::new(move || {
App::new()
// [...]
.route("/admin/password", web::get().to(change_password_form))
.route("/admin/password", web::post().to(change_password))
// [...]
})
// [...]
}
就像管理面板本身一样,我们不想向未登录的用户显示更改密码的表单。
让我们添加两个集成测试:
//! tests/api/main.rs
mod change_password;
// [...]
//! tests/api/helpers.rs
// [...]
impl TestApp {
pub async fn get_change_password(&self) -> reqwest::Response {
self.api_client
.get(format!("{}/admin/password", &self.address))
.send()
.await
.expect("Failed t execute request.")
}
pub async fn post_change_password<Body>(&self, body: &Body) -> reqwest::Response
where
Body: serde::Serialize,
{
self.api_client
.post(format!("{}/admin/password", &self.address))
.form(body)
.send()
.await
.expect("Failed to execute request")
}
// [...]
}
//! tests/api/change_password.rs
use uuid::Uuid;
use crate::helpers::{assert_is_redirect_to, spawn_app};
#[tokio::test]
async fn you_must_be_logged_in_to_see_the_change_password_form() {
// Arrange
let app = spawn_app().await;
// Act
let response = app.get_change_password().await;
// Assert
assert_is_redirect_to(&response, "/login");
}
#[tokio::test]
async fn you_must_br_logged_in_to_change_your_password() {
// Arrange
let app = spawn_app().await;
let new_password = Uuid::new_v4().to_string();
// Act
let response = app
.post_change_password(&serde_json::json!({
"current_password": Uuid::new_v4().to_string(),
"new_password": &new_password,
"new_password_check": &new_password,
}))
.await;
// Assert
assert_is_redirect_to(&response, "/login");
}
然后我们可以通过在请求处理程序中添加检查来满足要求:
//! src/routes/admin/password/get.rs
use crate::session_state::TypedSession;
use crate::utils::{e500, see_other};
// [...]
use actix_web::{HttpResponse, http::header::ContentType};
use crate::session_state::TypedSession;
use crate::utils::{e500, see_other};
pub async fn change_password_form(session: TypedSession) -> Result<HttpResponse, actix_web::Error> {
if session.get_user_id().map_err(e500)?.is_none() {
return Ok(see_other("/login"));
}
Ok(/* */)
}
//! src/routes/admin/password/post.rs
use crate::session_state::TypedSession;
use crate::utils::{e500, see_other};
// [...]
pub async fn change_password(
form: web::Form<FormData>,
session: TypedSession,
) -> Result<HttpResponse, actix_web::Error> {
if session.get_user_id().map_err(e500)?.is_none() {
return Ok(see_other("/login"));
}
todo!()
}
//! src/utils.rs
use actix_web::{HttpResponse, http::header::LOCATION};
// Return an opaque 500 while preserving the error's root cause for logging.
pub fn e500<T>(e: T) -> actix_web::Error
where
T: std::fmt::Debug + std::fmt::Display + 'static,
{
actix_web::error::ErrorInternalServerError(e)
}
pub fn see_other(location: &str) -> HttpResponse {
HttpResponse::SeeOther()
.insert_header((LOCATION, location))
.finish()
}
//! src/lib.rs
// [...]
pub mod utils;
//! src/routes/admin/dashboard.rs
// The definitation of e500 has been moved to sec/utils.rs
use crate::utils::e500;
// [...]
我们也不希望密码修改表单变成一个孤立页面——让我们在管理面板中添加一个可用操作列表 以及指向新页面的链接:
//! src/routes/admin/dashboard.rs
// [...]
pub async fn admin_dashboard(/* */) -> Result</* */> {
// [...]
Ok(HttpResponse::Ok()
.content_type(ContentType::html())
.body(format!(
r#"<!DOCTYPE html>
<html lang="en">
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<title>Admin dashboard</title>
</head>
<body>
<p>Welcome {username}!</p>
<p>Available actions:</p>
<ol>
<li><a href="/admin/password">Change password</a></li>
</ol>
</body>
</html>"#
)))
}
不愉快路径: 新密码不匹配
我们已经完成了所有准备工作,现在是时候开始开发核心功能了。
让我们先从一个不太理想的情况开始——我们要求用户输入两次新密码,但两次输入的密码不一致。我们希望用户能够重定向回表单,并显示相应的错误消息。
//! tests/api/change_password.rs
// [...]
#[tokio::test]
async fn new_password_fields_must_match() {
// Arrange
let app = spawn_app().await;
let new_password = Uuid::new_v4().to_string();
let another_new_password = Uuid::new_v4().to_string();
// Act - Part 1 - Login
app.post_login(&serde_json::json!({
"username": &app.test_user.username,
"password": &app.test_user.password,
}))
.await;
// Act - Part2 - Try to change password
let response = app
.post_change_password(&serde_json::json!({
"current_password" : &app.test_user.password,
"new_password": &new_password,
"new_password_check": &another_new_password,
}))
.await;
assert_is_redirect_to(&response, "/admin/password");
// Act - Part 3 - Follow the redirect
let html_page = app.get_change_password_html().await;
assert!(html_page.contains(
"<p><i>You entered two different new passwords - \
the field values must match.</i></p>"
));
}
//! tests/api/helpers.rs
// [...]
impl TestApp {
// [...]
pub async fn get_change_password_html(&self) -> String {
self.get_change_password().await.text().await.unwrap()
}
}
测试失败了,因为请求处理程序崩溃了。让我们修复它:
//! src/routes/admin/password/post.rs
use secrecy::ExposeSecret;
// [...]
pub async fn change_password(/* */) -> Result</* */> {
// [...]
// `SecretString` does not implement `Eq`
// therefore we need to compare the underlying `String`
if form.new_password.expose_secret() != form.new_password_check.expose_secret() {
return Ok(see_other("/admin/password"));
}
todo!()
}
这处理了重定向(测试的第一部分),但它不处理错误消息:
thread 'change_password::new_password_fields_must_match' panicked at tests/api/change_password.rs:63:5:
assertion failed: html_page.contains("...")
我们之前已经通过登录表单经历过这个过程 - 我们可以再次使用 flash message!
//! src/routes/admin/password/post.rs
// [...]
use actix_web_flash_messages::FlashMessage;
pub async fn change_password(/* */) -> Result</* */> {
// [...]
if form.new_password.expose_secret() != form.new_password_check.expose_secret() {
FlashMessage::error(
"You entered two different new passwords - the field values must match.",
)
.send();
// [...]
}
todo!()
}
//! src/routes/admin/password/get.rs
// [...]
use actix_web_flash_messages::IncomingFlashMessages;
use std::fmt::Write;
pub async fn change_password_form(
session: TypedSession,
flash_messages: IncomingFlashMessages,
) -> Result<HttpResponse, actix_web::Error> {
// [...]
let mut msg_html = String::new();
for m in flash_messages.iter() {
writeln!(msg_html, "<p><i>{}</i></p>", m.content()).unwrap();
}
Ok(HttpResponse::Ok()
.content_type(ContentType::html())
.body(format!(
r#"<!DOCTYPE html>
<html lang="en">
<!-- [...] -->
<body>
{msg_html}
<!-- [...] -->
</body>
</html>"#
)))
}
现在测试应该通过了
不愉快路径: 当前密码无效
您可能已经注意到,我们要求用户在表单中提供其当前密码。这是为了防止攻击者 成功获取有效会话令牌后锁定合法用户的帐户。
让我们添加一个集成测试,以指定当提供的当前密码无效时我们期望看到的内容:
//! tests/api/change_password.rs
// [...]
#[tokio::test]
async fn current_password_must_be_valid() {
// Arrange
let app = spawn_app().await;
let new_password = Uuid::new_v4().to_string();
let wrong_password = Uuid::new_v4().to_string();
// Act - Part 1 - Login
app.post_login(&serde_json::json!({
"username": &app.test_user.username,
"password": &app.test_user.password
}))
.await;
// Act - Part 2 - Try to change password
let response = app
.post_change_password(&serde_json::json!({
"current_password": &wrong_password,
"new_password": &new_password,
"new_password_check": &new_password
}))
.await;
// Assert
assert_is_redirect_to(&response, "/admin/password");
// Act - Part 3 - Follow the redirect
let html_page = app.get_change_password_html().await;
assert!(html_page.contains("<p><i>The current password is incorrect.</i></p>"));
}
为了验证 current_password 传递的值,我们需要检索用户名,然后调用 validate_credentials 例程,该例程负责我们的登录表单。
让我们从用户名开始:
//! src/routes/admin/password/post.rs
use crate::routes::admin::dashboard::get_username;
use sqlx::PgPool;
// [...]
pub async fn change_password(
// [...]
pool: web::Data<PgPool>,
session: TypedSession,
) -> Result<HttpResponse, actix_web::Error> {
let Some(user_id) = session.get_user_id().map_err(e500)? else {
return Ok(see_other("/login"));
};
if form.new_password.expose_secret() != form.new_password_check.expose_secret() {
// [...]
}
let username = get_username(user_id, &pool).await.map_err(e500)?;
todo!()
}
//! src/routes/admin/dashboard.rs
// [...]
#[tracing::instrument(/* */)]
// Marked as `pub`!
pub async fn get_username(/* */) -> Result</* */> {
// [...]
}
现在我们可以将用户名和密码组合传递给 validate_credentials - 如果验证失败,我们需要根据返回的错误采取不同的操作:
//! src/routes/admin/password/post.rs
// [...]
use crate::authentication::{validate_credentials, AuthError, Credentials};
pub async fn change_password(/* */) -> Result</* */> {
// [...]
let username = get_username(user_id, &pool).await.map_err(e500)?;
let credentials = Credentials {
username,
password: form.0.current_password,
};
if let Err(e) = validate_credentials(credentials, &pool).await {
return match e {
AuthError::InvalidCredentials(_) => {
FlashMessage::error("The current password is incorrect.").send();
Ok(see_other("/admin/password"))
}
AuthError::UnexpectedError(_) => Err(e500(e).into()),
};
}
todo!()
}
测试应该通过了
不愉快路径: 新密码太短
我们不希望用户选择强度较低的密码——这会将他们的账户暴露给攻击者。
OWASP 对密码强度提出了POST /admin/password——密码长度应大于 12 个字符,小于 128 个字符。
请将这些验证检查添加到我们的 POST /admin/password 端点,作为练习!
登出
现在终于到了看看完美路径的时候了——用户成功更改了密码。
我们将使用以下场景来检查一切是否按预期运行:
- 登录
- 通过提交密码更改表单来更改密码
- 注销
- 使用新密码重新登录
只剩下一个障碍——我们还没有注销端点!
在继续下一步之前,让我们先努力弥补这个功能上的差距。
首先,让我们在测试中编写我们的需求:
//! tests/api/admin_dashboard.rs
// [...]
// TODO: wip